
El 30% de los tickets de soporte en SaaS son repetitivos: la misma pregunta de onboarding, el mismo "no me llega el mail de reset", el mismo "cómo cambio el plan" cien veces por semana. Lo dice el Zendesk CX Trends Report 2024, y cualquiera que haya operado un equipo de soporte por más de seis meses lo confirma sin necesidad de un benchmark. Si tu equipo de Customer Success gasta más de cuatro horas por día respondiendo lo mismo, este post es para ti.
Pero la pregunta importante no es cuántos tickets bajar. Es cuáles, cómo, y sin tirar el CSAT abajo en el intento. Klarna automatizó el trabajo de 700 agentes en febrero de 2024, lo anunció como triunfo, y un año después estaba contratando humanos de vuelta. La automatización mal hecha es peor que la sobrecarga: erosiona la confianza del cliente y desmoraliza al equipo que queda.
Esta guía propone una respuesta distinta: una arquitectura de 3 capas (self-service estructurado, bot conversacional y Agente de IA generativo con copilot humano) que, bien implementada, baja el volumen de tickets entre 40% y 60% en seis meses sin sacrificar satisfacción. Vas a encontrar el framework completo, los benchmarks de la industria, los KPIs que importan, las cuatro fases de implementación y la lista de errores que casi todas las empresas SaaS cometen en el camino.
Por qué el volumen de tickets escala con el SaaS (y por qué es un problema)
El soporte en un SaaS B2B tiene un problema estructural: escala linealmente con la base de clientes, pero los ingresos no siempre lo hacen. Cada cliente nuevo trae entre 0.5 y 3 tickets por mes en promedio según Intercom Customer Service Trends 2024, dependiendo de la complejidad del producto y la madurez del onboarding. Si pasas de 200 a 1.000 clientes, no necesitas multiplicar tu equipo de soporte por cinco, pero sí por algo. Y ese "algo" es lo que define si el negocio escala o se ahoga.
El otro problema es la composición del volumen. La regla 80/20 aplica con violencia en soporte SaaS: el 20% de las consultas explica entre el 70% y el 80% del volumen total. Esas consultas no son las complejas, son las repetitivas. Y son las que el equipo humano resuelve peor cuando llega la fatiga del viernes a la tarde.
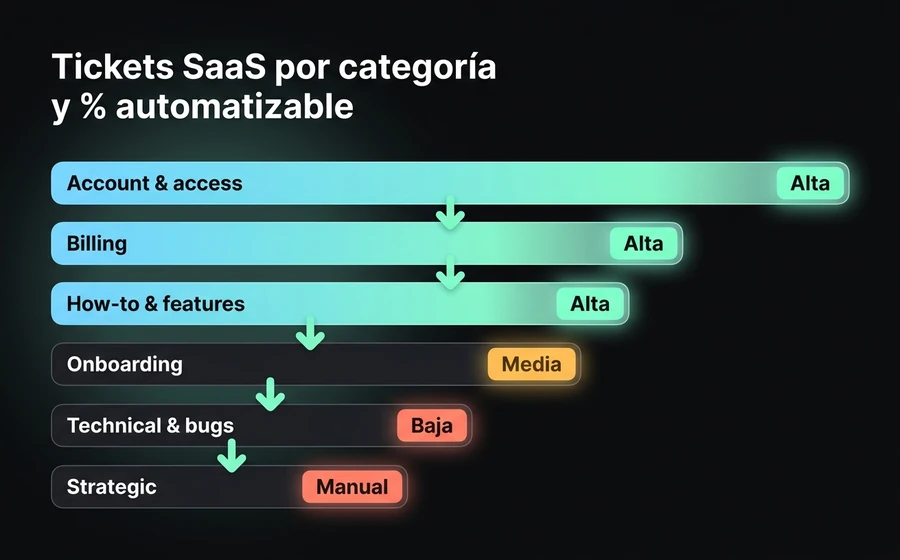
Las categorías típicas en SaaS B2B se distribuyen así:
| Categoría | % del volumen típico | Tipo de resolución |
|---|---|---|
| Account & access (login, password reset, MFA, invitaciones a usuarios) | 18-25% | Casi 100% automatizable |
| Billing & subscriptions (facturas, cambios de plan, métodos de pago) | 15-22% | 70-90% automatizable |
| Onboarding & setup (primeros pasos, configuración inicial, integraciones) | 12-18% | 40-60% automatizable |
| How-to & features (cómo se hace X, dónde está Y) | 20-30% | 60-80% automatizable |
| Technical issues & bugs (errores reales, comportamiento inesperado) | 15-25% | 10-30% automatizable, resto necesita humano |
| Strategic & advisory (consultas de uso avanzado, integraciones custom) | 5-10% | No automatizable, NO se debe automatizar |
Fuente: composición típica observada en clientes SaaS B2B de AsisteClick, consistente con HubSpot Service Hub benchmarks 2024.
