
Em 5 de março de 2026, a OpenAI lançou o GPT-5.4. Uma semana depois, publicou as variantes mini e nano. No catálogo de templates de Agentes de IA da AsisteClick, convivem hoje os três: cada um resolve um problema distinto, com perfis de custo e latência que diferem em uma ordem de magnitude.
Se você está construindo um Agente de IA sobre WhatsApp, um copilot para sua equipe de atendimento ou um subagente que resolve uma tarefa pontual, a escolha do modelo define 70% da economia do produto: custo por conversa, tempo de resposta percebido e taxa de resolução autônoma.
Este guia compara GPT-5.4 mini vs nano vs default com dados oficiais da OpenAI, benchmarks publicados e casos concretos do catálogo da AsisteClick. No final, você saberá exatamente qual modelo escolher para cada tipo de agente, quanto vai custar para você e quando convém escalar para o flagship.
A família GPT-5.4: o que mudou em relação ao GPT-5
O GPT-5.4 é a primeira família que a OpenAI lançou com computer-use nativo integrado no modelo base (não como tool externa), 1 milhão de tokens de contexto na versão flagship e um mecanismo de tool search que reduz o custo de tokens em tarefas com muitas ferramentas em até 47%.
Os três modelos compartilham:
- Knowledge cutoff: 31 de agosto de 2025.
-
Modalidades: entrada de texto e imagem, saída de texto. Áudio e vídeo não suportados (para áudio, você ainda precisa
gpt-4o-audioo Whisper). - Capacidades da API: function calling, structured outputs, streaming, parallel tool use.
- Tool use: web search, file search, code interpreter, image generation, skills, MCP.
O que muda entre eles é poder de raciocínio, tamanho do contexto, custo por token e latência. E essa diferença é a que te obriga a pensar como arquiteto antes de disparar um prompt.
Especificações oficiais: as 3 variantes em uma tabela
Dados extraídos da documentação oficial da OpenAI em 19 de abril de 2026.
| Especificação | gpt-5.4 | gpt-5.4-mini | gpt-5.4-nano |
|---|---|---|---|
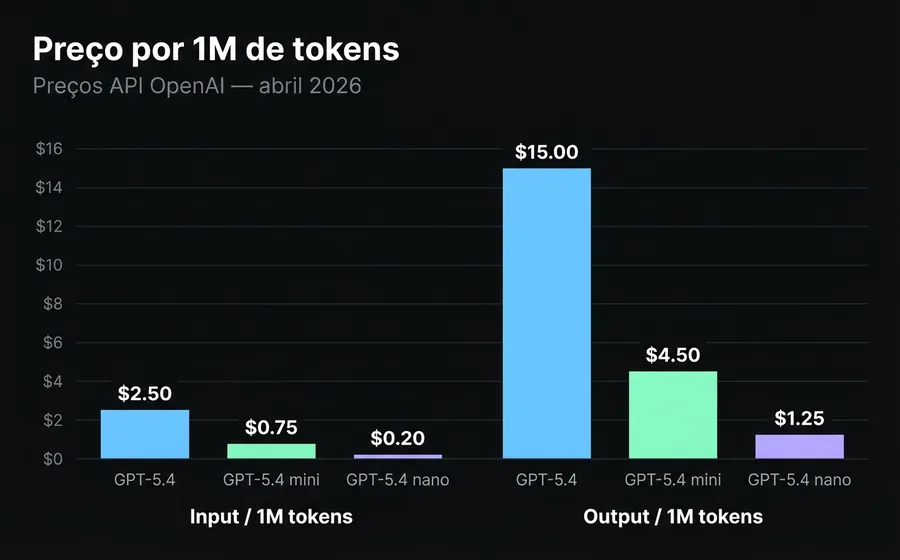
| Input / 1M tokens | $2.50 | $0.75 | $0.20 |
| Output / 1M tokens | $15.00 | $4.50 | $1.25 |
| Cached input / 1M tokens | $0.25 | $0.075 | $0.02 |
| Context window | 1.050.000 | 400.000 | 400.000 |
| Max output tokens | 128.000 | 128.000 | 128.000 |
| Function calling | Sim | Sim | Sim |
| Structured outputs | Sim | Sim | Sim |
| Computer use nativo | Sim | Sim | Não |
| Tool search (otimização) | Sim | Sim | Não |
| Modalidades de entrada | Texto + imagem | Texto + imagem | Texto + imagem |
| Reasoning effort | none / low / medium / high / xhigh | low / medium / high | low / medium / high |
Dois detalhes que costumam ser ignorados:
O preço dobra após 272.000 tokens de prompt no flagship. Se você carregar um documento longo ou um histórico extenso, o input passa de $2.50 para $5.00 por milhão de tokens. Isso faz com que o "1M de contexto" do flagship seja mais um teto arquitetônico do que um convite para enviar prompts gigantes.
