
A maioria das plataformas de atendimento ao cliente que você conheceu tem um problema de design que só fica evidente quando você escala: tratam toda a equipe como se fossem a mesma coisa. Um "agente" é o bot, o humano novo que entrou ontem, o supervisor que olha relatórios e o dono que configura as regras. Todos podem ver tudo, todos podem fazer tudo, e ninguém tem clareza de onde termina sua responsabilidade. Quando sua operação tem 200 chats por dia, isso funciona. Quando tem 5.000, quebra.
O modelo que funciona em operações reais —o que vemos em clientes de bancos, ISP, varejo e saúde que processam dezenas de milhares de conversas por mês— distingue três papéis operacionais com responsabilidades, permissões e métricas diferentes. Agentes e colaboradores não são sinônimos, e o Agente de IA também não é "mais um agente". Cada um entra em um momento diferente do ciclo, mede coisas diferentes e custa coisas diferentes.
Neste post você vai aprender:
- Por que este modelo de 3 papéis existe e que problema resolve frente às soluções tradicionais onde "todos são agentes".
- Quando cada papel entra no ciclo de vida de uma conversa.
- Como projetar o handoff entre o Agente de IA e o humano sem matar a deflection rate do bot.
- Que métricas cada papel mede —porque medir response time de um Agente de IA ou deflection de um humano não faz sentido.
- Como configurar este modelo passo a passo no AsisteClick.
- Um caso aplicado real de um ISP regional que passou de 5 pessoas atendendo em horário comercial para uma operação 24/7 com 3 papéis bem definidos.
Se você já tem tempo em atendimento ao cliente, provavelmente intui parte disso. A ideia aqui não é te vender o modelo —é te dar o vocabulário e a arquitetura para que sua operação deixe de depender da memória do seu melhor agente. Vamos começar.
Por que existe o modelo de 3 papéis (e o que ele substitui)
As ferramentas que não diferenciam papéis vêm de uma época em que "atendimento ao cliente" era uma pessoa em um telefone. Quando essa pessoa passou a estar em um chat, a metáfora se manteve: cada chat é uma ligação, cada funcionário é um agente. Essa metáfora funcionou enquanto o volume foi gerenciável e enquanto não havia IA generativa no meio.
Hoje há duas mudanças estruturais que quebram o modelo antigo:
- O Agente de IA já não é um menu de botões. Uma IA generativa com acesso à sua base de conhecimento pode resolver 60-75% das consultas sem intervenção humana, se estiver bem projetada. Tratá-la como "mais um canal" ou como "um bot que precede o humano" subutiliza o investimento.
- A equipe humana já não é homogênea. Você tem pessoas que só respondem chats atribuídos (junior, terceiro turno, freelancer externo) e pessoas que além disso supervisionam, configuram o bot, olham relatórios e reatribuem casos. Dar a elas as mesmas permissões é um risco operacional e um custo desnecessário.
O modelo de 3 papéis operacionais separa estas três funções:
- O Agente de IA atende primeiro e absorve o volume repetitivo.
- O Colaborador atende os chats que lhe são atribuídos, sem mais permissões do que precisa.
- O Operador (ou agente humano completo) supervisiona, configura, mede e opera a plataforma como dono.
Essa separação não é teoria —é o que vemos funcionar em operações de mais de 10.000 chats por mês. E a diferença entre Operador e Colaborador, que é a que mais confunde, é de visibilidade e permissões, não de capacidade de conversar com um cliente. Ambos podem atender. Apenas um pode ver todo o resto.
O que cada um faz: os 3 papéis explicados
O Agente de IA: primeira linha, 24/7, custo marginal zero
O Agente de IA é o primeiro contato que seu cliente tem quando inicia uma conversa. Funciona 24/7, não tem fila de espera, atende N conversas em paralelo e não se cansa. O que distingue um Agente de IA bem projetado de um chatbot de regras é que entende linguagem natural e se apoia em uma base de conhecimento curada —não apenas em uma árvore de decisões predefinida.
Na prática, um Agente de IA bem montado:
- Responde perguntas frequentes com informação atualizada da sua base de conhecimento (produtos, planos, horários, cobertura, políticas).
- Executa ações simples via integração com seu CRM ou backend (consultar o status de um pedido, uma fatura, um ticket).