La conclusión operativa es clara: hay un 50-65% del volumen que es razonablemente automatizable sin sacrificar calidad, siempre que diferencies bien las categorías. El error más común es intentar automatizar todo, incluido el 5-10% estratégico, o no automatizar nada por miedo a perder calidad. Ninguno de los dos extremos funciona.
Antes de seguir, una aclaración de vocabulario. En el resto del post vas a leer dos términos que suelen confundirse: chatbot (de reglas, NLP, intents predefinidos) y Agente de IA (modelo generativo tipo GPT-5.4 con acceso a tu base de conocimiento vía RAG). No son sinónimos, y la diferencia importa para el deflection rate. Si quieres profundizar en cómo decidir entre uno y otro, tenemos un post dedicado en chatbot NLP vs GPT vs híbrido.
Deflection rate: la métrica que en realidad importa
Si tu reporte mensual de soporte tiene "% tickets cerrados", "tickets recibidos" y "tiempo de respuesta promedio", está midiendo la sintomatología, no la salud del sistema. La métrica que conecta automatización, equipo humano y experiencia del cliente en un solo número es el deflection rate.
Qué es y cómo se calcula
El deflection rate es el porcentaje de consultas que se resuelven sin escalar a un humano. La fórmula básica es:
Deflection Rate = (Tickets resueltos por self-service o IA / Tickets totales recibidos) × 100
Pero la definición operativa tiene matices que cambian todo. "Resuelto" no quiere decir "el bot dijo algo". Quiere decir el cliente obtuvo la información que necesitaba y no volvió a abrir un ticket por el mismo tema en las siguientes 24-48 horas. Esa es la diferencia entre deflection rate honesto y deflection rate vanity.
Hay dos formas de medirlo, y conviene tener las dos en el dashboard:
- Deflection rate por sesión: % de conversaciones con el bot/IA que terminan sin "hablar con humano" ni reabrir ticket en 48h.
- Deflection rate por ticket: % de tickets que el sistema cierra automáticamente y el cliente no reabre.
El número honesto suele estar entre 30% y 60% en SaaS maduros. Los reportes que muestran 85% generalmente están contando "el bot respondió" como deflection, lo cual es trampa.
Benchmarks por industria
Los datos de Intercom Customer Service Trends 2024 y Zendesk CX Trends 2024 dan la siguiente foto para SaaS B2B:
| Etapa de madurez | Deflection rate típico | Tecnología asociada |
|---|---|---|
| Solo FAQ estática + base de conocimiento | 8-15% | Help Center indexable |
| Bot NLP entrenado (intents top 20) | 25-35% | Chatbot de reglas o NLP |
| Bot NLP + handoff inteligente | 35-45% | Chatbot + cola priorizada |
| Agente de IA generativo con RAG | 45-60% | LLM + base de conocimiento conectada |
| Agente de IA + copilot al humano | 55-70% | LLM + asistente al agente |
Fuente: composición agregada de Intercom Customer Service Trends 2024, Zendesk CX Trends 2024 y HubSpot Service Hub benchmarks.
Cuando alguien te dice "alcanzamos 80% de deflection con IA", pedile la metodología antes de creerle. La cifra realista de empresas SaaS bien implementadas, midiendo honestamente, está entre 45% y 60% al año de implementación.
Por qué deflection ≠ "tasa de respuesta automática"
Acá está el error que más se ve. Una empresa instala un bot, mide cuántas conversaciones tocaron al bot, y reporta eso como "80% de automatización". Pero si el bot dice "no entiendo, escribime de nuevo" y el cliente abandona o escala manualmente, eso no es deflection. Es frustración automatizada.
La diferencia operativa: deflection se mide en resolución, no en respuesta. El cliente resolvió su problema o no. Si no, contó como ticket aunque no haya escalado formalmente.
Por eso siempre debe mirarse junto al CSAT post-deflection (satisfacción del cliente después de la interacción con el bot/IA, sin escalado). Si el deflection sube pero el CSAT post-deflection baja, no estás mejorando, estás escondiendo el problema. Volveremos sobre este punto en la sección de KPIs.
