
Tu empresa necesita un chatbot. Eso ya lo decidiste. La pregunta que te frena ahora es otra: ¿qué tipo de chatbot? Porque no todos los chatbots son iguales, y elegir mal te cuesta meses de implementación, frustración del equipo y —lo peor— clientes que se van sin respuesta.
En 2026, las opciones reales se reducen a tres enfoques: NLP tradicional (el bot entrenado con preguntas y respuestas), GPT / IA generativa (el que entiende y genera lenguaje natural con un modelo grande), y el híbrido (que combina ambos). Cada uno tiene trade-offs concretos en control, flexibilidad, costo y velocidad de implementación.
Esta guía compara los tres sin rodeos, con criterios reales de producción —no demos de laboratorio— para que puedas decidir cuál encaja en tu operación.
Tabla comparativa rápida
| Criterio | NLP tradicional | GPT / IA generativa | Híbrido |
|---|---|---|---|
| Precisión en respuestas conocidas | Excelente (determinístico) | Buena (depende del contexto) | Excelente |
| Manejo de preguntas inesperadas | Malo (no entiende lo que no entrenaste) | Excelente (genera respuestas naturales) | Excelente |
| Riesgo de "alucinaciones" | Cero | Alto sin guardrails | Bajo (controlado) |
| Costo por conversación | Bajo | Medio-alto (tokens LLM) | Medio |
| Tiempo de implementación | Medio (2-6 semanas) | Rápido (días con RAG) | Medio (3-6 semanas) |
| Mantenimiento | Alto (reentrenar continuamente) | Bajo (actualizar base de conocimiento) | Medio |
| Control sobre respuestas | Total | Limitado | Alto (donde importa) |
| Escalabilidad a nuevos temas | Lenta (entrenar por tema) | Rápida (agrega docs al RAG) | Rápida |
| Ideal para | Flujos predecibles, compliance | Conversación abierta, soporte L1 | Producción real, multi-caso |
Qué es un chatbot NLP tradicional
Un chatbot NLP (Natural Language Processing) funciona con un modelo de clasificación de intenciones. Lo entrenas con pares de preguntas y respuestas: "¿cuál es el horario de atención?" → categoría horario → respuesta predefinida. Cuando un usuario escribe algo, el bot clasifica la intención y devuelve la respuesta asociada.
Cómo funciona por dentro
- Entrenamiento: le das 10-50 variaciones de la misma pregunta por intención ("horario de atención", "a qué hora abren", "están abiertos los domingos"). El modelo aprende a clasificar texto en esas intenciones.
- Matching: cuando llega un mensaje nuevo, el bot calcula la similitud con las intenciones entrenadas y elige la de mayor confianza.
- Respuesta: si la confianza supera un umbral (generalmente 70-85%), devuelve la respuesta predefinida. Si no, cae al fallback ("no entendí, ¿puedes reformular?").
Ventajas concretas
- Determinístico. La misma pregunta siempre da la misma respuesta. Eso importa cuando hay regulaciones, compliance o información sensible (precios, términos legales, disponibilidad de stock).
- Auditable. Puedes ver exactamente qué intención se activó, con qué confianza, y qué respuesta se dio. Debugging claro.
- Costo predecible. No pagas por tokens ni por llamadas a una API externa. El costo es fijo: hosting + mantenimiento del modelo.
- Funciona offline o en edge. No depende de una API de terceros para cada respuesta.
Limitaciones reales
- Rígido. Si un usuario formula la pregunta de una forma que no entrenaste, el bot no entiende. Y hay infinitas formas de preguntar lo mismo.
- Mantenimiento alto. Cada vez que aparece un tema nuevo (un producto, una promoción, un cambio de política), hay que crear nuevas intenciones, escribir variaciones, reentrenar y testear.
- Escalabilidad lenta. Pasar de 20 intenciones a 200 requiere semanas de trabajo de un bot builder dedicado.
- Conversación plana. No "entiende" contexto previo. Cada mensaje se clasifica independientemente. Si el usuario dice "¿y el precio?" después de preguntar por un producto, el bot no sabe a qué producto se refiere.
Cuándo elegir NLP puro
- Tienes menos de 30 intenciones bien definidas.
- Las respuestas no pueden variar (compliance, regulatorio, precios fijos).
- No quieres dependencia de APIs externas (GPT de OpenAI, Google, etc.).
- Tu equipo tiene un bot builder dedicado que puede mantener el entrenamiento.
