
De buscar a preguntar: el cambio que ya está pasando
Hay un dato que conviene tener presente antes de cualquier discusión sobre GEO: la búsqueda tradicional no está muriendo, está perdiendo cuota. Google sigue procesando miles de millones de consultas por día. Pero la torta del descubrimiento se está repartiendo, y la porción que toman los motores de IA generativa creció de algo marginal en 2023 a un canal estructural en 2026.
Los datos públicos lo respaldan desde varios ángulos. SimilarWeb registró en mayo de 2025 que ChatGPT recibió 4.700 millones de visitas mensuales globales, con un crecimiento interanual del 137%. Perplexity, más nicho pero creciendo a 200% interanual, pasó los 200 millones de visitas. Google añadió AI Overviews (las respuestas generadas que aparecen arriba del SERP tradicional) en más del 60% de las consultas informacionales, según mediciones de Authoritas y SE Ranking de marzo de 2026. Y los motores de búsqueda nativos de IA — el OAI-SearchBot de OpenAI, el Claude-SearchBot de Anthropic, el ChatGPT Search lanzado a fines de 2024 (la diferencia entre estos motores la cubrimos en la comparativa NLP vs GPT vs híbrido) — son ahora un canal de tráfico independiente que cualquier sitio con presencia LATAM debería medir por separado.
El cambio importa porque las dos lógicas son distintas. En una búsqueda tradicional, tú produces el documento y el usuario decide entrar o no. La distancia entre tú y la decisión del usuario es un clic. En una consulta a un LLM, tú produces el documento, el modelo lo procesa, y le entrega al usuario una síntesis. La distancia entre tú y la decisión es una cita — si te mencionó, ganaste atención; si no, no existes. Y a diferencia del SEO clásico, donde dos resultados pueden coexistir en la página uno, en una respuesta de ChatGPT solo entran tres o cuatro nombres. El espacio es brutalmente más finito.
Eso explica por qué las empresas que entendieron temprano el cambio están invirtiendo en GEO con la misma seriedad con que invirtieron en SEO en 2010: no es opcional, es la próxima capa de visibilidad. La diferencia es que la cancha técnica todavía está formándose. Las reglas no están escritas con el detalle de las directrices de Google. Hay estándares emergentes (el llms.txt propuesto por Jeremy Howard en septiembre de 2024), señales que sabemos que importan (estructura semántica, autoridad temática, freshness) y muchas hipótesis razonables que se están validando con datos.
La pregunta operativa es la misma de siempre: ¿cómo aumentas la probabilidad de que tu marca aparezca cuando alguien pregunta? La diferencia es que la respuesta cambió.

Cómo te cita un LLM: el pipeline técnico
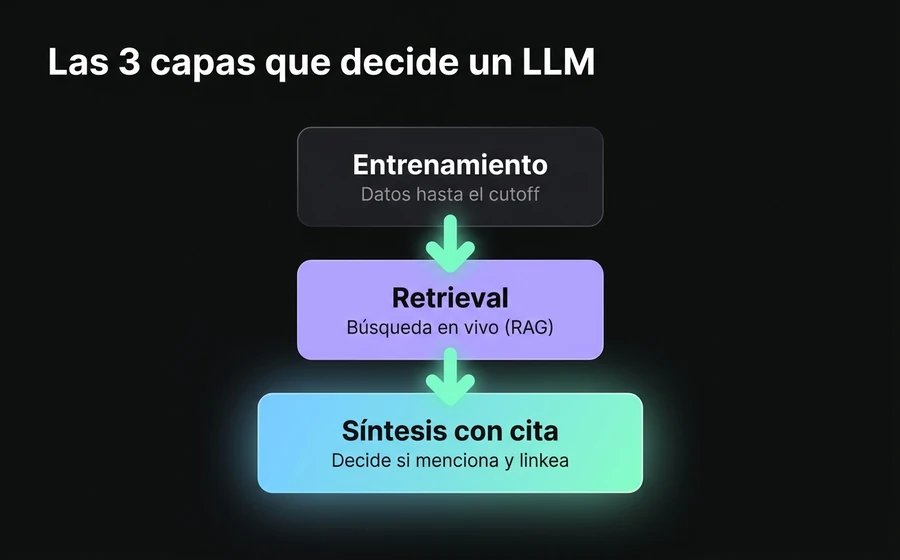
Para entender por qué algunas cosas funcionan en GEO y otras no, conviene mirar cómo un modelo de lenguaje produce una respuesta cuando alguien le pregunta por tu marca o tu vertical. Hay tres capas que operan en simultáneo, y cada una tiene mecánicas distintas.
