
El 5 de marzo de 2026, OpenAI lanzó GPT-5.4. Una semana después publicó las variantes mini y nano. En el catálogo de templates de Agentes de IA de AsisteClick conviven hoy los tres: cada uno resuelve un problema distinto, con perfiles de costo y latencia que difieren en un orden de magnitud.
Si estás construyendo un Agente de IA sobre WhatsApp, un copilot para tu equipo de atención o un subagente que resuelve una tarea puntual, la elección del modelo define el 70% de la economía del producto: costo por conversación, tiempo de respuesta percibido y tasa de resolución autónoma.
Esta guía compara GPT-5.4 mini vs nano vs default con datos oficiales de OpenAI, benchmarks publicados y casos concretos del catálogo de AsisteClick. Al final vas a saber exactamente qué modelo elegir para cada tipo de agente, cuánto te va a costar y cuándo conviene escalar al flagship.
La familia GPT-5.4: qué cambió respecto a GPT-5
GPT-5.4 es la primera familia que OpenAI lanzó con computer-use nativo integrado en el modelo base (no como tool externa), 1 millón de tokens de contexto en la versión flagship y un mecanismo de tool search que reduce el costo de tokens en tareas con muchas herramientas hasta un 47%.
Los tres modelos comparten:
- Knowledge cutoff: 31 de agosto de 2025.
-
Modalidades: entrada de texto e imagen, salida de texto. Audio y video no soportados
(para audio sigues necesitando
gpt-4o-audioo Whisper). - Capacidades de API: function calling, structured outputs, streaming, parallel tool use.
- Tool use: web search, file search, code interpreter, image generation, skills, MCP.
Lo que cambia entre ellos es potencia de razonamiento, tamaño de contexto, costo por token y latencia. Y esa diferencia es la que te obliga a pensar como arquitecto antes de tirar un prompt.
Especificaciones oficiales: las 3 variantes en una tabla
Datos extraídos de la documentación oficial de OpenAI al 19 de abril de 2026.
| Especificación | gpt-5.4 | gpt-5.4-mini | gpt-5.4-nano |
|---|---|---|---|
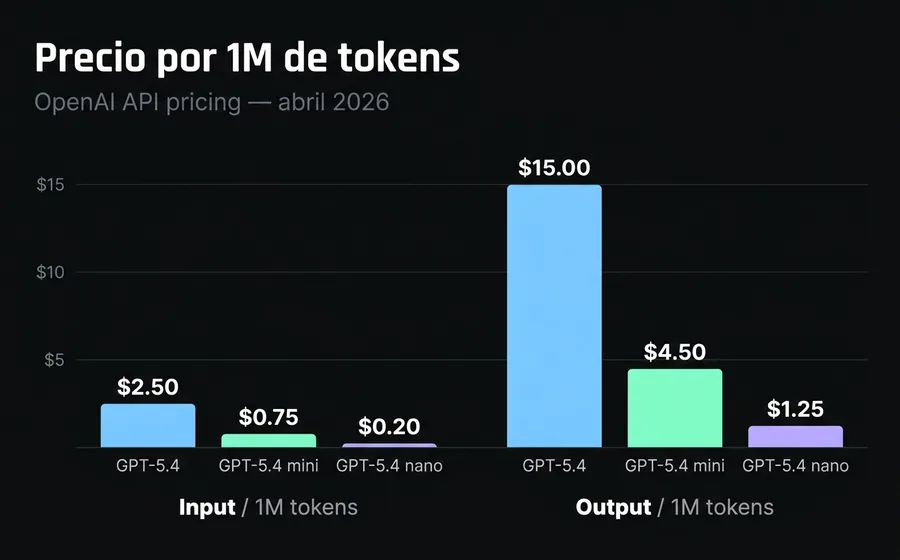
| Input / 1M tokens | $2.50 | $0.75 | $0.20 |
| Output / 1M tokens | $15.00 | $4.50 | $1.25 |
| Cached input / 1M tokens | $0.25 | $0.075 | $0.02 |
| Context window | 1.050.000 | 400.000 | 400.000 |
| Max output tokens | 128.000 | 128.000 | 128.000 |
| Function calling | Sí | Sí | Sí |
| Structured outputs | Sí | Sí | Sí |
| Computer use nativo | Sí | Sí | No |
| Tool search (optimización) | Sí | Sí | No |
| Modalidades entrada | Texto + imagen | Texto + imagen | Texto + imagen |
| Reasoning effort | none / low / medium / high / xhigh | low / medium / high | low / medium / high |
Dos detalles que suelen pasarse por alto:
El precio se duplica después de 272.000 tokens de prompt en el flagship. Si cargas un documento largo o un historial extenso, el input pasa de $2.50 a $5.00 por millón de tokens. Esto hace que el "1M de contexto" del flagship sea más un techo arquitectónico que una invitación a mandar prompts gigantes.