Qué es un chatbot GPT / IA generativa
Un chatbot GPT (o basado en LLM — Large Language Model) no clasifica intenciones: entiende el lenguaje natural y genera respuestas originales para cada mensaje. Detrás hay un modelo como GPT-4, GPT-4o, Claude, Gemini o un modelo open-source.
Cómo funciona por dentro
- Prompt del sistema: le das instrucciones al modelo ("eres un asistente de atención al cliente de [empresa]. Tu tono es profesional. No inventes información que no esté en la base de conocimiento").
- Base de conocimiento (RAG): le adjuntas documentos con la información real de tu empresa — FAQs, manuales, precios, políticas. El modelo busca en estos documentos antes de responder (Retrieval-Augmented Generation).
- Generación: dado el mensaje del usuario + el contexto del RAG + el prompt del sistema, el modelo genera una respuesta en lenguaje natural, sin estar limitado a respuestas predefinidas.
Ventajas concretas
- Flexible. Entiende reformulaciones, errores de ortografía, mezcla de idiomas, preguntas complejas con múltiples partes. No necesitas entrenar variaciones.
- Conversacional. Mantiene contexto dentro de la conversación. Si el usuario pregunta por un producto y después dice "¿cuánto cuesta?", el modelo sabe a qué se refiere.
- Escalabilidad rápida. ¿Cambió el catálogo de productos? Actualizas el documento en el RAG. No hay que reentrenar nada.
- Implementación rápida. Con una buena base de conocimiento y un prompt afinado, puedes tener un bot funcional en días, no semanas.
Limitaciones reales
- Alucinaciones. El modelo puede inventar información que suena correcta pero es falsa. Sin guardrails, puede decirle al cliente que un producto está disponible cuando no lo está, o dar un precio incorrecto.
- Costo variable. Cada mensaje consume tokens de la API. En volúmenes altos (miles de conversaciones diarias), el costo escala. Un plan de GPT-4o puede sumar USD 200-500/mes solo en tokens para una operación mediana.
- Control limitado. No puedes garantizar que la respuesta sea exactamente X. Puedes guiar con prompts, pero la generación siempre tiene un grado de variabilidad.
- Latencia. La respuesta tarda 1-3 segundos (el modelo "piensa"). En canales sincrónicos como WhatsApp, el usuario nota la demora vs un bot NLP que responde en milisegundos.
- Dependencia de terceros. Si la API de OpenAI (o del proveedor que uses) tiene un outage, tu bot queda mudo.
Cuándo elegir GPT puro
- Tu base de conocimiento cambia frecuentemente (catálogos, precios, políticas).
- Las preguntas son abiertas y variadas (no caben en 30 intenciones fijas).
- Quieres implementar rápido (días, no semanas).
- El riesgo de una respuesta ligeramente imprecisa es tolerable (soporte L1, preguntas generales, no transacciones financieras).
Qué es un chatbot híbrido
El enfoque híbrido no es una tercera tecnología: es una arquitectura que combina NLP y GPT en la misma conversación, activando uno u otro según el contexto.
Cómo funciona por dentro
- Capa de entendimiento (GPT). El mensaje del usuario llega y el modelo generativo lo entiende en lenguaje natural, con todo su contexto conversacional.
- Router de decisión. Un sistema de reglas evalúa: ¿este tema requiere una respuesta determinística (precio, stock, estado de un pedido, dato regulatorio)? Si sí, pasa al módulo NLP. Si no, el GPT responde directamente desde la base de conocimiento.
- Capa NLP (rutas determinísticas). Para los casos donde la precisión es no negociable, las respuestas vienen de intenciones entrenadas: exactas, auditables, sin variación.
- Base de conocimiento (RAG). Ambas capas consultan la misma fuente de verdad: los documentos de tu empresa. El GPT para generar respuestas naturales, el NLP para validar datos puntuales.