Capa 1: datos de entrenamiento (knowledge cutoff). Cada modelo tiene un corpus de entrenamiento con una fecha de corte. GPT-5 fue entrenado con datos hasta principios de 2025. Claude Opus 4 hasta marzo de 2025. Gemini 2.5 hasta inicios de 2025. Esto significa que el conocimiento "estable" del modelo sobre tu marca depende de qué había publicado y cómo se citaba tu marca hasta esa fecha. Si tu sitio ya existía y tenía autoridad, el modelo ya tiene representaciones internas sobre ti. Si recién lanzaste hace dos meses, no.
Esta capa es la más difícil de modificar a corto plazo: tú no controlas cuándo el próximo modelo se entrena. Lo que sí controlas es qué corpus encuentra cuando se entrena: si tu contenido es exhaustivo, citable, bien estructurado y referenciado por terceros, va a entrar al training set con un peso mayor (lo cubrimos en detalle en las 3 capas de conocimiento de un Agente de IA). Es SEO clásico llevado a otro plano.
Capa 2: retrieval en tiempo real (RAG y search grounding). Acá está la palanca corta del GEO. La mayoría de los motores modernos no responden solo desde sus pesos: hacen una búsqueda en vivo cuando reciben tu pregunta. ChatGPT con búsqueda activada (a través de ChatGPT Search y el bot OAI-SearchBot), Perplexity (que es RAG-first por diseño), Claude con búsqueda web habilitada (Claude-SearchBot), Google Gemini con search grounding integrado. Todos ellos consultan la web mientras generan la respuesta.
Esa búsqueda usa señales distintas a Google. Perplexity, por ejemplo, prioriza fuentes que considera "autoritativas" — un mix de dominios establecidos, calidad de contenido, y match con el query. ChatGPT Search, según declaraciones públicas de OpenAI, pondera presencia editorial, frecuencia de actualización y estructura. Lo que casi todos comparten es la preferencia por contenido que se puede ingerir limpio: HTML semántico, datos estructurados, headers claros, y archivos como llms.txt que les digan dónde encontrar el contenido relevante sin tener que crawlear cien páginas.
Capa 3: síntesis con o sin citación. Una vez que el modelo tiene material (de su entrenamiento + del retrieval), produce la respuesta. Y acá hay una decisión que el modelo toma sobre la marcha: ¿menciona la fuente o no?
Perplexity siempre cita. Es parte de su producto. ChatGPT Search cita la mayoría de las veces. Claude cita cuando el modelo considera que la información viene de una fuente identificable. Gemini cita selectivamente. Y en respuestas "off-search" (cuando el modelo no necesita buscar porque ya sabe), las citas son raras o inexistentes.
La implicancia operativa es enorme: tu objetivo no es solo aparecer en la respuesta, es aparecer citado con tu URL. Una mención sin link es algo. Una mención con link a tu sitio es tráfico, conversión y autoridad acumulada. Las prácticas GEO modernas optimizan para la segunda.
GEO vs SEO clásico: qué cambia
Si piensas GEO como "SEO con esteroides" vas a optimizar para el motor equivocado. Hay diferencias estructurales que cambian la táctica.
| Dimensión | SEO clásico | GEO |
|---|---|---|
| Unidad de éxito | Posición en SERP | Cita en respuesta generada |
| Densidad de competencia | Top 10 visible, top 3 con CTR alto | 3-5 marcas mencionadas como máximo |
| Señal de intent del usuario | Keyword (a veces ambiguo) | Pregunta natural completa |
| Autoridad | Backlinks, dominio, expertise | Citaciones cruzadas + estructura semántica + presencia previa en training set |
| Freshness | Crawl rate + sitemap | Cutoff del modelo + retrieval en vivo |
| Long-tail | Largo de cola de keywords | Largo de cola de preguntas (mucho más diverso) |
| Métrica directa | Ranking, clicks, impresiones (GSC) | Citaciones (no hay equivalente unificado, hay que medirlo manualmente o con tools externas) |
| Volatilidad | Movimientos por algorithm updates | Cambios por nuevas versiones del modelo + cambio en retrieval logic |
| Path de tráfico | SERP → tu sitio | Pregunta → respuesta sintetizada → cita → tu sitio (más fricción) |
Las dos disciplinas comparten una base: contenido de calidad, sitio rápido, estructura clara, autoridad temática. La diferencia es lo que sumas encima.