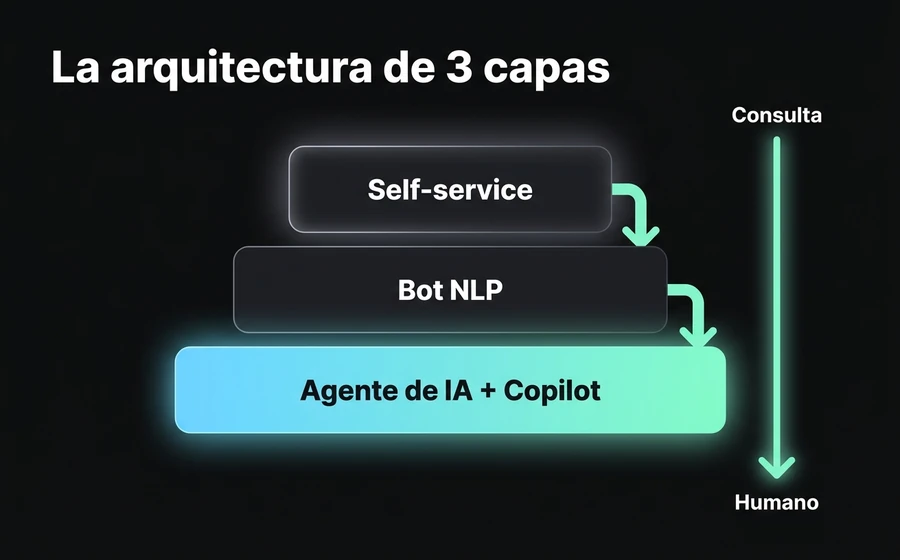
La arquitectura de 3 capas para reducir tickets
Acá viene el core del post. La pregunta operativa no es "¿pongo un bot?", es "¿qué pongo en cada capa para que el volumen baje sin que el cliente se frustre?". La arquitectura que recomendamos —y que aplicamos en clientes SaaS de AsisteClick— tiene tres capas que trabajan en orden ascendente de complejidad.
La idea clave es que cada capa absorbe lo que la anterior no pudo resolver, sin que el cliente sienta el handoff. Si el self-service estructurado resuelve, listo. Si no, el bot conversacional toma el control. Si el bot no puede, el Agente de IA generativo entra en juego. Y si todo eso falla, el humano recibe el ticket con todo el contexto previo, no de cero.
Capa 1: Self-service estructurado
Esta es la capa más subestimada y la que más volumen absorbe cuando está bien hecha. El cliente no quiere chatear con nadie, quiere encontrar la respuesta rápido. El self-service estructurado tiene tres componentes:
- Help Center con búsqueda funcional: una base de conocimiento pública, indexable por Google, con un buscador que entiende sinónimos. La métrica de éxito acá es "% de visitas a Help Center que NO terminan en un ticket abierto en las 24h siguientes". Si tu Help Center existe pero el deflection desde ahí es bajo, no es un problema de contenido, es de findability.
- FAQ contextual dentro del producto: links directos a artículos relevantes en el momento exacto donde el usuario se traba. Si el usuario está en la pantalla de configuración de webhooks, el botón de ayuda debe llevarlo al artículo de webhooks, no al Help Center genérico.
- Estados del sistema y changelog: una página pública de status (uptime, incidentes activos) y un changelog visible. Esto absorbe el 5-10% de tickets que son "¿está caído algo?" o "¿cuándo lanzan X feature?".
Deflection esperada de esta capa: 10-18% según Intercom y benchmarks propios. Es la capa más barata de implementar y la que más se descuida.
Esta capa funciona porque el cliente prefiere resolverlo solo. El 67% de los consumidores prefieren self-service antes que hablar con un representante (HubSpot Service Hub data 2024). La capa 1 no es un "fallback", es la primera opción para el cliente moderno.
Capa 2: Bot conversacional NLP
Cuando el self-service no es suficiente —porque el usuario no encuentra el artículo, o porque la consulta requiere parámetros (un nombre, un ID, una fecha)— entra el bot conversacional. Acá hablamos de un bot de tipo NLP: entrenado sobre intents (intenciones del usuario) que cubren el top 20-30 de consultas frecuentes.
Un bot NLP bien entrenado en SaaS típicamente cubre:
- Reset de password e invitaciones a usuarios.
- Estado de facturación y descarga de facturas.
