
Sua empresa precisa de um chatbot. Isso você já decidiu. A pergunta que te impede agora é outra: que tipo de chatbot? Porque nem todos os chatbots são iguais, e escolher errado te custa meses de implementação, frustração da equipe e —o pior— clientes que vão embora sem resposta.
Em 2026, as opções reais se reduzem a três abordagens: NLP tradicional (o bot treinado com perguntas e respostas), GPT / IA generativa (o que entende e gera linguagem natural com um modelo grande), e o híbrido (que combina ambos). Cada um tem trade-offs concretos em controle, flexibilidade, custo e velocidade de implementação.
Este guia compara os três sem rodeios, com critérios reais de produção —não demos de laboratório— para que você possa decidir qual se encaixa em sua operação.
Tabela comparativa rápida
| Critério | NLP tradicional | GPT / IA generativa | Híbrido |
|---|---|---|---|
| Precisão em respostas conhecidas | Excelente (determinístico) | Boa (depende do contexto) | Excelente |
| Gerenciamento de perguntas inesperadas | Ruim (não entende o que não foi treinado) | Excelente (gera respostas naturais) | Excelente |
| Risco de "alucinações" | Zero | Alto sem guardrails | Baixo (controlado) |
| Custo por conversa | Baixo | Médio-alto (tokens LLM) | Médio |
| Tempo de implementação | Médio (2-6 semanas) | Rápido (dias com RAG) | Médio (3-6 semanas) |
| Manutenção | Alto (re-treinar continuamente) | Baixo (atualizar base de conhecimento) | Médio |
| Controle sobre respostas | Total | Limitado | Alto (onde importa) |
| Escalabilidade para novos temas | Lenta (treinar por tema) | Rápida (adiciona docs ao RAG) | Rápida |
| Ideal para | Fluxos previsíveis, compliance | Conversa aberta, suporte L1 | Produção real, multi-caso |
O que é um chatbot NLP tradicional
Um chatbot NLP (Natural Language Processing) funciona com um modelo de classificação de intenções. Você o treina com pares de perguntas e respostas: "qual é o horário de atendimento?" → categoria horario → resposta predefinida. Quando um usuário digita algo, o bot classifica a intenção e retorna a resposta associada.
Como funciona por dentro
- Treinamento: você dá 10-50 variações da mesma pergunta por intenção ("horário de atendimento", "a que horas abrem", "estão abertos aos domingos"). O modelo aprende a classificar texto nessas intenções.
- Correspondência: quando chega uma nova mensagem, o bot calcula a similaridade com as intenções treinadas e escolhe a de maior confiança.
- Resposta: se a confiança supera um limiar (geralmente 70-85%), retorna a resposta predefinida. Caso contrário, cai para o fallback ("não entendi, você pode reformular?").
Vantagens concretas
- Determinístico. A mesma pergunta sempre gera a mesma resposta. Isso é importante quando há regulamentações, compliance ou informações sensíveis (preços, termos legais, disponibilidade de estoque).
- Auditável. Você pode ver exatamente qual intenção foi ativada, com qual confiança, e qual resposta foi dada. Debugging claro.
- Custo previsível. Você não paga por tokens nem por chamadas a uma API externa. O custo é fixo: hosting + manutenção do modelo.
- Funciona offline ou em edge. Não depende de uma API de terceiros para cada resposta.
Limitações reais
- Rígido. Se um usuário formula a pergunta de uma forma que você não treinou, o bot não entende. E há infinitas formas de perguntar a mesma coisa.
- Manutenção alta. Cada vez que surge um novo tópico (um produto, uma promoção, uma mudança de política), é preciso criar novas intenções, escrever variações, retreinar e testar.
- Escalabilidade lenta. Passar de 20 intenções para 200 requer semanas de trabalho de um bot builder dedicado.
- Conversa plana. Não "entende" contexto prévio. Cada mensagem é classificada independentemente. Se o usuário diz "e o preço?" depois de perguntar por um produto, o bot não sabe a qual produto se refere.
Quando escolher NLP puro
- Você tem menos de 30 intenções bem definidas.
- As respostas não podem variar (compliance, regulatório, preços fixos).
- Você não quer dependência de APIs externas (GPT da OpenAI, Google, etc.).
- Sua equipe tem um bot builder dedicado que pode manter o treinamento.
O que é um chatbot GPT / IA generativa
Um chatbot GPT (ou baseado em LLM — Large Language Model) não classifica intenções: entende a linguagem natural e gera respostas originais para cada mensagem. Por trás há um modelo como GPT-4, GPT-4o, Claude, Gemini ou um modelo open-source.