O cached input é a maior alavanca econômica. No mini, um token cacheado custa $0.075/1M contra $0.75/1M do input normal. Se seu agente tem um system prompt longo que é reutilizado em cada conversa (o que é típico), cacheá-lo reduz o custo efetivo entre 60% e 80%.
O parâmetro que ninguém explica: reasoning_effort
GPT-5.4 introduziu um parâmetro que redefine como você paga por inteligência: reasoning_effort. Controla o quanto o modelo "pensa" antes de responder. Os valores são none, low, medium, high e xhigh (apenas o flagship suporta xhigh).
Cada nível consome tokens de raciocínio invisíveis que você paga como output, mas que não aparecem na resposta final. Ou seja: com high, o modelo pode gastar 2.000-5.000 tokens internos antes de escrever a primeira palavra visível.
Heurística prática:
-
noneolow: respostas conversacionais, FAQ, saudações, classificação simples. O modelo responde quase instantaneamente. -
medium: o default razoável. Atendimento ao cliente, qualificação de leads, triage. Há um passo de análise, mas ele se mantém responsive. -
high: tarefas com múltiplos passos ou ambiguidade. Orquestração de subagentes, diagnóstico técnico, negociação. -
xhigh: reservado para agentic workflows longos onde um erro custa mais que cinco segundos de latência. Compliance, decisões financeiras, código crítico.
No catálogo da AsisteClick, o orquestrador multi-agente usa gpt-5.4-mini com
reasoning_effort=high porque deve decidir a qual subagente delegar. Um resumidor de conversas usa low porque a tarefa é mecânica.
Benchmarks oficiais: onde cada variante performa
OpenAI publicou resultados verificados nos benchmarks padrão da indústria no momento do release.
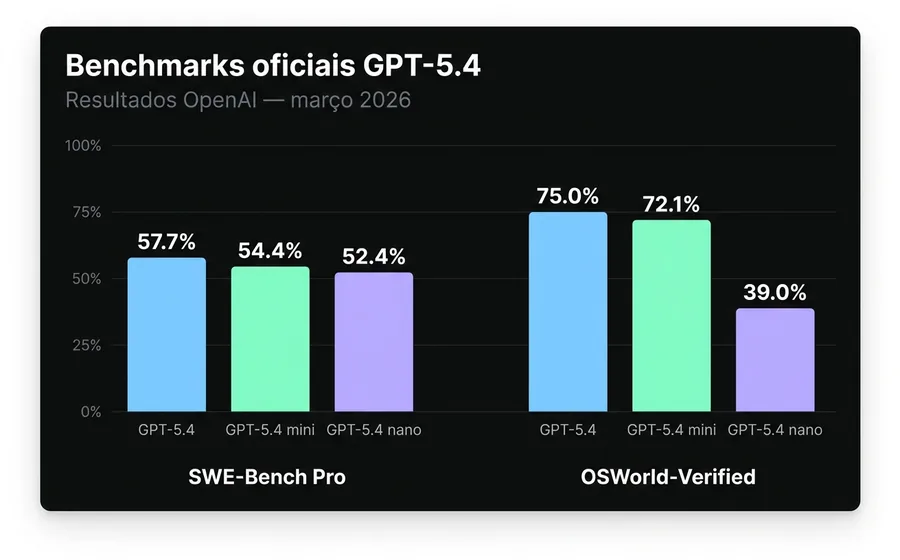
SWE-Bench Pro (tarefas de engenharia de software reais):
- gpt-5.4: 57.7%
- gpt-5.4-mini: 54.4%
- gpt-5.4-nano: 52.4%
- gpt-5-mini (legacy): 45.7%
OSWorld-Verified (navegação de ambientes de desktop, proxy de "computer use"):
- gpt-5.4: 75.0% (supera o desempenho humano médio, 72.4%)
- gpt-5.4-mini: 72.1%
- gpt-5.4-nano: 39.0%
A leitura importante não é "quem ganha", mas onde cada modelo se diferencia. Entre flagship e mini há 3.3 pontos em coding e 2.9 em computer use. Entre mini e nano há apenas 2 pontos em coding, mas 33 pontos em computer use. Nano não é projetado para tarefas agênticas complexas: é um classificador e extrator de alto volume que casualmente entende linguagem natural.