- Cambio de plan o método de pago (con escalado a humano para el cierre).
- Consultas de estado de la cuenta (uso, límites, fecha de renovación).
- Preguntas frecuentes con respuesta cerrada ("¿pueden integrarse con Salesforce?").
- Triage inicial: capturar el problema y rutearlo al departamento correcto.
La clave del bot NLP es que es determinístico: dado un intent reconocido, la respuesta es siempre la misma. Esto lo hace predecible, auditable y barato de operar, pero lo limita: si el cliente pregunta algo que no está en los intents entrenados, el bot tiene que decir "no entendí" o derivar a humano. No improvisa.
Deflection esperada de esta capa: 15-25% sobre el volumen que llegó hasta acá. Sumado a la Capa 1, vas a estar en 25-40% de deflection total.
El bot NLP se entrena sobre datos reales. La trampa común es entrenarlo con intents teóricos ("usuarios pueden preguntar X, Y, Z") en lugar de con el historial real de tickets. Si vas a entrenar uno, exportá los últimos 6 meses de tickets, clusterizalos y construí los intents desde los datos. Tenemos un post completo sobre eso en prompt engineering para chatbots de atención.
Capa 3: Agente de IA generativo + Copilot al humano
Acá es donde la matemática del deflection rate cambia de escala. Un Agente de IA generativo (basado en un LLM como GPT-5.4, conectado vía RAG a tu base de conocimiento, documentación de producto y, opcionalmente, datos de la cuenta del cliente) no necesita intents predefinidos. Razona sobre la consulta, busca contexto, y responde en lenguaje natural.
Lo que un Agente de IA hace bien y un bot NLP no:
- Consultas largas y ambiguas: "Hola, tengo un problema con la integración de HubSpot, no me están entrando los contactos nuevos desde ayer, ya verifiqué el API key, qué hago". Un bot NLP se pierde. Un Agente de IA identifica los pasos de diagnóstico, los pregunta uno por uno, y resuelve o escala con contexto completo.
- Combinación de varias intents en una sola consulta: "Quiero cambiar mi plan y también necesito agregar a tres usuarios nuevos, ¿cómo lo hago?". El Agente de IA divide la consulta y la resuelve por partes.
- Personalización con datos de la cuenta: si el Agente de IA tiene acceso (vía API) al estado real de la cuenta del usuario, puede responder "tu plan actual es Pro hasta el 15 de junio, puedes cambiarlo desde Settings > Billing, te dejo el link directo" en lugar de la respuesta genérica.
Pero hay algo más importante todavía, que define la diferencia entre una empresa SaaS que baja tickets y una que baja tickets sin destruir CSAT: el Copilot al humano.
Cuando una consulta escala al equipo humano (porque la IA decidió escalar, o porque el cliente lo pidió explícitamente), el agente humano no recibe el ticket de cero. Recibe:
- El historial completo de la conversación con la IA.
- Un resumen del problema generado por el Agente de IA.
- Sugerencias de respuesta basadas en la base de conocimiento.
- Datos de la cuenta del cliente ya cargados (plan, fecha de alta, uso, tickets previos).
Esto se llama Copilot y reduce el AHT (Average Handle Time) del agente humano entre 25% y 40% según McKinsey State of AI 2024. Si quieres profundizar en eso, mira Copilot: agentes de IA con respuestas en tiempo real.
Deflection esperada de esta capa: 20-30% adicional. Sumado a las anteriores, una empresa SaaS bien implementada llega a 50-65% de deflection total.
Si te interesa el detalle técnico de cómo se arma la base de conocimiento para que la Capa 3 funcione bien (chunking, embeddings, RAG, refresh frequency), tenemos un post completo en las 3 capas de conocimiento de un Agente de IA.
Comparativa de las 3 capas
| Capa | Tecnología | Cuándo aplica | Deflection típica | Complejidad implementación | Costo operativo |
|---|---|---|---|---|---|
| 1. Self-service | Help Center + FAQ + status page | Consultas con respuesta fija, públicas | 10-18% | Baja (1-2 semanas) | Bajo (mantenimiento de docs) |
| 2. Bot NLP | Intents entrenados + flujos | Top 20-30 consultas, requiere parámetros | 15-25% | Media (4-6 semanas) | Medio (reentrenamiento mensual) |
| 3. Agente de IA + Copilot | LLM + RAG + handoff con contexto | Consultas largas, ambiguas, personalizadas | 20-30% | Alta (8-12 semanas) | Medio-Alto (tokens + curación) |
Las tres capas juntas, operando en orden, llevan a un deflection acumulado realista del 45-65% en seis meses. Por encima de eso, los retornos disminuyen rápidamente y entrás en la zona de riesgo Klarna: querer automatizar lo que no se debe automatizar.