El cached input es la palanca económica más grande. En el mini, un token cacheado cuesta $0.075/1M frente a $0.75/1M del input normal. Si tu agente tiene un system prompt largo que se reutiliza en cada conversación (que es lo típico), cachearlo baja el costo efectivo entre 60% y 80%.
El parámetro que nadie explica: reasoning_effort
GPT-5.4 introdujo un parámetro que redefine cómo pagas por inteligencia: reasoning_effort.
Controla cuánto "piensa" el modelo antes de responder. Los valores son none, low, medium, high y
xhigh (solo flagship soporta xhigh).
Cada nivel consume tokens de razonamiento invisibles que tú pagas como output, pero que no aparecen en
la respuesta final. Es decir: con high, el modelo puede gastar 2.000-5.000 tokens internos
antes de escribir la primera palabra visible.
Heurística práctica:
-
noneolow: respuestas conversacionales, FAQ, saludos, clasificación simple. El modelo responde casi instantáneamente. -
medium: el default razonable. Atención al cliente, calificación de leads, triage. Hay un paso de análisis pero se mantiene responsive. -
high: tareas con múltiples pasos o ambigüedad. Orquestación de subagentes, diagnóstico técnico, negociación. -
xhigh: reservado para agentic workflows largos donde un error cuesta más que cinco segundos de latencia. Compliance, decisiones financieras, código crítico.
En el catálogo de AsisteClick, el orquestador multi-agente usa gpt-5.4-mini con
reasoning_effort=high porque debe decidir a qué subagente delegar. Un resumidor de
conversaciones usa low porque la tarea es mecánica.
Benchmarks oficiales: dónde rinde cada variante
OpenAI publicó resultados verificados en los benchmarks estándar de la industria al momento del release.
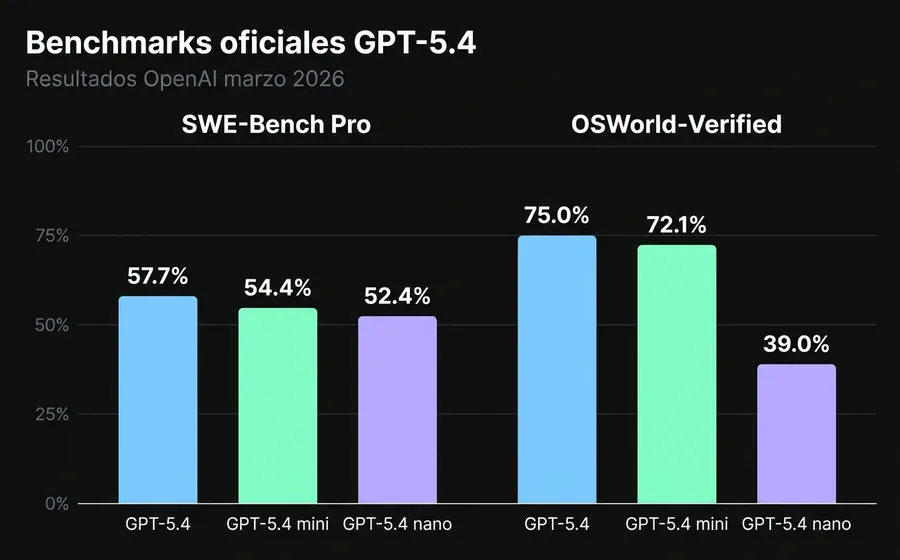
SWE-Bench Pro (tareas de ingeniería de software reales):
- gpt-5.4: 57.7%
- gpt-5.4-mini: 54.4%
- gpt-5.4-nano: 52.4%
- gpt-5-mini (legacy): 45.7%
OSWorld-Verified (navegación de entornos de escritorio, proxy de "computer use"):
- gpt-5.4: 75.0% (supera desempeño humano promedio, 72.4%)
- gpt-5.4-mini: 72.1%
- gpt-5.4-nano: 39.0%
La lectura importante no es "quién gana", sino dónde rompe cada modelo. Entre flagship y mini hay 3.3 puntos en coding y 2.9 en computer use. Entre mini y nano hay solo 2 puntos en coding, pero 33 puntos en computer use. Nano no está diseñado para tareas agénticas complejas: es un clasificador y extractor de alto volumen que casualmente entiende lenguaje natural.