- Pede a informação mínima necessária ao cliente antes de transferir (CPF, número da conta, motivo).
- Sabe quando não sabe —e isso é o mais importante— e transfere para o humano correto sem perder contexto.
Se você tem interesse em entender como se monta a base de conhecimento que alimenta um Agente de IA, cobrimos isso a fundo em as três camadas de conhecimento de um Agente de IA. E se você se pergunta por que muitas implementações de IA falham, a resposta mais frequente —que também analisamos em por que os Agentes de IA fracassam no atendimento ao cliente— quase nunca é o modelo. É o design do handoff.
O Operador (agente humano completo): visibilidade total
O Operador é o papel humano com acesso completo à plataforma. É o papel do supervisor de turno, do coordenador de equipe, do dono da operação ou do agente sênior que, além de atender chats, faz gestão.
Um Operador pode:
- Atender chats (como qualquer humano da equipe).
- Ver o monitor em tempo real de todos os departamentos: quantos chats em fila, quantos em atendimento, quantos sem atribuição.
- Reatribuir chats entre agentes e departamentos.
- Acessar relatórios históricos e dashboards.
- Configurar bots, departamentos, regras de atribuição e horários.
- Ver a conversa completa de qualquer chat arquivado.
- Administrar usuários e permissões.
No AsisteClick, cada Operador adicional custa US$15/mês. Isso não é um detalhe de pricing irrelevante: é o custo que filtra quantos Operadores você realmente precisa. Se você vai dar a alguém permissões para reatribuir chats, olhar relatórios e configurar bots, provavelmente quer que sejam poucas pessoas e com responsabilidade clara. Se você só precisa que essa pessoa atenda chats, ela não precisa ser Operador.
O Colaborador: acesso limitado, responsabilidade clara
O Colaborador é o papel humano com permissões restritas. Só vê os chats atribuídos a ele e aos departamentos aos quais pertence. Não acessa relatórios, não configura bots, não vê a operação global, não pode reatribuir o que não é seu.
Um Colaborador pode:
- Atender os chats que lhe são atribuídos automaticamente ou que ele pega da fila do seu departamento.
- Ver o histórico do cliente com quem está conversando.
- Marcar o chat como resolvido e arquivá-lo.
- Pertencer a um ou vários departamentos (por exemplo, alguém do Suporte que também ajuda em Vendas no horário de pico).
O que não um Colaborador pode fazer:
- Ver chats que não são seus nem dos seus departamentos.
- Acessar o monitor global da operação.
- Olhar relatórios e dashboards.
- Configurar nada da plataforma.
- Administrar usuários.
Os Colaboradores vêm incluídos em cada plano do AsisteClick: 3 no Business, 5 no Company, 7 no AI Plus. Você não paga a mais por eles. Essa diferença de pricing —o Operador custa, o Colaborador não— reflete exatamente o princípio de segurança de privilégios mínimos: cobramos quando há mais superfície de acesso.
Tabela comparativa: Operador vs Colaborador
Esta é a tabela que vale a pena memorizar, porque a confusão entre esses dois papéis é a fonte número um de erros de configuração:
| Critério | Operador (agente humano completo) | Colaborador |
|---|---|---|
| Conversar com clientes | Sim | Sim |
| Ver chats atribuídos a si mesmo | Sim | Sim |
| Ver chats do seu departamento | Sim | Sim |
| Ver chats de outros departamentos | Sim | Não |
| Monitor em tempo real global | Sim | Não |
| Reatribuir chats entre agentes | Sim | Não |
| Relatórios e dashboards | Sim | Não |
| Configurar bots e integrações | Sim | Não |
| Administrar usuários | Sim | Não |
| Acesso ao histórico completo | Sim | Apenas dos seus chats |
| Custo | US$15/mês adicional | Incluído no plano |
| Papel típico | Supervisor, coordenador, dono da operação | Atendimento frontline, externo, junior |
Se sua dúvida é "essa pessoa precisa ver o que os outros fazem?", a resposta determina o papel. Se a resposta é não, é Colaborador. Se a resposta é sim, é Operador.