Cómo NO hacerlo: el caso Klarna y otros errores comunes
En febrero de 2024, Klarna anunció que su Agente de IA estaba haciendo el trabajo equivalente a 700 agentes humanos full-time, con CSAT igual al humano y resolución 25% más rápida. La acción reaccionó, la prensa tech celebró, y todas las empresas SaaS preguntaron "¿cómo lo hicieron?".
Un año después, en mayo de 2025, Klarna estaba contratando humanos otra vez. El CEO Sebastian Siemiatkowski admitió en entrevistas que la calidad había caído, que los clientes querían hablar con humanos, y que la cobertura de IA había sido más una declaración de intenciones que una realidad operativa. La lección no es "la IA no funciona". La lección es que automatizar el trabajo de 700 personas en pocos meses, sin tener la arquitectura de fallback ni los KPIs de calidad bien medidos, termina mal.
Si te interesa el análisis detallado, escribimos un post completo sobre lo que se puede aprender del caso en Klarna y el error de IA en customer service. Acá resumimos los anti-patrones más comunes que ese caso ejemplifica y que vemos repetidos en clientes nuevos:
Reemplazar humanos de un día al otro
El error de Klarna no fue usar IA, fue eliminar la capacidad humana antes de validar la cobertura de la IA en producción real. Lo correcto es lo contrario: la IA escala primero, el equipo humano se redimensiona después, basándose en datos de seis meses como mínimo. La automatización no se mide en "cuántos humanos saqué", se mide en "qué porcentaje del volumen resolví bien sin escalar". Lo segundo te da el espacio para decidir lo primero con datos. Lo primero hecho sin lo segundo es una bomba de tiempo.
Automatizar onboarding complejo
Los clientes nuevos tienen una necesidad psicológica de hablar con un humano en las primeras dos semanas. No porque la IA no sepa responder, sino porque están evaluando si la empresa "está ahí" para ellos. Automatizar el onboarding antes de los 14-30 días es uno de los predictores más fuertes de churn temprano. La regla operativa: el onboarding es la última cosa que se automatiza, no la primera. Y cuando se automatiza, siempre con escalado fácil al humano.
Eliminar el botón "hablar con humano"
Algunos equipos esconden el botón de escalado para forzar deflection. Es un anti-patrón. El cliente que quiere hablar con humano y no puede, abandona o reescala por otro canal (Twitter, email a un ejecutivo, review pública). Visibilidad del escalado humano debe ser siempre alta. Si el deflection rate cae porque el botón está visible, no escondas el botón: mejora la IA.
Medir solo deflection, ignorar CSAT post-deflection
Como dijimos antes: deflection sin CSAT post-deflection es vanity. La métrica única que importa es la dupla deflection + CSAT post-deflection. Si el deflection sube 10 puntos y el CSAT cae 15 puntos, perdiste. Lo veremos en detalle en la sección de KPIs.
Pretender que la IA "ya está entrenada"
Ningún Agente de IA en producción está terminado. La revisión semanal de consultas no resueltas, la mejora de prompts, el refresh de la base de conocimiento son trabajo permanente. Las empresas que tratan el setup como "proyecto" (con inicio y fin) en lugar de "operación" (continua) son las que ven el deflection rate degradarse después de 6 meses.
Implementación práctica: 4 fases
Una pregunta razonable después de leer todo lo anterior es: "OK, ¿por dónde empiezo?". La respuesta corta: medí antes de automatizar. La respuesta larga es este roadmap de cuatro fases que aplicamos en implementaciones SaaS con AsisteClick.
Fase 1: Medir baseline (semana 1-2)
Antes de comprar cualquier herramienta o entrenar cualquier bot, necesitas saber dónde estás parado. Lo que tienes que medir, idealmente con seis meses de histórico:
- Volumen total de tickets/mes: media, mediana, pico de semana.
- Distribución por categoría: usar las 6 categorías de la primera sección como base, ajustar a tu producto.
- Top 20 consultas por frecuencia: agrupar tickets por similitud y ordenar. Vas a descubrir que 20 consultas explican el 70% del volumen.
- AHT promedio por categoría: cuánto tarda tu equipo humano en resolver cada tipo.
- CSAT actual: el baseline contra el cual vas a comparar después.