Se seu agente precisa lidar com GUIs ou executar passos multi-tool com estado, mini é o seu piso. Nano nunca vai fechar essa lacuna, mesmo que você aumente reasoning_effort.
Preço real: quanto custa operar cada modelo
O pricing por milhão de tokens parece barato até que você o multiplique por volume. Vamos fazer a conta com um caso concreto: um Agente de IA no WhatsApp que processa 10.000 conversas por mês, onde cada conversa tem em média 6 turnos e 200 tokens por turno (metade input, metade output).
Isso resulta em 6 milhões de tokens input + 6 milhões output mensais.
Custo mensal estimado sem cache:
- gpt-5.4: $15 (input) + $90 (output) = $105/mês
- gpt-5.4-mini: $4.50 + $27 = $31.50/mês
- gpt-5.4-nano: $1.20 + $7.50 = $8.70/mês
Com cached input (system prompt reutilizado, assumindo 80% cache hit):
- gpt-5.4-mini: $0.90 + $27 = $27.90/mês
- gpt-5.4-nano: $0.24 + $7.50 = $7.74/mês
Para um operador com 100.000 conversas/mês, a diferença entre mini e flagship é $1.000 por mês. Para 1.000.000 de conversas, $10.000 por mês. A decisão do modelo é literalmente uma decisão de margem operacional.
Como resolvemos na AsisteClick: os 3 tipos de agente e seu modelo
Dentro do catálogo ativo da AsisteClick há 33 templates de Agentes de IA e copilots, classificados em três categorias. O modelo atribuído a cada template não é arbitrário: responde à relação entre complexidade da tarefa, latência tolerável e custo por interação.
Hoje o catálogo está em migração gradual para a família 5.4. Os templates novos já começam em gpt-5.4-mini o gpt-5.4-nano. Os legacy (criados antes de março de 2026) ainda rodam sobre gpt-5-mini e são atualizados à medida que são revisados individualmente, porque mudar o modelo pode alterar o comportamento do agente em produção.
Agentes IA autônomos (ai-agent) — 18 templates
São agentes que conversam diretamente com o cliente final no WhatsApp, webchat, Instagram ou outros canais. Respondem a consultas, qualificam leads, agendam compromissos, gerenciam pedidos ou cobranças.
Modelo recomendado: gpt-5.4-mini com reasoning_effort=medium.
Por quê: a conversa com um humano no WhatsApp tolera 1-3 segundos de latência no máximo antes que pareça "lento". Mini com medium cai dentro desse intervalo e mantém qualidade de raciocínio suficiente para 95% das interações. O flagship se justifica apenas quando o agente deve realizar agentic workflows (chamar 5+ tools em sequência, raciocinar sobre documentos longos).
Exemplos do catálogo:
-
Cobranças IA (
ai-collections):gpt-5.4-mini, medium. Decide o tom, fecha planos de pagamento, encaminha casos complexos. Em detalhe, o template está alinhado com o que discutimos em chatbot de cobranças WhatsApp para fintech e se conecta com integrações como Loan Collection. -
Vendas IA (
ai-sales):gpt-5.4-mini, medium. Qualifica leads e agenda demos. Padrão explicado em qualificar leads WhatsApp com chatbot IA. -
Orquestrador Multiagente (
ai-orchestrator):gpt-5.4-mini, high. É a única exceção onde sobe reasoning porque deve escolher entre subagentes. -
Agendador com Calendários API (
ai-asiste-booking):gpt-5.4-mini, medium, com code interpreter habilitado. É o único template que usa code porque precisa calcular disponibilidade contra timezones e regras de calendário. Detalhamo-lo na landing de agendamento de horários.
Copilots (assistentes internos para agentes humanos) — 9 templates
Esses modelos não falam com o cliente. Assistem o agente humano: sugerem respostas, traduzem mensagens, resumem conversas, detectam oportunidades de venda, desescalam situações tensas. O detalhe completo do padrão está em copilots de agentes IA: respostas em tempo real.
Modelo recomendado por padrão: gpt-5.4-mini com
reasoning_effort=low o medium conforme a tarefa.
A exceção interessante: o copilot de tradução em tempo real
(copilot-translator) é o único template do catálogo que usa . A tradução conversacional é determinística, não requer raciocínio em cadeia e o agente humano está esperando o texto para enviá-lo. Nano responde com metade da latência de mini e a um quinto do custo. Um copilot que é acionado 200 vezes por hora de atendimento tem que ser barato ou nada o justifica.
gpt-5.4-nanoOutros copilots do catálogo: email, resumo, KB, resposta sugerida, teste, desescalada, oportunidade de venda, notas internas.