Si tu agente necesita manejar GUIs o ejecutar pasos multi-tool con estado, mini es tu piso. Nano nunca
va a cerrar esa brecha aunque le subas reasoning_effort.
Precio real: cuánto te cuesta operar cada modelo
El pricing por millón de tokens suena barato hasta que lo multiplicas por volumen. Hagamos la cuenta con un caso concreto: un Agente de IA en WhatsApp que procesa 10.000 conversaciones al mes, donde cada conversación tiene en promedio 6 turnos y 200 tokens por turno (mitad input, mitad output).
Eso da 6 millones de tokens input + 6 millones output mensuales.
Costo mensual estimado sin cacheo:
- gpt-5.4: $15 (input) + $90 (output) = $105/mes
- gpt-5.4-mini: $4.50 + $27 = $31.50/mes
- gpt-5.4-nano: $1.20 + $7.50 = $8.70/mes
Con cached input (system prompt reutilizado, asumiendo 80% cache hit):
- gpt-5.4-mini: $0.90 + $27 = $27.90/mes
- gpt-5.4-nano: $0.24 + $7.50 = $7.74/mes
Para un operador con 100.000 conversaciones/mes, la diferencia entre mini y flagship son $1.000 al mes. Para 1.000.000 de conversaciones, $10.000 al mes. La decisión del modelo es literalmente una decisión de margen operativo.
Cómo lo resolvemos en AsisteClick: los 3 tipos de agente y su modelo
Dentro del catálogo activo de AsisteClick hay 33 templates de Agentes de IA y copilots, clasificados en tres categorías. El modelo asignado a cada template no es arbitrario: responde a la relación entre complejidad de la tarea, latencia tolerable y costo por interacción.
Hoy el catálogo está en migración gradual hacia la familia 5.4. Los templates nuevos ya
arrancan en gpt-5.4-mini o gpt-5.4-nano. Los legacy (creados antes de marzo
2026) todavía corren sobre gpt-5-mini y se actualizan a medida que se revisan
individualmente, porque cambiar el modelo puede alterar el comportamiento del agente en producción.
Agentes IA autónomos (ai-agent) — 18 templates
Son agentes que conversan directamente con el cliente final en WhatsApp, webchat, Instagram u otros canales. Responden consultas, califican leads, agendan citas, gestionan pedidos o cobranzas.
Modelo recomendado: gpt-5.4-mini con reasoning_effort=medium.