- Tickets escalados / reabiertos: % de tickets que no se resuelven en primer contacto. Este número rara vez se mide y es de los más importantes.
Salida de esta fase: un documento de una página con el estado actual. Sin esto, cualquier mejora posterior es invisible.
Fase 2: Self-service estructurado + Bot NLP (semana 3-8)
Implementación de las capas 1 y 2 en paralelo. En seis semanas tienes que tener:
- Help Center con los 30-50 artículos que cubren el top 20 de consultas. Cada artículo con título claro, respuesta directa en los primeros dos párrafos, y vídeo o screenshot cuando aplique.
- FAQ contextual dentro del producto (botones de ayuda en las pantallas críticas).
- Bot NLP entrenado sobre los 20 intents más frecuentes. Mínimo 50 ejemplos por intent.
- Handoff a humano siempre visible y funcional, con captura del contexto previo.
Deflection esperada al final de Fase 2: 25-40%. Si el baseline era 100 tickets/día, ahora estarás entre 60 y 75. Si el número no baja en este rango, hay un problema de implementación, no de tecnología.
Esta fase es la más subestimada. Empresas que saltan directo a "Agente de IA generativo" sin tener Capa 1 y 2 funcionando terminan con la IA respondiendo lo que un FAQ bien escrito ya respondería, a un costo de tokens que no se justifica.
Fase 3: Agente de IA generativo + Copilot (semana 9-20)
Acá entran las herramientas más sofisticadas. En las siguientes 12 semanas:
- Conectar un LLM (GPT-5.4 o equivalente) a tu base de conocimiento vía RAG. Esto requiere chunking de tu documentación, embeddings, y un buen prompt de sistema.
- Conectar al Agente de IA con datos de la cuenta del cliente vía API (plan actual, estado de uso, tickets previos). Sin esto, el Agente de IA es un FAQ chatty, no un asistente.
- Implementar el Copilot para el equipo humano: cuando escala un ticket, el agente recibe contexto + resumen + sugerencias de respuesta.
- Definir las reglas de handoff: cuándo escala automáticamente (consulta de billing crítica, error de bug confirmado, cuenta enterprise, cliente con NPS bajo en el histórico).
- Audit log de cada interacción de IA para review manual semanal.
Deflection esperada al final de Fase 3: 45-60% acumulado. Si llegas a esto con CSAT post-deflection ≥ CSAT general, ganaste.
Fase 4: Loop de mejora continua (continuo)
Esta no termina nunca. Cadencia operativa semanal:
- Review de consultas no resueltas: las que el cliente reescaló o abandonó. Ajustar prompts, agregar artículos al Help Center, reentrenar intents.
- Refresh de la base de conocimiento: cada feature release o cambio de pricing debe propagarse a la base de la IA en menos de 24 horas.
- Monitoreo de drift de CSAT post-deflection: si baja 5 puntos versus el baseline, pausar nuevas automatizaciones e investigar.
- A/B testing de prompts: la diferencia entre un prompt de sistema mediocre y uno bueno es 10-15 puntos de deflection con el mismo modelo.
Si todo esto suena a un proceso operativo permanente, es porque lo es. La buena noticia es que es un proceso operativo predecible y que escala. La menos buena es que muchas empresas SaaS no tienen la capacidad interna para sostenerlo, y ahí es donde un setup managed (más sobre esto al final) tiene sentido.