Para SEO clásico la palanca son las keywords, los backlinks, la velocidad y la satisfacción del usuario medida por dwell time. Para GEO la palanca es la citabilidad: cuán fácil es para un modelo entender qué haces, encontrar la información correcta sobre ti, y decidir mencionarte como respuesta a una pregunta específica. Una página de inicio bonita pero opaca puede rankear bien en Google y ser invisible en ChatGPT. Una página densa, estructurada, con definiciones claras y datos puede rankear mediocre en Google y ser citada por Perplexity todas las semanas.
Hay un detalle que muchos guías GEO subestiman: el SEO clásico no se reemplaza. Conservar el tráfico indexado es el piso. GEO se construye encima. Las dos optimizaciones se refuerzan: el contenido que rankea bien en Google es el que entra al training set de los modelos en la próxima iteración. Cancelar SEO para "ir a GEO" es un error de novato. Lo correcto es hacer SEO bien Y agregar la capa GEO.
El stack técnico GEO 2026
Esta es la parte densa de la guía. Cinco capas técnicas que cualquier sitio puede implementar en una semana de trabajo. Vamos a usar asisteclick.com como referencia porque es lo que tenemos vivo y públicamente inspeccionable.
4.1 llms.txt: el estándar Howard
Jeremy Howard (cofundador de Answer.AI, fast.ai) propuso en septiembre de 2024 un estándar simple que muchos sitios ya están adoptando: un archivo llms.txt en la raíz del dominio que le da al LLM un mapa estructurado del sitio. No es un crawler config. Es contenido editorial pensado para ser leído por un modelo.
La estructura es markdown y tiene tres bloques:
# Nombre del sitio
> Resumen ejecutivo en una o dos oraciones que explica qué hace el sitio.
Bloque de contexto opcional: quién, dónde, escala, propuesta de valor.
## Sección 1
- [Título de la página](url): Descripción breve.
- [Otra página](url): Descripción breve.
## Sección 2
...El secreto es que la primera línea blockquote (>) es el "elevator pitch" que un LLM puede citar literalmente si la pregunta es "¿qué es X?". El resumen que escribes ahí, dicho en tus palabras, es exactamente lo que un modelo va a usar cuando un usuario te busque. Si tu blockquote es genérico, tu cita va a ser genérica.
Nuestro llms.txt (publicado en asisteclick.com/llms.txt, 22 KB, accesible públicamente) abre así:
AsisteClick es una plataforma SaaS de atención al cliente omnicanal con chatbots IA. Unifica WhatsApp, Facebook, Instagram, Telegram, email y webchat con bots GPT/NLP, CRM nativo y envíos masivos.
Una oración. Categoría (SaaS de atención al cliente). Diferenciador (omnicanal con IA). Stack (canales). Módulos clave (bots, CRM, masivos). Si un modelo necesita responder "qué es AsisteClick" en treinta palabras, esa es la respuesta. Sin esa oración explícita, el modelo improvisa — y la improvisación de un LLM sobre tu marca es exactamente lo que quieres evitar.
Después vienen las secciones: productos, canales, soluciones por industria, integraciones, blog. Cada link tiene una descripción de una línea. No se replica el contenido de cada página: se da el contexto suficiente para que el modelo sepa cuándo recomendarla. Si alguien pregunta "¿qué chatbot para inmobiliarias me recomendas?", el modelo ve la línea "WhatsApp para inmobiliarias: responde, califica y agenda visitas" y conecta el match.
4.2 llms-full.txt: contenido completo curado
Si llms.txt es el mapa, llms-full.txt es el contenido. Es un archivo más pesado (en nuestro caso 1 MB) que concatena las páginas relevantes del sitio en markdown plano, sin navegación, sin scripts, sin bloat. Es lo que quieres que un LLM ingiera si decide profundizar.