Subagents (tools especializadas) — 6 templates
São agentes que não conversam: executam uma ação pontual invocada por outro agente. Consultam faturamento, integram com Zapier ou n8n, processam um checkout de MercadoPago, consultam o clima.
Son agentes que no conversan: ejecutan una acción puntual invocada por otro agente. Consultan facturación, integran con Zapier o n8n, procesan un checkout de MercadoPago, consultan el clima.
Modelo recomendado: gpt-5.4-mini com reasoning_effort=low. Output breve, tarefa determinística, é invocado muitas vezes por sessão.
O subagent-weather é o único com image generation habilitado (para retornar o prognóstico como imagem composta), detalhe que mostra como cada template é configurado cirurgicamente de acordo com qual tool precisa.
Matriz de decisão: qual modelo para qual caso
Se você está construindo um Agente de IA do zero e não sabe por onde começar, esta tabela resolve 90% dos casos.
| Caso de uso | Modelo | Reasoning | Por quê |
|---|---|---|---|
| Classificação de intents | gpt-5.4-nano | low | Tarefa determinística, alto volume |
| Extração de dados estruturados | gpt-5.4-nano | low | Output schema fixo, structured outputs |
| Tradução em tempo real | gpt-5.4-nano | low | Latência crítica, sem raciocínio |
| Atendimento ao cliente WhatsApp | gpt-5.4-mini | medium | Conversacional com contexto |
| Qualificação de leads | gpt-5.4-mini | medium | Decisões sobre múltiplas variáveis |
| Cobranças automáticas | gpt-5.4-mini | medium | Tom + negociação + regras |
| Agendamento com tools | gpt-5.4-mini | medium | Function calling + code interpreter |
| Orquestrador multiagente | gpt-5.4-mini | high | Routing com contexto |
| Resumo de tickets | gpt-5.4-mini | low | Batch, não conversacional |
| Análise de documentos longos (>400K tokens) | gpt-5.4 | medium / high | Requer 1M de contexto |
| Compliance / decisões de alto risco | gpt-5.4 | xhigh | Máximo raciocínio disponível |
| Agentic workflow com 10+ tools | gpt-5.4 | high / xhigh | Tool search + raciocínio profundo |
Esta matriz não é teórica: replica a lógica com a qual os templates do catálogo do AsisteClick estão configurados hoje.
Quando escalar para o flagship GPT-5.4
Mini é o novo default para 80% dos casos. Flagship se justifica quando uma destas condições é atendida:
- Contexto maior que 400.000 tokens. Mini e nano cortam em 400K. Se seu agente deve analisar um processo legal completo, um log de sessões de um mês ou uma base de conhecimento sem chunking, o flagship com seu contexto de 1.050.000 tokens é a única opção. Lembre-se que, passando os 272K, o input duplica de preço.
-
Agentic workflow com mais de 10 tools. O
tool_searchdo flagship é otimizado para reduzir o custo de tokens quando há muitas ferramentas disponíveis simultaneamente. Um agente de suporte técnico que navega entre CRM, ticketing, KB, monitoramento e faturamento se beneficia aqui. - Computer use em ambientes visuais complexos. Se o agente tem que operar uma interface gráfica desconhecida (OSWorld-Verified 75% vs 72.1% de mini), a diferença justifica o custo.
-
Raciocínio
xhigh. Apenas o flagship suporta este nível. Decisões legais, auditoria financeira, revisão de código em produção: você paga mais, mas a margem de erro é reduzida.
No catálogo da AsisteClick nenhum template hoje roda em flagship por padrão. É reservado como opção manual para clientes do plano IA Plus com casos específicos de análise documental ou compliance.
Rota de migração recomendada: começar com mini, escalar onde doer
Se você está começando um Agente de IA do zero, o caminho mais eficiente é:
Passo 1 — Comece com gpt-5.4-mini y reasoning_effort=medium. É o 80/20 da família. Você vai cobrir quase todos os casos com qualidade suficiente e custo controlado.
Passo 2 — Meça latência e qualidade por tipo de interação. Separe as conversas por intent e meça duas coisas: tempo médio de resposta e taxa de resolução sem escalonamento humano. Se a latência te incomoda em uma categoria específica (ex: classificação inicial), baixe esse nó para
nano com reasoning=low.