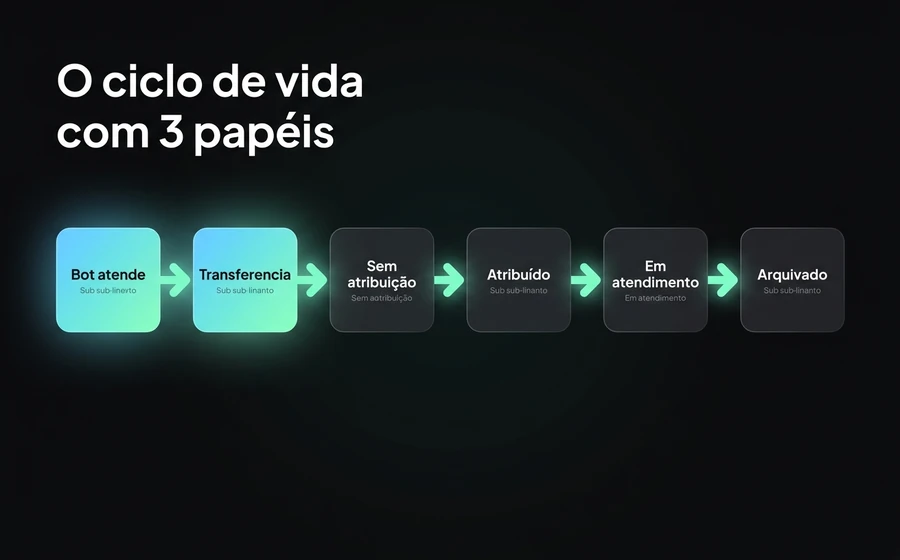
O ciclo de vida de uma conversa com 3 papéis
Uma conversa no AsisteChat —a caixa de entrada omnicanal onde convivem os 3 papéis— passa por 6 estados. Isso importa porque cada estado tem um "dono" diferente, e entender quem intervém em que momento é o que evita que os chats se percam pelo caminho. Para uma visão mais ampla de como funciona uma caixa de entrada unificada multicanal, você pode ver atendimento ao cliente omnicanal.
Passo 1 — Bot atende. O cliente inicia uma conversa por WhatsApp, webchat, Instagram, Facebook, email ou o canal que for. O Agente de IA assume a conversa. Cumprimenta, identifica o cliente se possível, entende o motivo. Se a consulta está dentro do seu alcance e ele tem confiança suficiente na sua resposta, resolve e arquiva a conversa. Aqui nenhum humano intervém.
Passo 2 — Transferência. Se o Agente de IA detecta que a consulta excede seu alcance (intent fora de scope, baixa confiança, sentimento negativo, pedido explícito de falar com humano), inicia a transferência. A transferência não é "vou te passar para um humano genérico" —é "vou te passar para o departamento correto": Vendas, Suporte, Cobranças, Retenção. Isso é o que evita que um cliente com uma reclamação de faturamento caia na fila do primeiro humano disponível mesmo que seja de Vendas.
Passo 3 — Não atribuído. O chat cai na fila "sem atribuição" do departamento correspondente. É aqui que o Operador supervisor pode ver o monitor em tempo real e reagir se a fila crescer. Os Colaboradores do departamento também veem essa fila e podem pegar chats manualmente.
Passo 4 — Atribuído. O chat é atribuído a um agente específico. A atribuição pode ser manual (um Operador o atribui, ou um Colaborador o pega da fila) ou automática (por carga, por regras, por rotação —vemos mais abaixo).
Passo 5 — Em atendimento. O agente atribuído (Operador ou Colaborador) está conversando com o cliente. Aqui, se você tem o AsisteCopilot ativo, o humano recebe sugestões em tempo real: rascunhos de resposta, consultas à base de conhecimento, resumos da conversa anterior. Isso reduz o tempo de atendimento (AHT) sobretudo em perfis junior. Aprofundamos em AsisteCopilot: respostas em tempo real para agentes de IA.
Passo 6 — Arquivado. O agente marca a conversa como resolvida. O chat sai da caixa de entrada ativa e entra no histórico: fica disponível para busca, alimenta os relatórios e faz parte do CSAT (se você ativou a pesquisa pós-atendimento).