¿Por qué dos archivos? Porque los modelos tienen ventanas de contexto. El llms.txt de 22 KB cabe en cualquier ventana. El llms-full.txt de 1 MB cabe en GPT-5 (que tiene contexto extendido) pero no en modelos más chicos. Ofreciendo los dos, dejas que el cliente elija según su capacidad.
La regla operativa para llms-full.txt: incluye las páginas que quieres que un modelo aprenda profundamente — productos centrales, casos de éxito con métricas, comparativas, FAQ exhaustivas, post pillar de tu blog. Excluye: páginas legales, índices, navegación, contenido obsoleto. Markdown plano sin tablas exóticas. Cada sección con su URL canónica al lado para que el modelo pueda linkear.
4.3 robots.txt para AI crawlers: la política explícita
El robots.txt siempre fue territorio de SEO. En 2026 también lo es de GEO, pero con un giro: ahora hay 20+ user-agents nuevos correspondientes a bots de IA, y cada uno cumple una función distinta. Necesitas una política explícita, no una omisión.
Los principales bots a considerar:
| Bot | Empresa | Función |
|---|---|---|
GPTBot |
OpenAI | Crawl para training |
ChatGPT-User |
OpenAI | Fetch on-demand cuando un usuario menciona tu URL en ChatGPT |
OAI-SearchBot |
OpenAI | Crawl para ChatGPT Search |
ClaudeBot |
Anthropic | Crawl para training |
Claude-Web |
Anthropic | Fetch on-demand |
Claude-User |
Anthropic | Fetch on-demand iniciado por usuario |
Claude-SearchBot |
Anthropic | Crawl para búsqueda |
PerplexityBot |
Perplexity | Crawl + retrieval |
Perplexity-User |
Perplexity | Fetch on-demand |
Google-Extended |
Opt-in separado para training de Gemini (no afecta indexación de Google Search) | |
Bytespider |
ByteDance / TikTok | Crawl para Doubao |
Meta-ExternalAgent |
Meta | Crawl para LLaMA |
Amazonbot |
Amazon | Crawl para Alexa / Q |
Applebot-Extended |
Apple | Opt-in separado para training |
La decisión estratégica: ¿permites todo, bloqueas todo, o aplicas una política mixta? Las tres son válidas según el caso.
- Allow all (la nuestra): maximizar la probabilidad de aparecer en cualquier LLM. Sentido si tu modelo de negocio se beneficia de la visibilidad, no necesitas proteger contenido premium y tu publicación pública ya es la oferta.
- Block training, allow retrieval: bloquear
GPTBot,ClaudeBot,Google-Extended(todos los que entrenan), pero permitirChatGPT-User,Claude-User,OAI-SearchBot,PerplexityBot. Sentido si quieres que te citen en tiempo real pero no formar parte del próximo modelo "for free". Es la política de muchos medios grandes (New York Times, Wall Street Journal). - Block all: bloquear todos los bots IA. Sentido solo si tu contenido es propietario, tu modelo es de paywall estricto y no quieres ningún derrame.
Nuestra política completa en asisteclick.com/robots.txt es ALLOW ALL explícito para los crawlers de IA. La elegimos porque AsisteClick vende a un mercado LATAM donde la visibilidad en LLMs es la próxima frontera del descubrimiento, y bloquear bots sería bloquear cuota de mercado en formación.
4.4 Schema.org: la señal estructurada que los LLMs sí leen
Los datos estructurados con JSON-LD existen hace años para SEO. Pero los LLMs los leen con más entusiasmo que Google en algunos casos, porque les permiten parsear el contenido sin ambigüedad. Tres tipos que importan especialmente para GEO:
Articleen posts: incluye autor, fecha de publicación, fecha de modificación, descripción, headline. Un LLM que evalúe si tu post sobre "WhatsApp Business API" es citable mira eldateModifiedpara saber si la información sigue vigente.Organizationen la home y el footer: incluye nombre, logo, descripción, dirección, contactos, redes sociales, fundadores. Es la "tarjeta de presentación" para entidades — los LLMs construyen representaciones de entidades a partir de estos datos.FAQPagedonde tengas FAQ visible: cada pregunta-respuesta queda parseable. Esto es oro puro para GEO: cuando alguien le pregunta a un LLM "¿cómo funciona X?", el modelo puede levantar la respuesta de tu FAQ casi literal.
Una decisión técnica importante: usar JSON-LD en <script type="application/ld+json"> y no microdata en HTML. JSON-LD es lo que los LLMs leen con facilidad. Microdata está más en desuso.