KPIs para monitorear el sistema
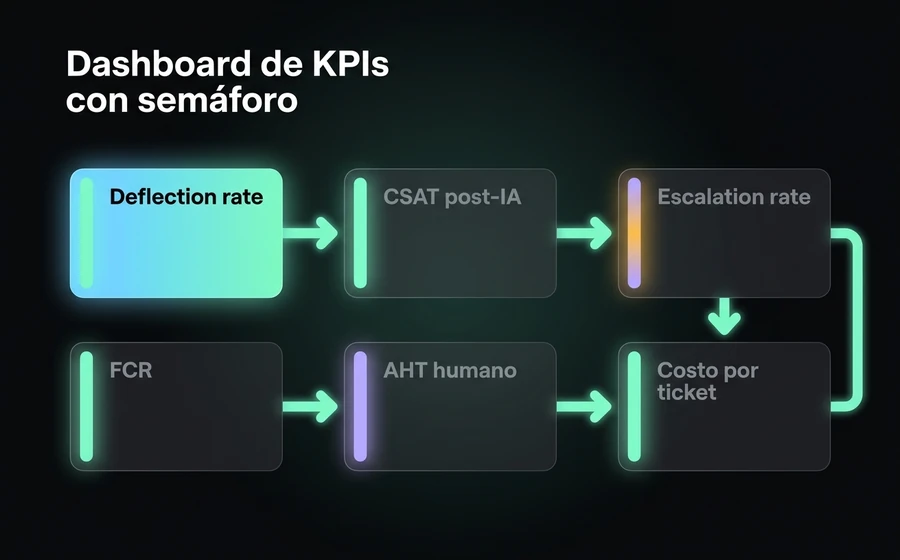
Acá está el dashboard mínimo que un Head of Support debería tener para operar este sistema. Los seis KPIs core, con sus umbrales de referencia para SaaS B2B maduro:
| KPI | Qué mide | Verde | Amarillo | Rojo |
|---|---|---|---|---|
| Deflection rate | % consultas resueltas sin escalar | >50% | 30-50% | <30% |
| CSAT post-deflection | Satisfacción tras interacción con IA, sin escalado | ≥CSAT general | -5 a -10pts | <-10pts |
| Escalation rate | % consultas escaladas a humano | <40% | 40-60% | >60% |
| First Contact Resolution (FCR) | % tickets resueltos en primer contacto (humano + IA) | >75% | 60-75% | <60% |
| AHT humano (con Copilot) | Tiempo promedio del agente humano | -25% vs baseline | -10 a -25% | sin mejora |
| Costo por ticket | OPEX total soporte / tickets totales | -30% vs baseline | -10 a -30% | sin mejora |
Algunas notas sobre interpretación:
- Deflection rate y CSAT post-deflection siempre se miran juntas. Subir uno tirando el otro no es ganar.
- FCR es la métrica que se descuida más. Un ticket que se resuelve "rápido" porque el cliente abandonó no es un ticket resuelto. Mide FCR a 48h, no a 24h.
- AHT humano con Copilot debe bajar 25-40% según McKinsey y benchmarks propios. Si no baja, el Copilot no está implementado bien (probablemente no le pasa el contexto completo al humano). Mira AHT en WhatsApp: benchmarks para más contexto sobre cómo medir AHT en canales conversacionales.
- Costo por ticket es la métrica que importa al CFO. Si quieres justificar la inversión, está bueno tener un modelo de ROI armado con anticipación, lo escribimos en detalle en ROI de un chatbot: la fórmula completa.
Adicionalmente, conviene tener dos métricas de salud del sistema:
- % de consultas no entendidas por la IA: si supera el 15%, hay un problema de cobertura de la base de conocimiento.
- Latencia promedio de respuesta del Agente de IA: si supera los 8 segundos, los clientes empiezan a abandonar antes de leer.
Por qué AsisteClick (y cuándo conviene managed service)
Llegaste hasta acá, lo cual es buena señal. Antes del cierre, una observación honesta: muchas empresas SaaS intentan implementar esto self-serve y se traban. No es por falta de tecnología (las herramientas existen y son accesibles), es por la curva de operación: entrenar un bot NLP bien, montar un RAG funcional, ajustar prompts iterativamente, sostener el loop de mejora continua, integrar con tu stack actual (Zendesk/Intercom/Freshdesk vía API, datos de cuenta, single sign-on). Eso requiere un perfil que pocas empresas SaaS de 50-500 empleados tienen full-time en el equipo.
AsisteClick ofrece este sistema como managed service: nuestro equipo se encarga del setup de las tres capas, el entrenamiento del bot NLP sobre tu histórico real, la conexión del Agente de IA con tu base de conocimiento (vía AsisteGPT y AsisteCopilot), las integraciones con tu CRM/billing, y el loop operativo semanal. Tu equipo se enfoca en el producto y en los clientes; nosotros nos encargamos de bajar el volumen de tickets sin que tengas que contratar un equipo interno de Conversational AI Engineers.
Si ya tienes un equipo técnico que quiere implementar esto self-serve, nuestra plataforma y la API de integración están disponibles. Si prefieres delegar el setup y la operación, hablamos de un alcance de proyecto con onboarding asistido.
En cualquiera de los dos modos, el objetivo es el mismo: que en seis meses el reporte de soporte muestre un deflection rate de 45-60% con CSAT estable o mejor, costo por ticket en caída, y un equipo humano que dedica su tiempo a las consultas que de verdad lo necesitan.
Preguntas frecuentes
¿Cuánto se tarda en ver resultados de reducción de tickets?