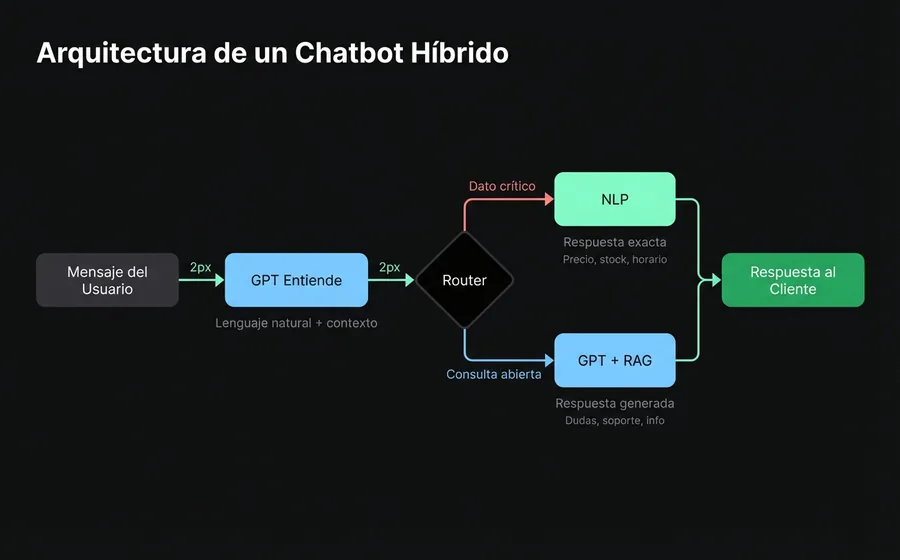
Ventajas concretas
- Lo mejor de ambos mundos. Flexibilidad conversacional del GPT donde no importa la precisión exacta, determinismo del NLP donde sí importa.
- Guardrails nativos. Las alucinaciones se contienen porque los datos críticos (precios, disponibilidad, horarios, estados de pedido) NUNCA pasan por generación libre — van por la ruta NLP.
- Experiencia de usuario superior. El cliente siente que habla con alguien que entiende (GPT), pero las respuestas de negocio son 100% confiables (NLP).
- Mantenimiento balanceado. Las intenciones NLP solo cubren los 15-30 casos críticos (no los 300 posibles), así que el mantenimiento es manejable. El GPT con RAG cubre el long tail sin entrenamiento adicional.
Limitaciones reales
- Complejidad de setup. Configurar el router (cuándo NLP, cuándo GPT) requiere pensamiento de diseño. No es plug & play.
- Costo de ambas capas. Pagas el hosting del modelo NLP + los tokens del GPT. Aunque en la práctica, como el NLP resuelve los casos frecuentes (que son los más baratos de resolver), el costo total suele ser menor que GPT puro.
- Debugging más complejo. Cuando algo falla, hay que saber si falló en la capa GPT o en la NLP. Requiere logs claros de qué ruta tomó cada conversación.
Cuándo elegir híbrido
- Tienes casos de uso mixtos: preguntas abiertas (soporte general) + consultas de datos concretos (precio, stock, estado).
- La precisión importa en algunos temas pero no en todos.
- Vas a escalar (empiezas con 20 intenciones NLP + GPT para el resto, y creces orgánicamente).
- Quieres control donde necesitas control y flexibilidad donde no.
Comparación detallada
Precisión y confiabilidad
| Escenario | NLP | GPT | Híbrido |
|---|---|---|---|
| "¿Cuánto cuesta el plan Business?" | Respuesta exacta: $20/mes | Probablemente correcta si está en el RAG, riesgo de error | Respuesta exacta (ruta NLP) |
| "Quiero entender cómo funciona la IA conversacional para mi negocio" | Fallback (no entrenado) | Respuesta natural y útil desde RAG | Respuesta natural (ruta GPT) |
| "Cancelar mi suscripción" | Ruta a agente o respuesta predefinida | Puede intentar resolver solo (riesgoso) | Ruta a agente (regla determinística) |
| "Hola, tengo un problema con un pedido que hice ayer" | Probable fallback | Pide más datos y escala | Pide datos (GPT), consulta CRM (NLP), responde |
El híbrido gana en escenarios mixtos porque no fuerza todas las conversaciones por el mismo canal.