Neste ciclo, o Agente de IA intervém no passo 1 e 2. O Operador intervém em qualquer passo, sobretudo no 3 (supervisionar a fila) e no 4 (reatribuir se necessário). O Colaborador intervém do passo 4 ao 6, dentro do seu departamento. Cada um tem sua pista.
Quando o Agente de IA escala para o humano
Esta é a pergunta mais mal respondida em implementações de IA no atendimento ao cliente: quando o bot deixa de responder e passa para o humano? A resposta intuitiva —que é a errada— é "quando detectamos palavras-chave de queixa ou reclamação". Essa lógica é a que mata o ROI do Agente de IA, porque escala consultas que o bot poderia resolver perfeitamente.
Há 4 triggers reais que justificam um handoff:
1. Confiança baixa do modelo na sua resposta
O Agente de IA não devolve apenas uma resposta —devolve também um sinal de quão seguro está. Se está abaixo de um limiar (que se calibra no setup), não responde com informação possivelmente incorreta; transfere. Isso evita o pior cenário: que o bot dê uma resposta inventada com tom seguro (alucinação). A forma de baixar a frequência de baixa confiança não é relaxar o limiar —é melhorar a base de conhecimento, que é onde o Agente de IA encontra os fatos. Como se projeta um prompt e a base que o alimenta cobrimos em prompt engineering para chatbot de atendimento ao cliente.
2. Sentimento negativo sustentado
Se o cliente está frustrado, irritado, ou usa linguagem que sugere que a conversa está saindo dos trilhos, o Agente de IA transfere. "Sustentado" é a palavra-chave: uma palavra forte isolada não é trigger. Um padrão de várias intervenções com tom negativo sim.
3. Intent fora de scope
O cliente pede algo que o Agente de IA não foi treinado para fazer. Exemplo: seu Agente de IA cobre consultas de produtos e suporte técnico, mas o cliente pergunta sobre um cancelamento de serviço que requer validação com o backoffice. Isso é out-of-scope —e a resposta correta não é "tentar mesmo assim", é transferir.
4. Pedido explícito do cliente
O cliente diz "quero falar com uma pessoa", "me passa para um humano", "o bot não me ajuda". Sem negociar, sem insistir, sem pedir ao cliente que reformule. Transfere-se. Insistir aqui corrói a confiança mais do que qualquer outra coisa.
Antipadrão: escalar por keywords
Escalar por palavras-chave ("reclamação", "queixa", "problema") parece intuitivo e é a pior coisa que você pode fazer. Por quê? Porque um cliente que pergunta "como faço uma reclamação?" pode receber a resposta diretamente do Agente de IA se sua base de conhecimento tiver o processo. Se você escala isso para um humano, gasta 5-10 minutos de tempo humano em uma consulta que o bot resolve em 30 segundos. Faça isso em escala e você perde mais de 50% da economia potencial da implementação de IA.
A regra operacional: o Agente de IA escala pelo estado da conversa, não pelo conteúdo isolado da mensagem.
Antipadrões de handoff que matam a operação
Há cinco padrões que vemos repetidos em operações que depois reclamam de que "a IA não funciona". Não é a IA —é o handoff.
1. Escalar tudo para o humano por padrão. Configurar o bot para que apenas cumprimente e transfira. Mata o caso de uso por completo. Se a única coisa que o bot faz é dizer "olá, vou te passar para um agente", você não precisa de IA generativa.
2. Escalar para "fila geral" sem departamento. O cliente fica em uma fila única de "atendimento ao cliente" e cai com o primeiro humano livre, sem importar se sua consulta é de Vendas, Suporte ou Cobranças. Resultado: o humano tem que qualificar a consulta de novo e possivelmente reatribuir. Você perde o contexto que o bot já coletou.
3. Perder o contexto na transferência. O humano recebe o chat sem o resumo do que o cliente já disse ao bot. O cliente repete tudo. Isso é trivial de resolver: o handoff inclui contexto. Se sua plataforma não faz isso, é problema da plataforma.
4. Não marcar a diferença entre bot e humano. O cliente não sabe se está falando com a IA ou com um humano. Quando descobre, sente-se enganado. A regra simples: quando o handoff acontece, o cliente recebe uma mensagem clara ("Vou te passar para a Maria, do Suporte"). Transparência sempre.