Por qué: la conversación con un humano en WhatsApp tolera 1-3 segundos de latencia como máximo antes de que se sienta "lento". Mini con medium cae dentro de ese rango y mantiene calidad de razonamiento suficiente para el 95% de las interacciones. El flagship se justifica solo cuando el agente debe hacer agentic workflows (llamar 5+ tools en secuencia, razonar sobre documentos largos).
Ejemplos del catálogo:
-
Cobranzas IA (
ai-collections):gpt-5.4-mini, medium. Decide tono, cierra planes de pago, deriva casos complejos. En detalle, el template está alineado con lo que discutimos en chatbot de cobranzas WhatsApp para fintech y se conecta con integraciones como Loan Collection. -
Ventas IA (
ai-sales):gpt-5.4-mini, medium. Califica leads y agenda demos. Patrón explicado en calificar leads WhatsApp con chatbot IA. -
Orquestador Multi-Agente (
ai-orchestrator):gpt-5.4-mini, high. Es la única excepción donde sube reasoning porque debe elegir entre subagentes. -
Agendador con Calendarios API (
ai-asiste-booking):gpt-5.4-mini, medium, con code interpreter habilitado. Es el único template que usa code porque necesita calcular disponibilidad contra timezones y reglas de calendario. Lo detallamos en la landing de agendamiento de turnos.
Copilots (asistentes internos para agentes humanos) — 9 templates
Estos modelos no hablan con el cliente. Asisten al agente humano: sugieren respuestas, traducen mensajes, resumen conversaciones, detectan oportunidades de venta, desescalan situaciones tensas. El detalle completo del patrón está en copilots de agentes IA: respuestas en tiempo real.
Modelo recomendado por defecto: gpt-5.4-mini con
reasoning_effort=low o medium según la tarea.
La excepción interesante: el copilot de traducción en tiempo real
(copilot-translator) es el único template del catálogo que usa
gpt-5.4-nano. La traducción conversacional es determinística, no requiere razonamiento en cadena y
el agente humano está esperando el texto para mandarlo. Nano responde con la mitad de latencia de mini y
a un quinto del costo. Un copilot que se dispara 200 veces por hora de atención tiene que ser barato o
nada lo justifica.
Otros copilots del catálogo: email, resumen, KB, respuesta sugerida, test, desescalación, oportunidad de venta, notas internas.
Subagents (tools especializadas) — 6 templates
Son agentes que no conversan: ejecutan una acción puntual invocada por otro agente. Consultan facturación, integran con Zapier o n8n, procesan un checkout de MercadoPago, consultan el clima.
Modelo recomendado: gpt-5.4-mini con reasoning_effort=low.
Output breve, tarea determinística, se invocan muchas veces por sesión.
El subagent-weather es el único con image generation habilitado (para devolver el pronóstico
como imagen compuesta), detalle que muestra cómo cada template se configura quirúrgicamente según qué
tool necesita.
Matriz de decisión: qué modelo para qué caso
Si estás construyendo un Agente de IA desde cero y no sabes por dónde empezar, esta tabla resuelve el 90% de los casos.
| Caso de uso | Modelo | Reasoning | Por qué |
|---|---|---|---|
| Clasificación de intents | gpt-5.4-nano | low | Tarea determinística, alto volumen |
| Extracción de datos estructurados | gpt-5.4-nano | low | Output schema fijo, structured outputs |
| Traducción en tiempo real | gpt-5.4-nano | low | Latencia crítica, sin razonamiento |
| Atención al cliente WhatsApp | gpt-5.4-mini | medium | Conversacional con contexto |
| Calificación de leads | gpt-5.4-mini | medium | Decisiones sobre múltiples variables |
| Cobranzas automáticas | gpt-5.4-mini | medium | Tono + negociación + reglas |
| Agendamiento con tools | gpt-5.4-mini | medium | Function calling + code interpreter |
| Orquestador multi-agente | gpt-5.4-mini | high | Routing con contexto |
| Resumen de tickets | gpt-5.4-mini | low | Batch, no conversacional |
| Análisis de documentos largos (>400K tokens) | gpt-5.4 | medium / high | Necesita 1M de contexto |
| Compliance / decisiones de alto riesgo | gpt-5.4 | xhigh | Máximo razonamiento disponible |
| Agentic workflow con 10+ tools | gpt-5.4 | high / xhigh | Tool search + razonamiento profundo |
Esta matriz no es teórica: replica la lógica con la que los templates del catálogo de AsisteClick están configurados hoy.