Como funciona por dentro
- Prompt do sistema: você fornece instruções ao modelo ("você é um assistente de atendimento ao cliente da [empresa]. Seu tom é profissional. Não invente informações que não estejam na base de conhecimento").
- Base de conhecimento (RAG): você anexa documentos com as informações reais da sua empresa — FAQs, manuais, preços, políticas. O modelo busca nestes documentos antes de responder (Retrieval-Augmented Generation).
- Geração: dado o mensagem do usuário + o contexto do RAG + o prompt do sistema, o modelo gera uma resposta em linguagem natural, sem estar limitado a respostas predefinidas.
Vantagens concretas
- Flexível. Entende reformulações, erros de ortografia, mistura de idiomas, perguntas complexas com múltiplas partes. Você não precisa treinar variações.
- Conversacional. Mantém contexto dentro da conversa. Se o usuário pergunta sobre um produto e depois diz "quanto custa?", o modelo sabe a que se refere.
- Escalabilidade rápida. O catálogo de produtos mudou? Você atualiza o documento no RAG. Não é preciso retreinar nada.
- Implementação rápida. Com uma boa base de conhecimento e um prompt ajustado, você pode ter um bot funcional em dias, não semanas.
Limitações reais
- Alucinações. O modelo pode inventar informações que soam corretas, mas são falsas. Sem guardrails, pode dizer ao cliente que um produto está disponível quando não está, ou dar um preço incorreto.
- Custo variável. Cada mensagem consome tokens da API. Em volumes altos (milhares de conversas diárias), o custo escala. Um plano de GPT-4o pode somar USD 200-500/mês apenas em tokens para uma operação de médio porte.
- Controle limitado. Você não pode garantir que a resposta seja exatamente X. Você pode guiar com prompts, mas a geração sempre tem um grau de variabilidade.
- Latência. A resposta leva 1-3 segundos (o modelo "pensa"). Em canais síncronos como WhatsApp, o usuário nota a demora versus um bot NLP que responde em milissegundos.
- Dependência de terceiros. Se a API da OpenAI (ou do provedor que você usar) tiver um outage, seu bot fica mudo.
Quando escolher GPT puro
- Sua base de conhecimento muda frequentemente (catálogos, preços, políticas).
- As perguntas são abertas e variadas (não cabem em 30 intenções fixas).
- Você quer implementar rápido (dias, não semanas).
- O risco de uma resposta ligeiramente imprecisa é tolerável (suporte L1, perguntas gerais, não transações financeiras).
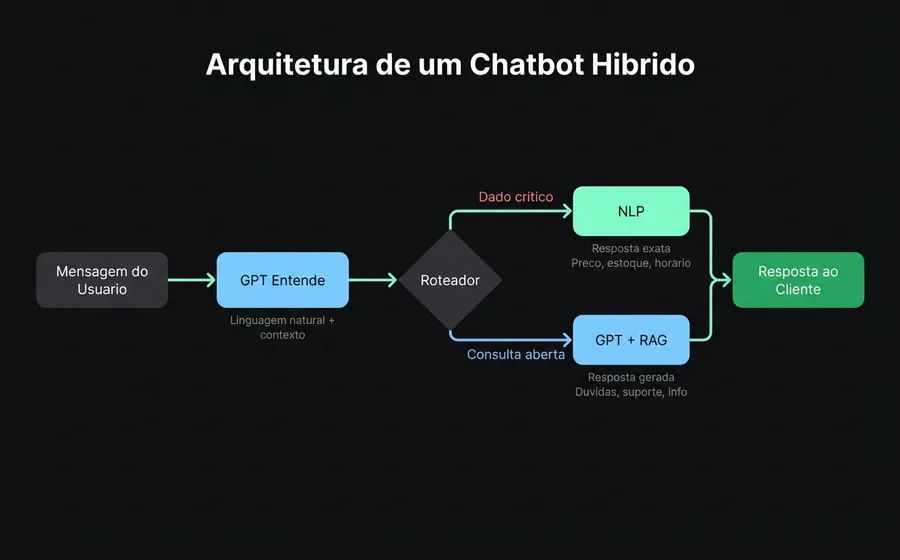
O que é um chatbot híbrido
A abordagem híbrida não é uma terceira tecnologia: é uma arquitetura que combina NLP e GPT na mesma conversa, ativando um ou outro conforme o contexto.