Los primeros resultados se ven entre 30 y 60 días si se siguen las cuatro fases del roadmap. La Fase 2 (self-service + bot NLP) entrega entre 25% y 40% de deflection rate en seis a ocho semanas. La Fase 3 (Agente de IA generativo + Copilot) suma entre 15 y 25 puntos adicionales en los siguientes tres meses. Esperar resultados pillar antes de 30 días es poco realista; pasar de seis meses sin ver mejora indica un problema de implementación, no de tecnología.
¿Qué deflection rate puedo esperar realista para un SaaS B2B?
Con un bot NLP solo, el deflection rate realista está entre 15% y 25%. Sumando un Agente de IA generativo con RAG sobre la base de conocimiento, llega a 40% a 55%. Con la operación madura (capas 1-2-3 trabajando seis meses con loop de mejora continua), 50% a 65%. Por encima de 70% el riesgo de degradar CSAT crece rápido, y por encima de 80% generalmente la medición no es honesta o se están automatizando consultas que no deberían automatizarse.
¿Es compatible con Zendesk, Intercom o Freshdesk?
Sí, AsisteClick se integra vía API con los help desks principales. La integración típica deja el sistema de tickets (Zendesk, Intercom, Freshdesk) como sistema de registro y agrega la capa conversacional de AsisteClick por encima: el cliente interactúa con el Agente de IA por WhatsApp, webchat, email o el canal que use, y los tickets escalados aparecen en tu help desk actual con todo el contexto previo. No requiere reemplazar la herramienta existente.
¿Qué pasa con los tickets técnicos complejos que no se pueden automatizar?
Los tickets técnicos complejos (errores reales, comportamiento inesperado, integraciones custom) no se auto-resuelven y no deberían intentar auto-resolverse. Lo que sí cambia es el rol del Agente de IA: en lugar de intentar responder, hace el triage (captura el problema, datos de la cuenta, pasos para reproducir) y escala al humano con un ticket pre-armado. El Copilot reduce el AHT del agente humano un 25% a 40% sobre esa categoría porque arranca con contexto completo en lugar de cero.
¿Necesito un equipo técnico interno para implementar esto?
Depende del modo. En modo self-serve sí: necesitas al menos un perfil que entienda APIs, integraciones, prompt engineering y operación de soporte. En modo managed service con AsisteClick, no: nuestro equipo se encarga del setup técnico, el entrenamiento del bot, la conexión con tu base de conocimiento y la operación del loop semanal. La decisión típica es: si ya tienes un equipo de Conversational AI o un CTO con bandwidth, self-serve funciona; si no, managed service evita seis meses de curva de aprendizaje.
¿Y si el Agente de IA da una respuesta incorrecta a un cliente?
Tres protecciones por capas: (1) escalado obligatorio a humano cuando la confianza del modelo está por debajo de un umbral configurado o cuando aparecen palabras gatillo (cancelación, queja formal, ejecutivo); (2) audit log completo de cada interacción para review manual semanal; (3) feedback loop del cliente directamente (un thumbs up/down después de la respuesta) que se incorpora al reentrenamiento. El caso Klarna es ilustrativo precisamente porque parecen haber subdimensionado esto: respuestas incorrectas en producción sin guardrails ni audit terminan en problemas de marca. La arquitectura de 3 capas con escalado siempre visible es la red de seguridad.
Conclusión
Reducir tickets de soporte SaaS con un Agente de IA no es una cuestión de tecnología, es una cuestión de arquitectura, medición y disciplina operativa. La tecnología hoy permite llegar a 45-60% de deflection rate en seis meses con CSAT estable; lo que separa a las empresas que lo logran de las que no, es haber medido antes de automatizar, haber respetado las tres capas en orden, y haber sostenido el loop de mejora semanal.
Si quieres ver cómo se ve esta arquitectura aplicada a tu caso —con AsisteGPT, AsisteCopilot y la integración con tu help desk actual—, mira la plataforma de Agentes de IA de AsisteClick o agenda una demo y te mostramos qué porcentaje de tu volumen de tickets actual sería razonable deflectear en los próximos seis meses.
Sigue leyendo
- Klarna y el error de IA en customer service — análisis completo del caso que ilustra cada anti-patrón
- Copilot de IA para agentes en tiempo real — cómo la IA potencia al humano sin reemplazarlo
- Las 3 capas de conocimiento de un Agente de IA — el detalle técnico del RAG en la Capa 3