5. Não medir o que acontece depois do handoff. Se você não mede quantos chats se resolvem depois de escalar para o humano (resolution rate pós-handoff), não sabe se seu handoff funciona ou se você só transfere o problema. Essa métrica te diz se o bot está transferindo bem (casos resolvíveis) ou mal (casos impossíveis que voltam a ser transferidos para o backoffice).
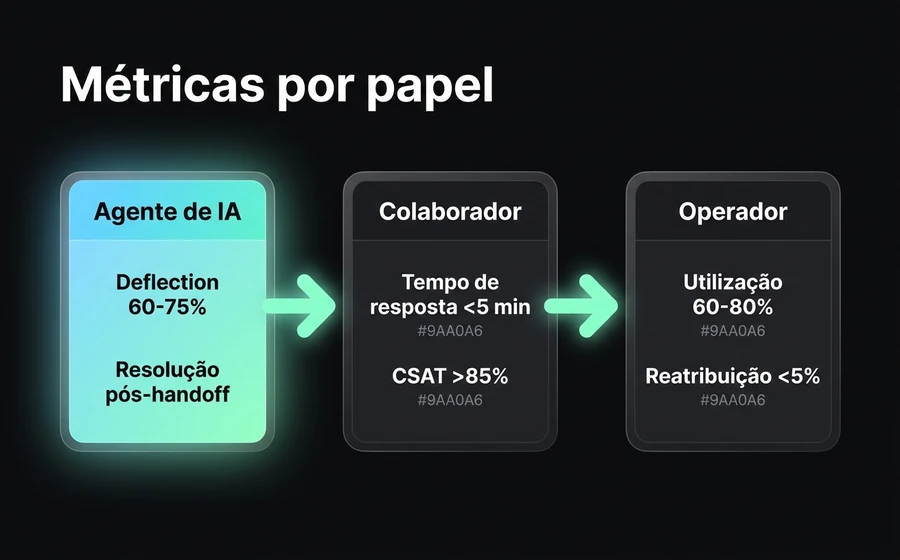
Métricas de governança por papel
Uma vez que você tem os 3 papéis funcionando, a pergunta é o que medir. Cada papel mede coisas diferentes —forçar as mesmas métricas nos 3 é o que leva a decisões ruins (penalizar o Agente de IA por response time, por exemplo, quando sua métrica real é deflection).
| Papel | Métrica-chave | Métrica secundária | Benchmark saudável |
|---|---|---|---|
| Agente de IA | Deflection rate (% de chats resolvidos sem escalar para humano) | Resolution rate pós-handoff (os que de fato escalou, foram resolvidos?) | 60-75% deflection em operações bem projetadas |
| Colaborador | Response time (primeira resposta após atribuição) | CSAT (satisfação do cliente ao encerrar) | <5 min response time WhatsApp; CSAT >85% |
| Operador | Utilization (% do tempo ativo atendendo ou supervisionando) | Volume reatribuído / total (sinal de roteamento ruim do bot) | 60-80% utilization; reatribuição <5% |
Três observações sobre esta tabela:
O Agente de IA não se mede por response time. Responde em menos de 2 segundos sempre. Medir isso é trivial e inútil. O que importa é quanto ele resolve sozinho —deflection— e, do que escala, quanto se resolve depois. Se seu Agente de IA tem 80% de deflection mas 50% do que escala volta a ser transferido para o backoffice, não funciona: filtrou mal.
O Colaborador não se mede por utilization. Se você o mede por utilization, o incentiva a alongar conversas para preencher seu tempo. O que importa do Colaborador é quanto ele demora para atender (response time) e quão satisfeito fica o cliente (CSAT). O benchmark de response time depende do canal: no WhatsApp, menos de 5 minutos é o padrão aceitável; no chat web, menos de 1 minuto. Aprofundamos em benchmarks de AHT no WhatsApp e como baixar o tempo de atendimento.
O Operador não se mede por response time individual. Seu valor é supervisionar e ajustar, não atender chats individualmente. Se seu Operador passa 100% do tempo atendendo chats, está atuando como Colaborador e desperdiçando as permissões pelas quais você paga. Se passa 0% atendendo, está desconectado da operação e vai tomar decisões ruins de configuração. O ponto saudável está no meio.