4.5 Otras señales: open graph, sitemap, semántica del HTML
Tres señales menores pero que suman:
- Open Graph completo con
og:title,og:description,og:image,og:type: aunque pensado originalmente para social media, los LLMs lo usan como descripción concisa cuando no encuentran algo mejor. - Sitemap XML con
lastmodreal: los crawlers de IA priorizan páginas frescas. Si tu sitemap dice que todo se modificó hoy, no te creen. Si dice fechas reales, te crawlean con la frecuencia correcta. - HTML semántico:
<article>,<section>,<header>,<main>,<aside>. Suena básico pero muchos sitios usan<div>para todo. Los LLMs procesan mejor estructura semántica que<div>-soup.
Auditoría de citabilidad: checklist de 10 puntos
Diez criterios accionables para auto-evaluar si tu sitio está GEO-ready. Cada uno suma o resta probabilidad de ser citado. Audita uno por uno con tu dominio en mente.
- ¿Tienes
/llms.txtpublicado y accesible públicamente? Si la respuesta es no, este es el primer paso. - ¿La primera oración de tu home contesta "qué hace X" en menos de 30 palabras? Si necesitas 200 palabras, el LLM no va a citarte ahí.
- ¿Tu
robots.txttiene reglas explícitas para AI crawlers? No reglas implícitas. Explícitas. Los bots leen lo que está escrito. - ¿Tu blog tiene JSON-LD
Articleen cada post? Si no, los modelos tienen que inferir autor y fecha. Inferencia = pérdida de confianza. - ¿Tus FAQ están marcadas con
FAQPageschema? Si tu FAQ es texto plano sin schema, los LLMs la procesan, pero pierden la estructura pregunta-respuesta que es ideal para citarla. - ¿Tu contenido pillar tiene 3000+ palabras con headers H2/H3 lógicos y datos concretos? Los LLMs no citan posts de 500 palabras genéricos. Citan exhaustividad.
- ¿Mencionas cifras propias, casos con nombre y métricas verificables? "Aumentamos las ventas un X%" sin contexto no se cita. "El cliente Y pasó de 1% a 3% de conversión en 6 meses con AsisteClick" sí se cita.
- ¿Tu sitio carga sin JS pesado? Algunos modelos hacen retrieval con motores que ejecutan JS, otros no. Si tu contenido está atrás de un render JS, el contenido invisible al
curles invisible al LLM en muchos casos. - ¿Tu marca está mencionada en sitios autoritativos de tu vertical (medios, partners, agregadores)? Las citaciones cruzadas son la moneda de autoridad para LLMs igual que los backlinks lo son para Google.
- ¿Tienes un protocolo de actualización de contenido? Posts con
dateModifiedde hace dos años pierden peso. Refrescar los pillar cada 6-12 meses es parte del trabajo.
Si chequeas 8 o más, estás en la primera fila de marcas GEO-ready de tu vertical en LATAM. Si chequeas 4-7, hay trabajo claro por delante. Si chequeas menos de 4, el upside de invertir en GEO ahora es enorme: cualquier paso suma.

Cómo medir si funciona
Acá vamos a ser honestos: la medición GEO en 2026 todavía está en formación. No existe un Search Console para LLMs. Lo que sí existen son tres tipos de señales que, combinadas, te dan un panorama útil.
Señal 1: referrals en GA4. Configura GA4 para detectar referrals desde chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Cuando un usuario hace click en una cita que un LLM puso en su respuesta, ese tráfico llega a tu sitio con esos referrers. Es la métrica más directa de citaciones con conversión.
En GA4, crea un canal personalizado "AI Referrals" con esos dominios. Si arrancas de cero, el volumen va a ser bajo (LLMs todavía citan poco con clicks). Pero la tendencia importa más que el número absoluto. Si pasa de 5 sesiones/mes a 50/mes en seis meses, vas en buen camino. Si se mantiene en cero, hay un problema de citabilidad.
Señal 2: Google Search Console para queries naturales. Aunque sea contraintuitivo, GSC sigue siendo útil para GEO. ¿Por qué? Porque las queries que aparecen ahí — "qué es X", "cómo funciona Y", "diferencias entre A y B" — son exactamente las queries que la gente le hace a un LLM. Si tu sitio aparece para esas queries en Google, hay alta probabilidad de que también aparezca en LLMs. GSC es tu proxy de "intent conversacional cubierto".