Como funciona por dentro
- Camada de entendimento (GPT). A mensagem do usuário chega e o modelo generativo a entende em linguagem natural, com todo o seu contexto conversacional.
- Roteador de decisão. Um sistema de regras avalia: este tópico requer uma resposta determinística (preço, estoque, status de um pedido, dado regulatório)? Se sim, passa para o módulo NLP. Se não, o GPT responde diretamente da base de conhecimento.
- Camada NLP (rotas determinísticas). Para os casos onde a precisão é inegociável, as respostas vêm de intenções treinadas: exatas, auditáveis, sem variação.
- Base de conhecimento (RAG). Ambas camadas consultam a mesma fonte de verdade: os documentos da sua empresa. O GPT para gerar respostas naturais, o NLP para validar dados pontuais.
Vantagens concretas
- O melhor de ambos os mundos. Flexibilidade conversacional do GPT onde a precisão exata não importa, determinismo do NLP onde importa.
- Guardrails nativos. As alucinações são contidas porque os dados críticos (preços, disponibilidade, horários, status de pedido) NUNCA passam por geração livre — vão pela rota NLP.
- Experiência de usuário superior. O cliente sente que fala com alguém que entende (GPT), mas as respostas de negócio são 100% confiáveis (NLP).
- Manutenção balanceada. As intenções NLP cobrem apenas os 15-30 casos críticos (não os 300 possíveis), assim, a manutenção é gerenciável. O GPT com RAG cobre o long tail sem treinamento adicional.
Limitações reais
- Complexidade de setup. Configurar o roteador (quando NLP, quando GPT) requer pensamento de design. Não é plug & play.
- Custo de ambas as camadas. Você paga o hosting do modelo NLP + os tokens do GPT. Embora na prática, como o NLP resolve os casos frequentes (que são os mais baratos de resolver), o custo total costuma ser menor que GPT puro.
- Debugging mais complexo. Quando algo falha, é preciso saber se falhou na camada GPT ou na NLP. Requer logs claros de qual rota cada conversa tomou.
Quando escolher híbrido
- Você tem casos de uso mistos: perguntas abertas (suporte geral) + consultas de dados concretos (preço, estoque, status).
- A precisão importa em alguns tópicos, mas não em todos.
- Você vai escalar (começa com 20 intenções NLP + GPT para o resto, e cresce organicamente).
- Você quer controle onde precisa de controle e flexibilidade onde não.
Comparação detalhada
Precisão e confiabilidade
| Cenário | NLP | GPT | Híbrido |
|---|---|---|---|
| Quanto custa o plano Business? | Resposta exata: $20/mês | Provavelmente correta se estiver no RAG, risco de erro | Resposta exata (rota NLP) |
| Quero entender como funciona a IA conversacional para o meu negócio | Fallback (não treinado) | Resposta natural e útil do RAG | Resposta natural (rota GPT) |
| Cancelar minha assinatura | Rota para agente ou resposta predefinida | Pode tentar resolver sozinho (arriscado) | Rota para agente (regra determinística) |
| Olá, tenho um problema com um pedido que fiz ontem | Provável fallback | Pede mais dados e escala | Pede dados (GPT), consulta o CRM (NLP), responde |
O híbrido ganha em cenários mistos porque não força todas as conversas pelo mesmo canal.