Uma métrica transversal que convém observar: cost per resolved conversation (custo total da operação dividido por conversas resolvidas). É o número que diz se seu modelo de 3 papéis está realmente gerando economia ou apenas mudando a forma de gastar.
Setup passo a passo no AsisteClick
Se você tem uma conta do AsisteClick e quer implementar este modelo de 3 papéis, estes são os passos. Não é um guia exaustivo —é a sequência mínima para ter o modelo funcionando.
1. Criar os departamentos que sua operação precisa. Não copie os departamentos de outra empresa. Pense que tipo de conversas você recebe e como quer roteá-las. Mínimo típico: Vendas, Suporte, Administração/Cobranças. Se você tem produto técnico, separe Suporte Nível 1 e Suporte Nível 2. Se você tem prospecção ativa, separe Vendas Inbound e Vendas Outbound.
2. Criar os usuários e atribuir-lhes papel e departamentos. Para cada pessoa da equipe:
- Decida se é Operador (precisa ver tudo) ou Colaborador (apenas o que é seu).
- Atribua-a a um ou vários departamentos.
- Defina permissões específicas dentro do departamento (atender, arquivar, transferir).
Um agente pode pertencer a múltiplos departamentos —útil para o horário de pico, quando alguém do Suporte ajuda em Vendas.
3. Configurar o Agente de IA com sua base de conhecimento. Suba os documentos que o Agente de IA vai usar para responder (PDFs de produtos, FAQ interna, políticas, manuais). No AsisteClick isso é feito no módulo AsisteGPT, que usa modelos OpenAI (GPT-5.4 e GPT mini) sobre sua base de conhecimento curada com RAG —Retrieval-Augmented Generation, uma técnica em que o modelo de IA consulta sua base de conhecimento antes de responder, em vez de inventar respostas. Defina no prompt qual é o alcance do bot (que temas cobre, quais não) e que tom usa.
4. Definir as regras de transferência do Agente de IA para cada departamento. Mapeie: se o bot detecta intent de Vendas, transfere para o departamento Vendas. Se detecta Suporte Técnico, para o Suporte. Se detecta intent fora de scope ou sentimento negativo sustentado, transfere para o departamento default (tipicamente Suporte Geral). Isso evita o antipadrão de "fila geral".
5. Configurar regras de atribuição automática dentro de cada departamento. Três modos principais:
- Por carga: o chat é atribuído ao agente do departamento com menos chats ativos.
- Por rotação: round-robin, cada chat vai para o próximo agente disponível.
- Por regras: você define condições (cliente VIP → agente sênior; idioma inglês → agente bilíngue; canal Instagram → equipe de redes).
A atribuição por carga é a mais comum e a que funciona melhor com equipes homogêneas.
6. Configurar escalation rules. Defina o que acontece se ninguém pegar o chat em X minutos: ele é reatribuído automaticamente? Salta para um departamento de backup? Notifica o Operador supervisor? Isso evita os chats órfãos —o pior inimigo do CSAT.
7. Opcional: ativar o AsisteCopilot para os Colaboradores junior. Se seu plano é AI Plus, você pode ativar o AsisteCopilot, que assiste o Colaborador em tempo real durante a conversa: sugere respostas, consulta a base de conhecimento, redige rascunhos. Serve especialmente para reduzir o AHT (Average Handle Time) em perfis novos ou de terceiro turno.
Uma vez configurado tudo, o fluxo funciona sozinho: o cliente escreve, o Agente de IA atende, transfere se necessário, os Colaboradores recebem os chats que lhes correspondem, e o Operador supervisiona pelo monitor. Se você quer automatizar além do atendimento —por exemplo, sincronizar contatos com seu CRM ou disparar ações no seu backend quando um chat é encerrado— isso é feito via AsisteAPI.

Caso aplicado: ISP regional com atendimento 24/7
Esta é uma operação real que você vai reconhecer se trabalhou em ISP regional: 80.000 clientes, oferta de fibra e wifi residencial, 3 cidades cobertas, plano empresarial pequeno. Antes de implementar o modelo de 3 papéis, a operação era assim:
Antes:
- 5 pessoas atendendo WhatsApp direto em horário comercial (9 às 18, segunda a sábado).
- Fora do horário: ninguém. O cliente que escrevia às 22h por uma queda de serviço recebia resposta no dia seguinte.