Cuándo escalar al flagship GPT-5.4
Mini es el nuevo default para el 80% de los casos. Flagship se justifica cuando una de estas condiciones se cumple:
- Contexto mayor a 400.000 tokens. Mini y nano cortan en 400K. Si tu agente debe analizar un expediente legal completo, un log de sesiones de un mes o una base de conocimiento sin chunking, el flagship con su contexto de 1.050.000 tokens es la única opción. Recuerda que pasando los 272K el input se duplica de precio.
-
Agentic workflow con más de 10 tools. El
tool_searchdel flagship está optimizado para reducir el costo de tokens cuando hay muchas herramientas disponibles simultáneamente. Un agente de soporte técnico que navega entre CRM, ticketing, KB, monitoreo y facturación se beneficia acá. - Computer use en entornos visuales complejos. Si el agente tiene que operar una interfaz gráfica desconocida (OSWorld-Verified 75% vs 72.1% de mini), la diferencia justifica el costo.
-
Razonamiento
xhigh. Solo el flagship soporta este nivel. Decisiones legales, auditoría financiera, revisión de código en producción: pagas más, pero el margen de error se reduce.
En el catálogo de AsisteClick ningún template hoy corre en flagship por defecto. Se reserva como opción manual para clientes del plan IA Plus con casos específicos de análisis documental o compliance.
Ruta de migración recomendada: empezar con mini, subir donde duela
Si estás arrancando un Agente de IA desde cero, el camino más eficiente es:
Paso 1 — Arranca con gpt-5.4-mini y reasoning_effort=medium. Es el 80/20 de la familia. Vas a cubrir casi todos los casos con calidad suficiente y costo controlado.
Paso 2 — Mide latencia y calidad por tipo de interacción. Separa las conversaciones por
intent y mide dos cosas: tiempo medio de respuesta y tasa de resolución sin escalamiento humano. Si la
latencia te duele en una categoría específica (ej: clasificación inicial), baja ese nodo a
nano con reasoning=low.
Paso 3 — Sube a flagship solo donde falles. Si un caso específico tiene baja tasa de
resolución autónoma a pesar de reasoning=high en mini, prueba el flagship con
xhigh. Pero mide: la diferencia suele ser de 2-4 puntos de accuracy a 3-4× el costo.
Paso 4 — Implementa prompt caching desde el día uno. Un system prompt cacheado te ahorra hasta 80% del costo de input. Si tu agente tiene un system prompt de 3.000 tokens y lo usas 10.000 veces al mes, son 30M de tokens que con cache pagas a $0.075/1M en vez de $0.75/1M.
Esta es la misma ruta que seguimos en AsisteClick cuando migramos un cliente de chatbots legacy a agentes de IA. Nunca arrancamos en flagship. Escalamos solo cuando hay evidencia de que mini no alcanza.
Si quieres profundizar en cómo diseñar los prompts que acompañan esta decisión, leé nuestra guía de prompt engineering para agentes de atención al cliente. Si estás comparando este enfoque con chatbots tradicionales, la discusión de fondo está en chatbot NLP vs GPT vs híbrido.
Implementación en AsisteClick
La plataforma de AsisteClick te da acceso al catálogo completo de templates sin que tengas que elegir el
modelo manualmente: cada plantilla viene preconfigurada con el modelo, reasoning_effort,
herramientas (web search, code interpreter, image generation) y variables recomendadas para su caso de
uso.
