
Your company needs a chatbot. You've already decided that. The question holding you back now is another: what type of chatbot? Because not all chatbots are the same, and choosing incorrectly costs you months of implementation, team frustration, and—worst of all—customers leaving without an answer.
In 2026, the real options narrow down to three approaches: Traditional NLP (the bot trained with questions and answers), GPT / Generative AI (the one that understands and generates natural language with a large model), and the hybrid (which combines both). Each has concrete trade-offs in control, flexibility, cost, and implementation speed.
This guide compares all three directly, with real production criteria—not lab demos—so you can decide which fits your operation.
Quick Comparison Table
| Criterion | Traditional NLP | GPT / Generative AI | Hybrid |
|---|---|---|---|
| Accuracy in known responses | Excellent (deterministic) | Good (context-dependent) | Excellent |
| Handling unexpected questions | Poor (does not understand what it wasn't trained on) | Excellent (generates natural responses) | Excellent |
| Risk of "hallucinations" | Zero | High without guardrails | Low (controlled) |
| Cost per conversation | Low | Medium-high (LLM tokens) | Medium |
| Implementation time | Medium (2-6 weeks) | Fast (days with RAG) | Medium (3-6 weeks) |
| Maintenance | High (continuous retraining) | Low (update knowledge base) | Medium |
| Control over responses | Total | Limited | High (where it matters) |
| Scalability to new topics | Slow (train per topic) | Fast (add docs to RAG) | Fast |
| Ideal for | Predictable flows, compliance | Open conversation, L1 support | Real production, multi-case |
What is a traditional NLP chatbot
An NLP (Natural Language Processing) chatbot works with an intent classification model. You train it with question-and-answer pairs: "what are the business hours?" → category horario → predefined response. When a user types something, the bot classifies the intent and returns the associated response.
How it works internally
- Training: you provide 10-50 variations of the same question per intent ("business hours", "what time do you open", "are you open on Sundays"). The model learns to classify text into those intents.
- Matching: when a new message arrives, the bot calculates the similarity with the trained intentions and chooses the one with the highest confidence.
- Response: if the confidence exceeds a threshold (generally 70-85%), it returns the predefined response. If not, it falls back to the fallback ("I didn't understand, can you rephrase?").
Concrete advantages
- Deterministic. The same question always yields the same answer. This is important when there are regulations, compliance, or sensitive information (prices, legal terms, stock availability).
- Auditable. You can see exactly which intention was activated, with what confidence, and what response was given. Clear debugging.
- Predictable Cost. You don't pay for tokens or calls to an external API. The cost is fixed: hosting + model maintenance.
- Works offline or at the edge. It does not depend on a third-party API for each response.
Real limitations
- Rigid. If a user formulates the question in a way you haven't trained, the bot doesn't understand. And there are infinite ways to ask the same thing.
- High Maintenance. Every time a new topic appears (a product, a promotion, a policy change), new intentions must be created, variations written, retrained, and tested.
- Slow Scalability. Moving from 20 intentions to 200 requires weeks of work from a dedicated bot builder.
- Flat Conversation. It does not "understand" previous context. Each message is classified independently. If the user says "and the price?" after asking about a product, the bot doesn't know which product they are referring to.
When to choose pure NLP
- You have fewer than 30 intentions well-defined.
- The responses cannot vary (compliance, regulatory, fixed prices).
- You don't want dependence on external APIs (GPT from OpenAI, Google, etc.).
- Your team has a bot builder dedicated that can maintain the training.
What is a GPT chatbot / generative AI
A GPT chatbot (or LLM-based — Large Language Model) does not classify intentions: understands natural language and generates original responses for each message. Behind it is a model like GPT-4, GPT-4o, Claude, Gemini, or an open-source model.
How it works internally
- System prompt: you give instructions to the model ("you are a customer support assistant for [company]. Your tone is professional. Do not invent information that is not in the knowledge base").
- Knowledge base (RAG): you attach documents with your company's real information — FAQs, manuals, prices, policies. The model searches these documents before responding (Retrieval-Augmented Generation).
- Generation: given the user's message + the RAG context + the system prompt, the model generates a response in natural language, without being limited to predefined responses.
Concrete advantages
- Flexible. Understands reformulations, spelling errors, language mixing, complex multi-part questions. You don't need to train variations.
- Conversational. Maintains context within the conversation. If the user asks about a product and then says "how much does it cost?", the model knows what they are referring to.
- Rapid scalability. Did the product catalog change? You update the document in the RAG. No retraining is needed.
- Rapid implementation. With a good knowledge base and a fine-tuned prompt, you can have a functional bot in days, not weeks.