- Todos os chats caíam em um único número, sem categorização.
- Cada agente atendia o que chegava: consultas comerciais, suporte técnico, reclamações de faturamento, pedidos de cancelamento.
- Sem relatórios operacionais. A supervisora pedia "o resumo do dia" por WhatsApp a cada agente.
- CSAT não medido sistematicamente. Conhecia-se pelas reclamações nas redes.
- Tempo de primeira resposta médio: 12-18 minutos no horário de pico.
O problema operacional não era falta de gente —era falta de arquitetura. Os 5 agentes passavam tanto tempo em consultas repetitivas ("qual é o preço do plano de 300 megas?", "quando é feita a instalação?", "vocês atendem em tal bairro?") que não tinham cabeça para as reclamações técnicas reais. As reclamações técnicas resultavam em mau atendimento, mau atendimento resultava em cancelamentos. Para o detalhe de como se monta um Agente de IA específico para ISP, você pode ver chatbot ISP para suporte técnico.
Depois (implementação do modelo de 3 papéis):
- Agente de IA 24/7 treinado sobre a base de conhecimento do ISP: planos e preços, cobertura por bairro, processo de instalação, extratos da conta, diagnóstico básico de falhas (reinício do roteador, verificação de luzes, agendamento de visita técnica).
- 1 Operador supervisor, que também é a pessoa que antes fazia tudo manualmente. Agora supervisiona o monitor em tempo real, ajusta regras de atribuição conforme o volume, olha relatórios semanais e configura o bot.
- 3 Colaboradores no turno noturno (22h-6h) —subcontratados, externos— que só veem os chats que escalam do bot durante a noite, dentro dos seus departamentos (Suporte Técnico e Atendimento ao Cliente). Não veem relatórios, não configuram nada, não veem chats do turno diurno.
- 4 Colaboradores no turno diurno (as mesmas pessoas que antes atendiam diretamente, agora liberadas do volume repetitivo). Só veem chats dos seus departamentos: 2 em Suporte Técnico, 1 em Comercial, 1 em Cobranças.
Departamentos criados: Comercial (consultas de venda e instalações), Suporte Técnico (falhas de serviço), Cobranças (faturamento, meios de pagamento), Cancelamentos (processo de retenção antes de cancelar).
Resultados em 90 dias:
- O Agente de IA absorveu o 72% do volume total sem escalar para humano. A maioria: consultas comerciais (preços, cobertura, planos) e diagnóstico básico de falhas resolvido com instruções automatizadas.
- Tempo de primeira resposta médio baixou de 12-18 min para menos de 30 segundos (o Agente de IA responde instantaneamente e atende 72%; os restantes 28% que escalam para humano têm response time de 3-5 min no horário diurno e 4-8 min no turno noturno).
- CSAT pós-atendimento subiu do baseline desconhecido para 87% medido sistematicamente.
- Volume total mensal atendido passou de ~6.000 chats/mês para ~14.000 chats/mês (parte porque agora há cobertura 24/7, parte porque o WhatsApp cresceu organicamente quando os clientes descobriram que recebiam resposta imediata).
- Custo operacional total: subiu 35% (os 3 Colaboradores noturnos externos + custo da plataforma + custo do Agente de IA), mas o volume atendido subiu 130%. Cost per resolved conversation baixou 41%.
A supervisora —agora Operador, na linguagem do modelo— passou de fazer triagem manual de chats o dia todo para operar com monitor em tempo real e revisar relatórios semanais. Sua capacidade de resposta a incidentes (quedas massivas de serviço em um bairro, por exemplo) melhorou notavelmente porque ela já não estava no dia a dia do chat.
Uma observação importante: não contrataram 3 pessoas full-time para o turno noturno. Contrataram 3 Colaboradores externos —que nem sequer estão na folha de pagamento do ISP— para cobrir as horas em que o Agente de IA escalava. Como os Colaboradores não requerem licenças adicionais no AsisteClick (vêm incluídos no plano), o custo marginal foi apenas o das horas pagas. Essa é a diferença entre ter arquitetura de papéis e não tê-la.
FAQ
Sou uma equipe de 2 pessoas, preciso de Operador e Colaborador separados?