Custo total de operação (TCO)
Para uma operação de 2,000 conversas/mês com ~8 mensagens em média por conversa:
| Componente | NLP | GPT | Híbrido |
|---|---|---|---|
| Plataforma base | USD 50-150/mês | USD 50-150/mês | USD 100-260/mês |
| Tokens LLM | $0 | USD 80-200/mês | USD 40-100/mês |
| Bot builder (manutenção) | 8-16 hrs/mês | 2-4 hrs/mês | 4-8 hrs/mês |
| Custo de erros (clientes perdidos) | Médio (fallbacks) | Alto (alucinações) | Baixo |
| TCO estimado | USD 150-350/mês | USD 200-450/mês | USD 200-400/mês |
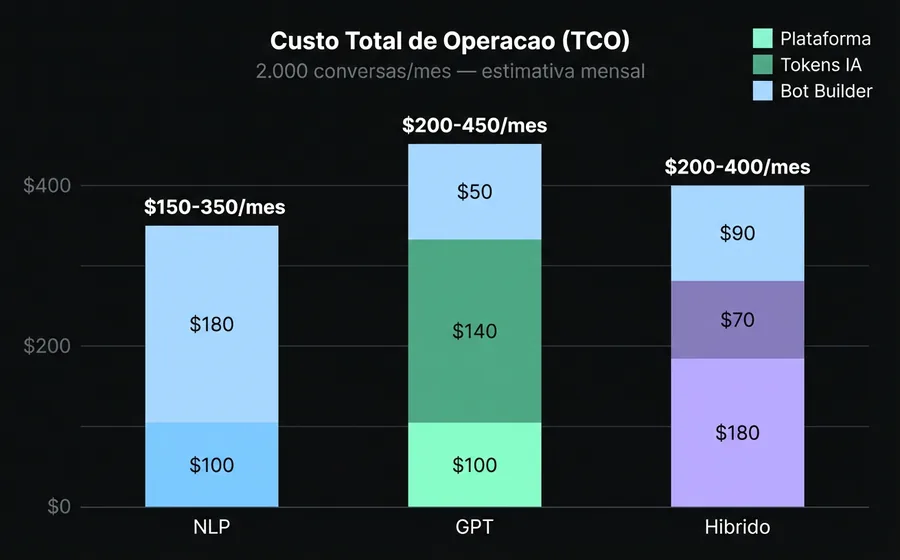
O NLP parece mais barato até que você conta as horas do bot builder e o custo dos fallbacks (clientes que não obtêm resposta e vão embora). O GPT parece caro até que você conta que não precisa de um bot builder full-time. O híbrido otimiza ambos os lados.
Tempo de implementação
| Fase | NLP | GPT | Híbrido |
|---|---|---|---|
| Setup inicial | 1-2 semanas | 2-5 dias | 1-2 semanas |
| Treinamento / knowledge base | 2-4 semanas | 1-3 dias | 1-2 semanas |
| Testes e ajustes | 1-2 semanas | 3-5 dias | 1-2 semanas |
| Total | 4-8 semanas | 1-2 semanas | 3-6 semanas |
GPT ganha em velocidade, mas "rápido de implementar" não significa "pronto para produção". Um GPT mal configurado colocado em produção em 3 dias pode fazer mais dano do que não ter bot.
Escalabilidade
- NLP: escalar = adicionar intenções, treinar variações, testar. Crescimento linear com esforço humano.
- GPT: escalar = adicionar documentos ao RAG. Crescimento quase instantâneo.
- Híbrido: escalar o GPT (adicionar docs) é rápido. Escalar as rotas NLP (novos dados críticos) é planejado. Crescimento controlado.
Três erros comuns ao escolher
1. "GPT resolve tudo, não preciso de NLP"
O erro mais caro de 2025-2026. As empresas implementam GPT sem guardrails, e em duas semanas descobrem que o bot disse a um cliente que o produto tem garantia de 5 anos (não tem) ou que o envio é grátis (não é). Uma única alucinação sobre preços ou políticas pode custar mais do que 6 meses de assinatura da plataforma.
2. "NLP é mais seguro, fico com isso"
Seguro sim, mas surdo. Um bot NLP que responde "não entendi" a 40% das perguntas não é mais seguro — é pior. Cada fallback é um cliente que saiu sem resposta. A segurança real é responder bem, não evitar responder.
3. "Implemento GPT agora e depois adiciono NLP se for preciso"
A dívida técnica se acumula rápido. Se você começar com GPT puro e depois precisar de rotas determinísticas, vai ter que refatorar fluxos, retreinar e recalibrar o router. É mais eficiente projetar a arquitetura híbrida desde o dia um, mesmo que você comece com poucas rotas NLP.
Como cada abordagem é implementada na prática
NLP: o fluxo típico
- Mapear os 20-50 motivos de contato mais frequentes com a equipe de atendimento
- Redigir respostas modelo para cada intenção
- Escrever 10-30 variações de cada pergunta para treinamento
- Treinar o modelo e calibrar limiares de confiança
- Configurar fallbacks e escalonamento para agentes
- Testar com conversas reais e ajustar
- Repetir a cada mês com novas intenções
Plataformas como AsisteNLP simplificam este processo com interfaces de treinamento visual e re-treinamento contínuo baseado em conversas reais que o bot não soube resolver.
GPT: o fluxo típico
- Coletar a base de conhecimento (FAQs, manuais, políticas, catálogo)
- Configurar o prompt do sistema com tom, limites e regras
- Implementar RAG: o modelo busca em seus documentos antes de responder
- Definir guardrails: o que o bot NÃO pode dizer (disclaimers, temas proibidos)
- Testar com edge cases (perguntas maliciosas, fora do tópico, em outros idiomas)
- Monitorar alucinações nas primeiras 2 semanas intensivamente
AsisteGPT oferece este fluxo com bases de conhecimento customizadas, prompts ocultos (o usuário não os vê) e RAG integrado, sem necessidade de código.