Real limitations
- Hallucinations. The model can invent information that sounds correct but is false. Without guardrails, it can tell the customer that a product is available when it is not, or give an incorrect price.
- Variable cost. Each message consumes API tokens. At high volumes (thousands of daily conversations), the cost scales. A GPT-4o plan can add USD 200-500/month just in tokens for a medium-sized operation.
- Limited control. You cannot guarantee that the answer will be exactly X. You can guide with prompts, but generation always has a degree of variability.
- Latency. The response takes 1-3 seconds (the model "thinks"). In synchronous channels like WhatsApp, the user notices the delay versus an NLP bot that responds in milliseconds.
- Third-party dependency. If OpenAI's API (or the provider you use) has an outage, your bot goes silent.
When to choose pure GPT
- Your knowledge base changes frequently (catalogs, prices, policies).
- Questions are open-ended and varied (do not fit into 30 fixed intents).
- You want to implement quickly (days, not weeks).
- The risk of a slightly imprecise answer is tolerable (L1 support, general questions, not financial transactions).
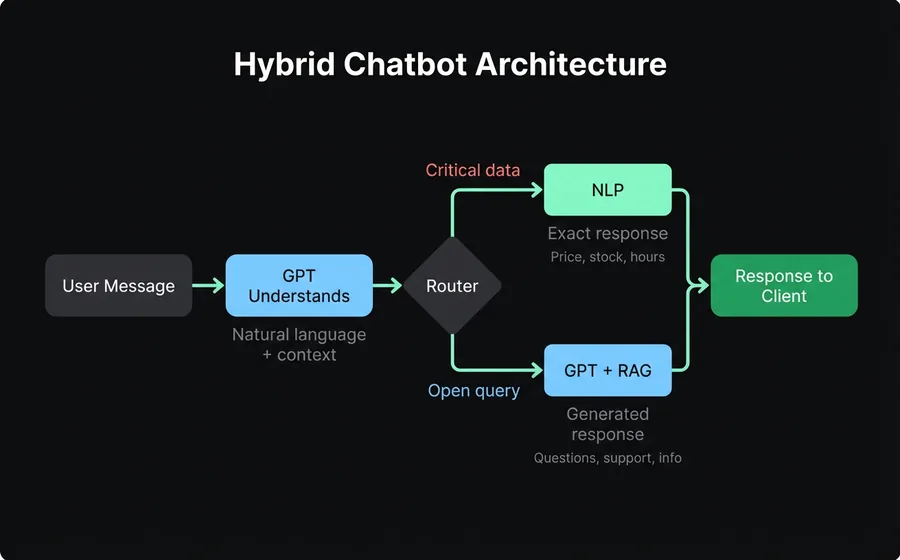
What is a hybrid chatbot
The hybrid approach is not a third technology: it is an architecture that combines NLP and GPT in the same conversation, activating one or the other depending on the context.
How it works internally
- Understanding layer (GPT). The user's message arrives and the generative model understands it in natural language, with all its conversational context.
- Decision router. A system of rules evaluates: does this topic require a deterministic answer (price, stock, order status, regulatory data)? If yes, it passes to the NLP module. If not, the GPT responds directly from the knowledge base.
- NLP layer (deterministic routes). For cases where precision is non-negotiable, answers come from trained intents: exact, auditable, without variation.
- Knowledge base (RAG). Both layers consult the same source of truth: your company's documents. The GPT to generate natural responses, the NLP to validate specific data.
Concrete advantages
- The best of both worlds. Conversational flexibility of GPT where exact precision doesn't matter, determinism of NLP where it does.
- Native guardrails. Hallucinations are contained because critical data (prices, availability, schedules, order statuses) NEVER go through free generation — they go through the NLP route.
- Superior user experience. The customer feels like they're talking to someone who understands (GPT), but business responses are 100% reliable (NLP).
- Balanced maintenance. NLP intents only cover the 15-30 critical cases (not the 300 possible ones), so maintenance is manageable. GPT with RAG covers the long tail without additional training.
Real limitations
- Setup complexity. Configuring the router (when NLP, when GPT) requires design thinking. It's not plug & play.
- Cost of both layers. You pay for the NLP model hosting + GPT tokens. Although in practice, since NLP resolves frequent cases (which are the cheapest to resolve), the total cost is usually lower than pure GPT.
- More complex debugging. When something fails, you need to know if it failed in the GPT layer or the NLP layer. It requires clear logs of which route each conversation took.
When to choose hybrid
- You have mixed use cases: open-ended questions (general support) + concrete data queries (price, stock, status).
- Accuracy matters on some topics but not all.
- You will scale (starting with 20 NLP intents + GPT for the rest, and growing organically).
- You want control where you need control and flexibility where not needed.