Não. Em equipes pequenas os dois são Operadores. A distinção Operador/Colaborador começa a importar quando você tem 4-5 pessoas ou mais, ou quando incorpora papéis externos (freelancers, BPO, terceiro turno terceirizado). Para uma equipe de 2, ambos podem ver tudo, configurar tudo e atender chats —não há um risco operacional significativo. A regra prática: se você não tem alguém que quer que apenas atenda chats e nada mais, não precisa de Colaboradores diferenciados.
O Agente de IA substitui o humano?
Não, o complementa. O Agente de IA absorve o volume repetitivo e de baixa complexidade, que tipicamente é 60-75% das consultas em operações bem projetadas. O resto —reclamações complexas, casos sensíveis, negociações, retenção— continua sendo do humano. A ideia do modelo de 3 papéis não é substituir humanos; é liberar o humano do volume repetitivo para que ele se concentre onde agrega valor real. É a diferença entre ter uma equipe afogada em consultas de preço e uma equipe que fecha vendas e retém clientes.
Quantos Colaboradores preciso para atender 10 mil chats por mês?
Depende do deflection rate do Agente de IA. Com um bot bem projetado (60-75% deflection), desses 10 mil chats apenas 2.500-4.000 chegam ao humano. Considerando que um Colaborador full-time atende de 80 a 150 chats por dia (~2.500 por mês) dependendo da complexidade e do AHT, bastam 2-3 Colaboradores para cobrir um horário comercial padrão. Se você precisa de 24/7, soma mais 1-2 para turnos não convencionais. O plano Company do AsisteClick inclui 5 Colaboradores, o que cobre a maioria das operações nesse volume.
Qual é a diferença entre Colaborador e Supervisor?
Supervisor não é um papel próprio no modelo —é uma função que o Operador cumpre. No AsisteClick há dois papéis humanos operacionais (Operador e Colaborador), não três. A "supervisão" (olhar o monitor, reatribuir, revisar relatórios, ajustar configuração) é exatamente o que distingue o Operador. Se alguém precisa supervisionar, é Operador. Se só atende chats, é Colaborador. Isso é deliberado: adicionar um terceiro papel humano "Supervisor" com permissões intermediárias gera mais confusão que clareza. A linha é: precisa de visibilidade global? Sim → Operador. Não → Colaborador.
Este modelo se aplica igualmente a B2B e B2C?
Sim, com um ajuste de volume. No B2C o volume é alto e as consultas mais repetitivas, então o Agente de IA agrega mais (deflection rate alto, forte economia operacional). No B2B o volume é menor mas as consultas são mais complexas e de maior valor por interação, então o Agente de IA cobre menos porcentagem (40-55% típico vs 60-75% no B2C) mas libera a equipe humana para conversas consultivas. O modelo de 3 papéis funciona em ambos; o que muda é a proporção de carga entre o Agente de IA e os humanos. No B2B também é mais comum usar o AsisteCopilot, porque as consultas requerem respostas mais elaboradas e a assistência em tempo real ao humano agrega mais do que no B2C transacional.
Conclusão
A arquitetura de papéis é o que escala uma operação de atendimento ao cliente —não contratar mais gente. As ferramentas que tratam todos os membros da equipe como "agentes" indistintamente funcionam até o volume crescer, e depois quebram: caixas de entrada caóticas, supervisores afogados, bots que escalam tudo ou nada.
O modelo de 3 papéis —Agente de IA primeiro, Colaboradores que atendem o que chega ao seu departamento, Operadores que supervisionam e configuram— resolve este problema separando responsabilidades, permissões e métricas. Não é teoria: é o modelo que vemos funcionar em operações reais com dezenas de milhares de chats por mês.
O importante: implementar o modelo não requer substituir sua equipe nem triplicar seu investimento. Requer mapear quem faz o quê, configurar os departamentos corretamente, projetar bem o handoff entre Agente de IA e humano, e medir o que corresponde a cada papel.
Se você quer ver como se configura este modelo na sua operação —ou entender que plano se ajusta ao seu volume e à sua equipe— veja os planos do AsisteClick ou agende uma demonstração em AsisteChat. Nossa equipe ajuda você a projetar a arquitetura de papéis antes de implementar, que é onde o projeto se ganha ou se perde.