Híbrido: o fluxo típico
- Fase GPT: carregar base de conhecimento e configurar prompt (3-5 dias)
- Fase NLP: identificar os 10-20 casos onde a precisão é crítica e treinar essas intenções
- Configurar o roteador: definir as regras de quando passa para o NLP e quando para o GPT
- Integrar com CRM: as rotas NLP podem consultar dados em tempo real (estoque, pedidos, saldos) via AsisteAPI
- Testar o handoff entre camadas: a transição NLP↔GPT é natural?
- Lançar e monitorar ambas as camadas
A combinação de AsisteChat (bandeja omnichannel) + AsisteNLP (rotas determinísticas) + AsisteGPT (geração com RAG) é exatamente esta arquitetura. Não é por acaso que são módulos separados que se combinam: cada empresa pode ativar apenas o que precisa e crescer de NLP puro para híbrido sem migrar.
Perguntas frequentes
Posso começar com NLP e adicionar GPT depois?
Sim, e é um caminho comum. Muitas empresas começam com 20-30 intenções NLP para resolver os casos mais frequentes, e quando o volume cresce e os fallbacks se acumulam, adicionam GPT com RAG para cobrir o long tail. A chave é que sua plataforma suporte ambos desde o início para que a migração seja configuração, não reescrita.
O GPT substitui o NLP?
Não. O GPT substitui o NLP em conversa aberta, mas não em respostas que exigem precisão absoluta. Pense assim: o GPT é o generalista que sabe falar sobre tudo, o NLP é o especialista que nunca se engana em seu tema. Uma boa operação precisa de ambos.
Quanto custa o GPT em tokens por mês?
Depende do modelo e do volume. Para uma operação de 2,000 conversas/mês com GPT-4o mini, o custo em tokens gira em torno de USD 40-80/mês. Com GPT-4o completo, USD 150-300/mês. Os modelos mais econômicos (GPT-3.5 turbo, Claude Haiku) podem cair para USD 15-30/mês com qualidade aceitável para suporte L1.
A abordagem híbrida é mais difícil de manter?
É mais complexo de configurar inicialmente, mas mais fácil de manter a longo prazo. O NLP puro exige retreinar cada vez que um novo tópico aparece. O GPT puro exige monitorar alucinações continuamente. O híbrido reduz ambas as cargas: o GPT se autoatualiza com novos docs, e as rotas NLP só cobrem os casos críticos (poucos, estáveis).
O que acontece com a privacidade dos dados se eu usar GPT?
Os dados das conversas passam pela API do provedor do LLM (OpenAI, Anthropic, Google, etc.). A maioria oferece contratos de processamento de dados (DPA) e opções de não treinamento. Se sua empresa lida com dados sensíveis (saúde, finanças), verifique se o provedor cumpre a regulamentação do seu país. Algumas plataformas permitem usar modelos on-premise ou em sua própria cloud para evitar que os dados saiam de sua infraestrutura.
Veredito
Se tivéssemos que resumir a decisão em uma frase:
- Escolha NLP se suas conversas são previsíveis, reguladas, e você tem um bot builder dedicado.
- Escolha GPT se você precisa de velocidade de implementação, suas perguntas são variadas, e o risco de uma resposta imprecisa é tolerável.
- Escolha híbrido se você vai para produção real, com casos mistos, onde alguns erros são caros e outros são aceitáveis.
A verdade incômoda é que a maioria das empresas que começam com NLP puro ou GPT puro acaba migrando para o híbrido dentro dos primeiros 6 meses. O NLP puro fica aquém quando o volume cresce. O GPT puro se torna arriscado quando um erro custa dinheiro. O híbrido é onde a indústria converge.
Se sua plataforma atual só suporta uma das duas abordagens, você terá que migrar quando precisar da outra. Escolher uma plataforma que suporte NLP, GPT e a combinação desde o início — como Bruno, com AsisteNLP + AsisteGPT + AsisteCopilot como módulos combináveis — economiza essa migração para você e lhe dá flexibilidade para crescer no ritmo da sua operação, não no ritmo do seu provedor.
Continue lendo
- Como Peugeot Belchamp transformou sua estratégia de leads com AsisteClick — um caso real de implementação híbrida com resultados quantificados