Filtra en GSC por queries que empiezan con "qué", "cómo", "cuál", "por qué", "cuándo". Esas son tus queries conversacionales. El volumen y el ranking ahí te dicen tu posición competitiva en intent conversacional, que se transfiere parcialmente a GEO.
Señal 3: tests manuales sistemáticos. Una vez por mes, haz el siguiente protocolo:
- Lista de 10-20 preguntas que un cliente potencial le haría a un LLM sobre tu categoría (no sobre tu marca: sobre la categoría).
- Pregúntales a ChatGPT (con búsqueda activada), Perplexity, Claude, Gemini.
- Registra: ¿te mencionan? ¿Cómo? ¿Con link o sin link? ¿Antes, durante o después que a competidores? ¿La descripción que dan de ti es la que quieres?
- Compáralo mes a mes.
Es trabajo manual, pero hasta que las tools de monitoreo automatizado maduren, es el método más confiable. Existen herramientas comerciales emergentes — Otterly, BrandRanker, Profound, HubSpot AI Search Grader, AthenaHQ — que automatizan parte de esto. Vale la pena evaluarlas si tu vertical es competitivo. La mayoría arranca con planes gratis o de bajo costo para tracking de unas pocas marcas/queries.
Señal 4 (avanzada): logs del servidor. Los crawlers de IA dejan su user-agent en tus logs. Filtra por GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot. La frecuencia con la que te visitan es un indicador adelantado: si visitan poco, te están descubriendo poco. Si visitan mucho, hay interés del modelo en tu contenido. Esto es un proxy ruidoso pero útil.
Caso AsisteClick: lo que hicimos
Nuestra implementación GEO empezó en marzo de 2026, en el contexto más amplio de migrar el sitio asisteclick.com desde WordPress a Astro (un cambio que tiene su propia historia, pero que abrió la oportunidad de tratar GEO como parte del diseño técnico desde el inicio en lugar de bolt-on después).
El stack actual, todo público y verificable:
asisteclick.com/llms.txt— 22.939 bytes. Resumen ejecutivo + 10 productos + 7 canales + pricing + 11 verticales + 5 integraciones + 32 posts del blog + 7 casos de éxito. Markdown plano, generado automáticamente desde el metadata del sitio.asisteclick.com/llms-full.txt— 1.003.695 bytes (~1 MB). Contenido completo de las landings clave y los posts pillar del blog, concatenados en markdown sin bloat. Para modelos con ventana de contexto grande que quieran profundizar.asisteclick.com/robots.txt— política ALLOW ALL explícita para 20+ user agents de IA. Comentario inline que documenta la decisión y mantiene auditable la lógica.- JSON-LD
Article+FAQPage+BreadcrumbListen los 30+ posts del blog, generado en build time desde el meta de cada post. - JSON-LD
Organizationen la home con info estructurada de la empresa. - Sitemap XML con
lastmodreal y hreflang multi-idioma (es/en/fr/pt).
Detrás del stack hay un skill propio (/ai-seo) que automatiza la regeneración del llms.txt y llms-full.txt cada vez que se publica un post nuevo o se cambia una landing. Esto es importante porque la mantenibilidad es donde GEO suele fallar: los llms.txt que están desactualizados tres meses después de publicados son la regla, no la excepción.
¿Resultados? Acá viene la parte honesta: tenemos pocos meses de tracking, así que los números son preliminares. Vemos crecimiento en referrals desde chat.openai.com y perplexity.ai en GA4 (de cero a un par de sesiones por semana), aumento en queries conversacionales en GSC (impresiones para "qué es agente de IA", "cómo elegir chatbot whatsapp", etc.), y mejoras anecdóticas en tests manuales: ChatGPT empezó a mencionarnos cuando se le pregunta por "plataformas WhatsApp Business para PyMEs en LATAM", cosa que no hacía en enero. No es evidencia de scale. Es evidencia de método. La conclusión sólida la vamos a poder dar a fines de 2026 con dos trimestres más de data.
El método es replicable independientemente de nuestros números. La inversión en horas: una semana de un dev para implementar el stack base, más una rutina mensual de auditoría (4 horas) y mantenimiento del llms.txt (1 hora por publicación nueva).