Si partes de cero, AsisteGPT te permite clonar un template del catálogo (cobranzas, ventas, soporte, agendamiento, traducción, orquestador) y ajustarlo a tu empresa en minutos. Si ya tienes un equipo humano operando canales, AsisteCopilot te suma los 9 copilots del catálogo (sugerencia de respuesta, traducción, resumen, desescalación) sin tocar el flujo del agente.
Los planes que incluyen la familia de agentes IA arrancan en IA Plus desde $260/mes (o $208/mes con facturación anual).
Preguntas frecuentes
¿GPT-5.4 mini es mejor que GPT-5 mini?
Sí, en todas las métricas publicadas. GPT-5.4 mini obtuvo 54.4% en SWE-Bench Pro contra 45.7% de GPT-5 mini, y corre más de 2× más rápido con el mismo pricing. OpenAI recomendó en el release llamarlo "el nuevo default" para aplicaciones de producción. La única razón para seguir en GPT-5 mini es que un agente en producción esté comportándose bien y no quieras alterar su tuning.
¿Cuál es la diferencia de latencia entre mini y nano?
OpenAI no publicó latencias exactas para la familia 5.4, pero el comportamiento observado es consistente
con la generación anterior: nano responde con tiempo a primer token (TTFT) cercano a 900ms y mini en el
rango de 1.2-1.8s con reasoning=medium. La diferencia es perceptible en chats en vivo donde
el usuario espera ver "escribiendo…" sin pausas largas.
¿Puedo usar GPT-5.4 nano para un chatbot de WhatsApp?
Puedes, pero no es la mejor elección salvo para tareas muy específicas como clasificación de intents o extracción de datos al inicio del flujo. Para la conversación completa conviene mini: nano rinde 33 puntos menos que mini en OSWorld-Verified (tareas agénticas) y tiende a fallar cuando debe razonar sobre contexto conversacional largo.
¿El contexto de 1 millón de tokens del flagship sirve en la práctica?
Sirve para casos puntuales: análisis de expedientes, procesamiento de logs completos, auditoría documental. Pero el precio se duplica después de los 272.000 tokens, así que no es una invitación a mandar prompts gigantes por defecto. La mayoría de los casos se resuelven mejor con chunking + retrieval (RAG) sobre mini que mandando todo el contexto crudo al flagship.
¿Cómo calculo el costo real de mi agente de IA?
Toma el volumen mensual de conversaciones, multiplica por el promedio de tokens por conversación
(típicamente 1.000-3.000 totales entre input y output) y aplica el pricing del modelo que piensas usar.
Súmale 10-30% de colchón por tokens de razonamiento invisibles (si usas reasoning_effort
medium o high). Si vas a cachear el system prompt, el input efectivo baja entre 60% y 80%.
¿Cuándo se actualiza el knowledge cutoff?
GPT-5.4 tiene cutoff al 31 de agosto de 2025. Si tu agente necesita información posterior (cambios regulatorios, productos nuevos, precios actualizados), tienes dos opciones: habilitar web search como tool (todos los modelos lo soportan) o conectar una base de conocimiento propia via RAG. El segundo es más barato, más rápido y más controlable.
¿Function calling funciona igual en las tres variantes?
Sí, las tres soportan function calling y structured outputs con la misma fidelidad. La diferencia
aparece cuando hay muchas tools simultáneamente: el flagship tiene tool_search que optimiza
la elección, mini tiene la mayoría de la optimización, y nano puede degradarse con más de 10 tools
disponibles.
Elegir el modelo correcto no es una decisión técnica aislada: define costo operativo, latencia percibida y techo de capacidades de tu producto. Con GPT-5.4, la respuesta por defecto ya no es "lo más barato que sirva" ni "el flagship por las dudas". Es mini con reasoning medium, escalando quirúrgicamente donde mides que falla.
Si quieres ver los 33 templates del catálogo corriendo en WhatsApp, webchat y demás canales, solicita una demo de AsisteGPT.