Costo total de operación (TCO)
Para una operación de 2,000 conversaciones/mes con ~8 mensajes promedio por conversación:
| Componente | NLP | GPT | Híbrido |
|---|---|---|---|
| Plataforma base | USD 50-150/mes | USD 50-150/mes | USD 100-260/mes |
| Tokens LLM | $0 | USD 80-200/mes | USD 40-100/mes |
| Bot builder (mantenimiento) | 8-16 hrs/mes | 2-4 hrs/mes | 4-8 hrs/mes |
| Costo de errores (clientes perdidos) | Medio (fallbacks) | Alto (alucinaciones) | Bajo |
| TCO estimado | USD 150-350/mes | USD 200-450/mes | USD 200-400/mes |
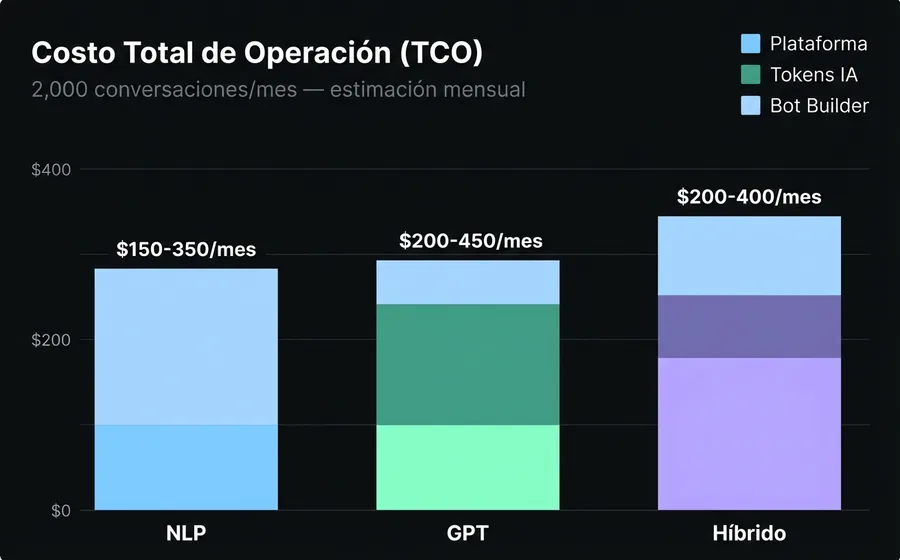
El NLP parece más barato hasta que cuentas las horas del bot builder y el costo de los fallbacks (clientes que no obtienen respuesta y se van). El GPT parece caro hasta que cuentas que no necesitas un bot builder full-time. El híbrido optimiza ambos lados.
Tiempo de implementación
| Fase | NLP | GPT | Híbrido |
|---|---|---|---|
| Setup inicial | 1-2 semanas | 2-5 días | 1-2 semanas |
| Entrenamiento / knowledge base | 2-4 semanas | 1-3 días | 1-2 semanas |
| Testing y ajuste | 1-2 semanas | 3-5 días | 1-2 semanas |
| Total | 4-8 semanas | 1-2 semanas | 3-6 semanas |
GPT gana en velocidad, pero "rápido de implementar" no significa "listo para producción". Un GPT mal configurado puesto en producción en 3 días puede hacer más daño que no tener bot.
Escalabilidad
- NLP: escalar = agregar intenciones, entrenar variaciones, testear. Crecimiento lineal con esfuerzo humano.
- GPT: escalar = agregar documentos al RAG. Crecimiento casi instantáneo.
- Híbrido: escalar el GPT (agregar docs) es rápido. Escalar las rutas NLP (nuevos datos críticos) es planificado. Crecimiento controlado.
Tres errores comunes al elegir
1. "GPT resuelve todo, no necesito NLP"
El error más caro de 2025-2026. Las empresas implementan GPT sin guardrails, y a las dos semanas descubren que el bot le dijo a un cliente que el producto tiene garantía de 5 años (no la tiene) o que el envío es gratis (no lo es). Una sola alucinación sobre precios o políticas puede costarte más que 6 meses de suscripción de la plataforma.
2. "NLP es más seguro, me quedo con eso"
Seguro sí, pero sordo. Un bot NLP que responde "no entendí" al 40% de las preguntas no es más seguro — es peor. Cada fallback es un cliente que se fue sin respuesta. La seguridad real es responder bien, no evitar responder.
3. "Implemento GPT ahora y después agrego NLP si hace falta"
La deuda técnica se acumula rápido. Si arrancas con GPT puro y después necesitas rutas determinísticas, vas a tener que refactorizar flujos, reentrenar, y recalibrar el router. Es más eficiente diseñar la arquitectura híbrida desde el día uno, aunque arranques con pocas rutas NLP.
Cómo se implementa cada enfoque en la práctica
NLP: el flujo típico
- Mapear los 20-50 motivos de contacto más frecuentes con el equipo de atención
- Redactar respuestas modelo para cada intención
- Escribir 10-30 variaciones de cada pregunta para entrenamiento
- Entrenar el modelo y calibrar umbrales de confianza
- Configurar fallbacks y escalamiento a agentes
- Testear con conversaciones reales y ajustar
- Repetir cada mes con nuevas intenciones
Plataformas como AsisteNLP simplifican este proceso con interfaces de entrenamiento visual y reentrenamiento continuo basado en conversaciones reales que el bot no supo resolver.
GPT: el flujo típico
- Recopilar la base de conocimiento (FAQs, manuales, políticas, catálogo)
- Configurar el prompt del sistema con tono, límites y reglas
- Implementar RAG: el modelo busca en tus documentos antes de responder
- Definir guardrails: qué NO puede decir el bot (disclaimers, temas prohibidos)
- Testear con edge cases (preguntas maliciosas, fuera de tema, en otros idiomas)
- Monitorear alucinaciones las primeras 2 semanas intensivamente
AsisteGPT ofrece este flujo con bases de conocimiento custom, prompts ocultos (el usuario no los ve) y RAG integrado, sin necesidad de código.