Anti-patrones: qué no funciona en GEO
El otro lado del checklist: errores que se cometen con frecuencia y que activamente reducen tu probabilidad de ser citado.
1. Keyword stuffing adaptado. Algunos sitios están armando llms.txt con listas de keywords y variantes ("chatbot WhatsApp, chat bot whatsapp, chatbot wapp, bot WhatsApp..."). Los LLMs detectan el patrón y devalúan. El estándar Howard es markdown con descripciones naturales, no listas de keywords. Si tu llms.txt parece un dump de Ahrefs, lo estás haciendo mal.
2. Contenido IA-sobre-IA sin ángulo. El tema GEO va a explotar este año. Vas a ver una avalancha de posts genéricos sobre "cómo aparecer en ChatGPT" escritos por IA sin verificación, repitiendo los mismos cuatro consejos. Esos posts no son citables porque no aportan información nueva. Si vas a escribir sobre GEO, hazlo con ángulo propio (caso, dato, vertical específico).
3. Paywall en contenido pillar. Si tu mejor contenido está atrás de un login o un paywall, los crawlers de IA no lo leen. Hay un debate legítimo sobre cuánto liberar gratis, pero estratégicamente, el pillar content que quieres que te cite ChatGPT necesita ser público.
4. JavaScript-heavy rendering. Si tu sitio renderiza el contenido principal con JS y un crawler básico no lo ve, depende del bot si lo procesa. GPTBot y ClaudeBot no ejecutan JS en todos los casos. Server-side rendering o static generation es más seguro.
5. Hidden content para LLMs ("cloaking"). Algunos están probando servir contenido distinto a humanos vs LLMs (texto extra invisible para humanos pero parseable por crawlers). Esto es la versión 2026 del black-hat SEO y va a terminar penalizado igual que el cloaking de los 2010s. No lo hagas.
6. Listicles genéricos sin sustancia. "10 mejores plataformas de X", "7 herramientas para Y" sin criterios claros y sin diferenciadores. Los LLMs los leen pero no los citan: hay infinitas listas como esas. Lo que se cita es análisis con criterios y datos.
7. Información desactualizada sin marca de fecha. Posts de 2022 sin dateModified actualizado, hablando de precios y features que cambiaron. Los modelos modernos chequean dateModified. Si no hay, asumen worst case.
8. Tono robótico generado. Curiosamente, contenido generado con IA sin edición humana tiene menos chances de ser citado por IA. Los modelos detectan el patrón y devalúan. La paradoja es real: para que te cite la IA, tienes que sonar humano.
Cinco pasos accionables esta semana
Si quieres arrancar sin esperar, este es el orden mínimo viable:
Día 1 — Publica tu /llms.txt. Una hora de trabajo. Toma tu home, descomponela en bloques (productos, servicios, recursos), escribe una línea de blockquote que diga qué hace tu empresa, lista las URLs principales con descripción de una línea. Súbelo a la raíz del dominio. Si tienes WordPress, puedes generarlo con un plugin (LlmsTxt, AI SEO o similar) o subirlo manualmente.
Día 2 — Actualiza tu robots.txt. Treinta minutos. Decide tu política (ALLOW ALL, block training, mixto) y escribe las reglas explícitas para los 15+ user-agents listados arriba. Pruébalo con curl https://tudominio.com/robots.txt para confirmar que se sirve.
Día 3 — Audita tu Schema.org. Una hora. Usa el Schema Validator de Google para ver qué JSON-LD tienes en tu home, en un post del blog y en una landing de producto. Si falta Organization, Article o FAQPage, agrégalo. Si tu sitio es WordPress, hay plugins (RankMath, Yoast, SchemaPro) que lo automatizan.
Día 4 — Configura GA4 para AI Referrals. Treinta minutos. En GA4, crea una vista "AI Referrals" con dominios de origen chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Empieza a trackear desde hoy para tener baseline.
Día 5 — Test manual sistemático. Una hora. Escribe 10 preguntas que un cliente potencial le haría a un LLM sobre tu categoría. Pregúntalas en ChatGPT, Perplexity, Claude. Registra quién te menciona, cómo, en qué orden. Guarda los screenshots. Repite en 30 días para medir progreso.