Detailed comparison
Accuracy and reliability
| Scenario | NLP | GPT | Hybrid |
|---|---|---|---|
| "How much does the Business plan cost?" | Exact answer: $20/month | Probably correct if in the RAG, risk of error | Exact answer (NLP route) |
| "I want to understand how conversational AI works for my business" | Fallback (untrained) | Natural and helpful answer from RAG | Natural answer (GPT route) |
| "Cancel my subscription" | Route to agent or predefined answer | Can try to resolve alone (risky) | Route to agent (deterministic rule) |
| "Hello, I have a problem with an order I placed yesterday" | Probable fallback | Requests more data and escalates | Requests data (GPT), consults CRM (NLP), responds |
The hybrid wins in mixed scenarios because it doesn't force all conversations through the same channel.
Total Cost of Ownership (TCO)
For an operation of 2,000 conversations/month with ~8 average messages per conversation:
| Component | NLP | GPT | Hybrid |
|---|---|---|---|
| Base platform | USD 50-150/month | USD 50-150/month | USD 100-260/month |
| LLM Tokens | $0 | USD 80-200/month | USD 40-100/month |
| Bot builder (maintenance) | 8-16 hrs/month | 2-4 hrs/month | 4-8 hrs/month |
| Cost of errors (lost customers) | Medium (fallbacks) | High (hallucinations) | Low |
| Estimated TCO | USD 150-350/month | USD 200-450/month | USD 200-400/month |
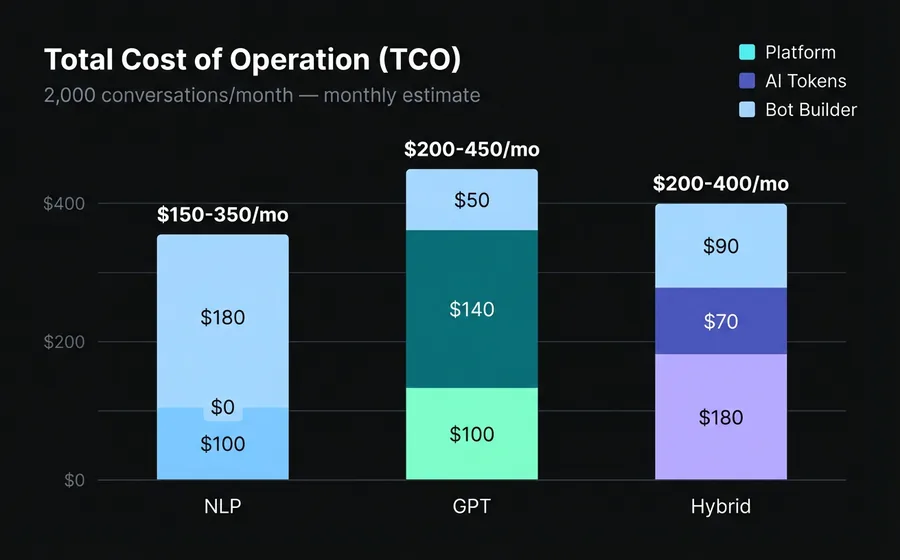
NLP seems cheaper until you account for bot builder hours and the cost of fallbacks (customers who don't get a response and leave). GPT seems expensive until you account for not needing a full-time bot builder. The hybrid optimizes both sides.
Implementation time
| Phase | NLP | GPT | Hybrid |
|---|---|---|---|
| Initial setup | 1-2 weeks | 2-5 days | 1-2 weeks |
| Training / knowledge base | 2-4 weeks | 1-3 days | 1-2 weeks |
| Testing and adjustment | 1-2 weeks | 3-5 days | 1-2 weeks |
| Total | 4-8 weeks | 1-2 weeks | 3-6 weeks |
GPT wins in speed, but "quick to implement" does not mean "production-ready". A poorly configured GPT put into production in 3 days can do more harm than not having a bot.
Scalability
- NLP: scale = add intents, train variations, test. Linear growth with human effort.
- GPT: scale = add documents to the RAG. Almost instant growth.
- Hybrid: scaling the GPT (adding docs) is fast. Scaling NLP routes (new critical data) is planned. Controlled growth.
Three common mistakes when choosing
1. "GPT solves everything, I don't need NLP"
The most expensive mistake of 2025-2026. Companies implement GPT without guardrails, and within two weeks, they discover that the bot told a customer the product has a 5-year warranty (it doesn't) or that shipping is free (it isn't). A single hallucination about prices or policies can cost you more than 6 months of platform subscription.
2. "NLP is safer, I'll stick with that"
Safe, yes, but deaf. An NLP bot that responds "I didn't understand" to 40% of questions is not safer — it's worse. Every fallback is a customer who left without an answer. Real safety is answering well, not avoiding answering.