Híbrido: el flujo típico
- Fase GPT: cargar base de conocimiento y configurar prompt (3-5 días)
- Fase NLP: identificar los 10-20 casos donde la precisión es crítica y entrenar esas intenciones
- Configurar el router: definir las reglas de cuándo pasa al NLP y cuándo al GPT
- Integrar con CRM: las rutas NLP pueden consultar datos vivos (stock, pedidos, saldos) vía AsisteAPI
- Testear el handoff entre capas: ¿se siente natural la transición NLP↔GPT?
- Lanzar y monitorear ambas capas
La combinación de AsisteChat (bandeja omnicanal) + AsisteNLP (rutas determinísticas) + AsisteGPT (generación con RAG) es exactamente esta arquitectura. No es casualidad que sean módulos separados que se combinan: cada empresa puede activar solo lo que necesita y crecer desde NLP puro hacia híbrido sin migrar.
Preguntas frecuentes
¿Puedo empezar con NLP y agregar GPT después?
Sí, y es un camino común. Muchas empresas arrancan con 20-30 intenciones NLP para resolver los casos más frecuentes, y cuando el volumen crece y los fallbacks se acumulan, agregan GPT con RAG para cubrir el long tail. La clave es que tu plataforma soporte ambos desde el inicio para que la migración sea configuración, no reescritura.
¿GPT reemplaza al NLP?
No. GPT reemplaza al NLP en conversación abierta, pero no en respuestas que requieren precisión absoluta. Pensalo así: GPT es el generalista que sabe hablar de todo, NLP es el especialista que nunca se equivoca en su tema. Una buena operación necesita ambos.
¿Cuánto cuesta el GPT en tokens por mes?
Depende del modelo y el volumen. Para una operación de 2,000 conversaciones/mes con GPT-4o mini, el costo en tokens ronda USD 40-80/mes. Con GPT-4o completo, USD 150-300/mes. Los modelos más económicos (GPT-3.5 turbo, Claude Haiku) pueden bajar a USD 15-30/mes con calidad aceptable para soporte L1.
¿El enfoque híbrido es más difícil de mantener?
Es más complejo de configurar inicialmente, pero más fácil de mantener a largo plazo. El NLP puro requiere reentrenar cada vez que aparece un tema nuevo. El GPT puro requiere monitorear alucinaciones continuamente. El híbrido reduce ambas cargas: el GPT se autoactualiza con nuevos docs, y las rutas NLP solo cubren los casos críticos (pocos, estables).
¿Qué pasa con la privacidad de los datos si uso GPT?
Los datos de las conversaciones pasan por la API del proveedor del LLM (OpenAI, Anthropic, Google, etc.). La mayoría ofrece contratos de procesamiento de datos (DPA) y opciones de no entrenamiento. Si tu empresa maneja datos sensibles (salud, finanzas), verifica que el proveedor cumpla con la regulación de tu país. Algunas plataformas permiten usar modelos on-premise o en tu propio cloud para evitar que los datos salgan de tu infraestructura.
Veredicto
Si tuviéramos que resumir la decisión en una oración:
- Elige NLP si tus conversaciones son predecibles, reguladas, y tienes un bot builder dedicado.
- Elige GPT si necesitas velocidad de implementación, tus preguntas son variadas, y el riesgo de una respuesta imprecisa es tolerable.
- Elige híbrido si vas a producción real, con casos mixtos, donde algunos errores son caros y otros son aceptables.
La verdad incómoda es que la mayoría de las empresas que empiezan con NLP puro o GPT puro terminan migrando a híbrido dentro de los primeros 6 meses. El NLP puro se queda corto cuando el volumen crece. El GPT puro se vuelve riesgoso cuando un error le cuesta plata. El híbrido es donde converge la industria.
Si tu plataforma actual solo soporta uno de los dos enfoques, vas a tener que migrar cuando necesites el otro. Elegir una plataforma que soporte NLP, GPT y la combinación desde el inicio — como Bruno, con AsisteNLP + AsisteGPT + AsisteCopilot como módulos combinables — te ahorra esa migración y te da flexibilidad para crecer al ritmo de tu operación, no al ritmo de tu proveedor.
Sigue leyendo
- Cómo Peugeot Belchamp transformó su estrategia de leads con AsisteClick — un caso real de implementación híbrida con resultados cuantificados