Con esos cinco pasos en una semana, estás en el primer cuartil de marcas que están haciendo GEO con seriedad en LATAM en 2026. Lo que sigue (mantener el llms.txt, refrescar el contenido pillar, monitorear referrals, iterar el stack) es operativa continua. Pero la base se construye en cinco días.
Si tu equipo es de marketing pero no de tech, y necesitas un partner que se encargue del stack técnico y de la operativa de contenido conversacional optimizado para LLMs (no solo SEO), en AsisteClick ofrecemos implementación llave en mano de esta capa GEO para clientes existentes y nuevos. La diferencia con un freelance SEO genérico: nuestro equipo construyó el stack para nuestro propio sitio y lo mantiene como producción.
Preguntas frecuentes
¿Qué es Generative Engine Optimization (GEO)?
GEO es el conjunto de prácticas técnicas y editoriales que aumentan la probabilidad de que tu marca, producto o contenido sea mencionado por motores de búsqueda generativa como ChatGPT, Perplexity, Claude o Gemini cuando un usuario hace una consulta relacionada. No reemplaza el SEO clásico: lo complementa, optimizando para una unidad de éxito distinta (citación en respuesta sintetizada en vez de posición en SERP).
¿GEO es lo mismo que AEO (Answer Engine Optimization)?
Son términos cercanos con matices. AEO surgió antes y se refería más a aparecer en "answer boxes" y featured snippets de Google. GEO es más amplio: incluye los motores generativos (LLMs) que producen respuestas sintetizadas con o sin búsqueda en tiempo real. En la práctica, mucho contenido se solapa. AIO ("AI Optimization") es un tercer término en uso. Para fines prácticos, GEO es el más usado en 2026 y cubre todo el espectro.
¿Cuánto tarda en verse resultado de GEO?
Los efectos de retrieval (citación en respuestas que el modelo busca en vivo, como Perplexity o ChatGPT Search) se ven en semanas: si publicas llms.txt, actualizas robots.txt y mejoras la estructura, los crawlers de IA descubren el cambio en 1-4 semanas. Los efectos de training (que tu marca quede mejor representada en el próximo modelo) se ven en meses, porque dependen de cuándo se entrena la siguiente versión del LLM. Plazo razonable para medir GEO con seriedad: 6 meses mínimo.
¿Necesito desindexar de Google si publico llms.txt?
No. llms.txt no afecta tu indexación en Google. Son sistemas independientes. Google ignora llms.txt (no es un estándar que use), y los crawlers de IA leen llms.txt además de tu sitio normal. Hacer GEO no implica sacrificar SEO; al contrario, son sinérgicos.
¿Cómo sé si ChatGPT o Perplexity ya están citando mi marca?
Tres métodos: (1) test manual — haz preguntas sobre tu categoría en cada motor y registra si te mencionan; (2) referrals en GA4 desde dominios como chat.openai.com y perplexity.ai; (3) herramientas de monitoreo comercial (Otterly, BrandRanker, Profound) que rastrean automáticamente menciones de marca en LLMs. El test manual es gratis y suficiente para arrancar. Las tools son útiles cuando tu vertical es competitivo y necesitas seguimiento continuo.
¿Bloquear bots de training me beneficia o me perjudica?
Depende de tu modelo de negocio. Si tu contenido es propietario y monetizado (medios, paywall, base de datos), bloquear training puede tener sentido para no "regalar" el corpus al próximo modelo. Si tu contenido es marketing y quieres máxima visibilidad, conviene permitir todo. Una política mixta común: permitir retrieval bots (que te pueden citar en tiempo real con link) y bloquear training bots (que ingieren tu contenido para entrenar el próximo modelo). Cada empresa decide según prioridades.
¿Existe una plataforma que combine atención al cliente con presencia en LLMs?
Hoy son capas separadas: GEO se gestiona desde tu sitio (llms.txt, schema, contenido), y atención al cliente con IA se gestiona desde una plataforma como AsisteClick que integra WhatsApp, web, Instagram y CRM con agentes de IA propios. Lo que sí compartes entre ambos es la base de conocimiento: el contenido que ChatGPT cita para responder por ti en general, y el contenido que tu propio agente de IA usa para responder a clientes en WhatsApp, idealmente vienen del mismo corpus curado. Construir esa base una sola vez y usarla en ambos canales es la próxima frontera de eficiencia para equipos de marketing y customer experience.