3. "I'll implement GPT now and add NLP later if needed"
Technical debt accumulates quickly. If you start with pure GPT and later need deterministic routes, you'll have to refactor flows, retrain, and recalibrate the router. It's more efficient to design the hybrid architecture from day one, even if you start with few NLP routes.
How each approach is implemented in practice
NLP: the typical flow
- Map the 20-50 most frequent contact reasons with the support team
- Draft model responses for each intent
- Write 10-30 variations of each question for training
- Train the model and calibrate confidence thresholds
- Configure fallbacks and escalation to agents
- Test with real conversations and adjust
- Repeat monthly with new intentions
Platforms like AsisteNLP simplify this process with visual training interfaces and continuous retraining based on real conversations that the bot could not resolve.
GPT: the typical flow
- Gather the knowledge base (FAQs, manuals, policies, catalog)
- Configure the system prompt with tone, limits, and rules
- Implement RAG: the model searches your documents before responding
- Define guardrails: what the bot CANNOT say (disclaimers, prohibited topics)
- Test with edge cases (malicious, off-topic, or foreign language questions)
- Monitor hallucinations intensively for the first 2 weeks
AsisteGPT offers this flow with custom knowledge bases, hidden prompts (the user does not see them), and integrated RAG, without the need for code.
Hybrid: the typical flow
- GPT Phase: load knowledge base and configure prompt (3-5 days)
- NLP Phase: identify the 10-20 cases where precision is critical and train those intentions
- Configure the router: define the rules for when to pass to NLP and when to pass to GPT
- Integrate with CRM: NLP routes can query live data (stock, orders, balances) via AsisteAPI
- Test the handoff between layers: does the NLP↔GPT transition feel natural?
- Launch and monitor both layers
The combination of AsisteChat (omnichannel inbox) + AsisteNLP (deterministic routes) + AsisteGPT (generation with RAG) is exactly this architecture. It is no coincidence that they are separate modules that combine: each company can activate only what it needs and grow from pure NLP to hybrid without migrating.
Frequently asked questions
Can I start with NLP and add GPT later?
Yes, and it's a common path. Many companies start with 20-30 NLP intentions to resolve the most frequent cases, and when volume grows and fallbacks accumulate, they add GPT with RAG to cover the long tail. The key is that your platform supports both from the start so that migration is configuration, not rewriting.
Does GPT replace NLP?
No. GPT replaces NLP in open conversation, but not in responses that require absolute precision. Think of it this way: GPT is the generalist who can talk about everything, NLP is the specialist who never makes a mistake in their field. A good operation needs both.
How much does GPT cost in tokens per month?
It depends on the model and volume. For an operation of 2,000 conversations/month with GPT-4o mini, the cost in tokens is around USD 40-80/month. With full GPT-4o, USD 150-300/month. More economical models (GPT-3.5 turbo, Claude Haiku) can go down to USD 15-30/month with acceptable quality for L1 support.
Is the hybrid approach more difficult to maintain?
It's more complex to set up initially, but easier to maintain in the long run. Pure NLP requires retraining every time a new topic appears. Pure GPT requires continuous monitoring for hallucinations. The hybrid approach reduces both burdens: GPT self-updates with new docs, and NLP routes only cover critical cases (few, stable).
What about data privacy if I use GPT?
Conversation data passes through the LLM provider's API (OpenAI, Anthropic, Google, etc.). Most offer data processing agreements (DPA) and non-training options. If your company handles sensitive data (health, finance), verify that the provider complies with your country's regulations. Some platforms allow using on-premise models or models in your own cloud to prevent data from leaving your infrastructure.
Verdict
If we had to summarize the decision in one sentence:
- Choose NLP if your conversations are predictable, regulated, and you have a dedicated bot builder.
- Choose GPT if you need implementation speed, your questions are varied, and the risk of an imprecise answer is tolerable.
- Choose hybrid if you are going into real production, with mixed cases, where some errors are costly and others are acceptable.
The uncomfortable truth is that most companies that start with pure NLP or pure GPT end up migrating to hybrid within the first 6 months. Pure NLP falls short when volume grows. Pure GPT becomes risky when an error costs money. Hybrid is where the industry converges.
If your current platform only supports one of the two approaches, you will have to migrate when you need the other. Choosing a platform that supports NLP, GPT, and the combination from the start — like Bruno, with AsisteNLP + AsisteGPT + AsisteCopilot as combinable modules — saves you that migration and gives you the flexibility to grow at the pace of your operation, not at the pace of your provider.
Keep reading
- How Peugeot Belchamp transformed its lead strategy with AsisteClick — a real case of hybrid implementation with quantified results