Passo 3 — Escale para flagship apenas onde falhar. Se um caso específico tem baixa taxa de resolução autônoma apesar de reasoning=high em mini, experimente o flagship com
xhigh. Mas meça: a diferença geralmente é de 2-4 pontos de accuracy a 3-4× o custo.
Passo 4 — Implemente prompt caching desde o dia um. Um system prompt cacheado te economiza até 80% do custo de input. Se seu agente tem um system prompt de 3.000 tokens e o usa 10.000 vezes ao mês, são 30M de tokens que, com cache, você paga a $0.075/1M em vez de $0.75/1M.
Esta é a mesma rota que seguimos na AsisteClick quando migramos um cliente de chatbots legacy para agentes de IA. Nunca começamos em flagship. Escalamos apenas quando há evidência de que mini não é suficiente.
Se você quiser aprofundar em como projetar os prompts que acompanham esta decisão, leia nosso guia de prompt engineering para agentes de atendimento ao cliente. Se você está comparando esta abordagem com chatbots tradicionais, a discussão de fundo está em chatbot NLP vs GPT vs híbrido.
Implementação no AsisteClick
A plataforma do AsisteClick te dá acesso ao catálogo completo de templates sem que você precise escolher o modelo manualmente: cada template vem pré-configurado com o modelo, reasoning_effort, ferramentas (web search, code interpreter, image generation) e variáveis recomendadas para o seu caso de uso.
Se você parte do zero, AsisteGPT ele permite clonar um template do catálogo (cobranças, vendas, suporte, agendamento, tradução, orquestrador) e ajustá-lo à sua empresa em minutos. Se você já tem uma equipe humana operando canais, AsisteCopilot ele adiciona os 9 copilots do catálogo (sugestão de resposta, tradução, resumo, desescalada) sem alterar o fluxo do agente.
Os planos que incluem a família de agentes IA começam em IA Plus a partir de $260/mês (ou $208/mês com faturamento anual).
Perguntas frequentes
GPT-5.4 mini é melhor que GPT-5 mini?
Sim, em todas as métricas publicadas. GPT-5.4 mini obteve 54.4% no SWE-Bench Pro contra 45.7% do GPT-5 mini, e executa mais de 2× mais rápido com o mesmo pricing. A OpenAI recomendou no release chamá-lo de "o novo default" para aplicações de produção. A única razão para continuar no GPT-5 mini é que um agente em produção esteja se comportando bem e você não queira alterar seu tuning.
Qual é a diferença de latência entre mini e nano?
A OpenAI não publicou latências exatas para a família 5.4, mas o comportamento observado é consistente com a geração anterior: nano responde com tempo para o primeiro token (TTFT) próximo a 900ms e mini na faixa de 1.2-1.8s com reasoning=medium. A diferença é perceptível em chats ao vivo onde o usuário espera ver "digitando…" sem pausas longas.
Posso usar GPT-5.4 nano para um chatbot de WhatsApp?
Pode, mas não é a melhor escolha, exceto para tarefas muito específicas como classificação de intents ou extração de dados no início do fluxo. Para a conversa completa, convém o mini: nano rende 33 pontos menos que mini no OSWorld-Verified (tarefas agênticas) e tende a falhar quando precisa raciocinar sobre contexto conversacional longo.
O contexto de 1 milhão de tokens do flagship serve na prática?
Serve para casos pontuais: análise de expedientes, processamento de logs completos, auditoria documental. Mas o preço dobra depois dos 272.000 tokens, então não é um convite para enviar prompts gigantes por padrão. A maioria dos casos é resolvida melhor com chunking + retrieval (RAG) sobre mini do que enviando todo o contexto bruto ao flagship.
Como calculo o custo real do meu agente de IA?
Pegue o volume mensal de conversas, multiplique pela média de tokens por conversa (tipicamente 1.000-3.000 totais entre input e output) e aplique o pricing do modelo que você pretende usar. reasoning_effort
Some 10-30% de margem para tokens de raciocínio invisíveis (se você usa medium ou high). Se você for cachear o system prompt, o input efetivo cai entre 60% e 80%.
Quando o knowledge cutoff é atualizado?
GPT-5.4 tem cutoff em 31 de agosto de 2025. Se o seu agente precisa de informações posteriores (mudanças regulatórias, produtos novos, preços atualizados), você tem duas opções: habilitar web search como tool (todos os modelos o suportam) ou conectar uma base de conhecimento própria via RAG. O segundo é mais barato, mais rápido e mais controlável.
Function calling funciona igual nas três variantes?
Sim, as três suportam function calling e structured outputs com a mesma fidelidade. A diferença aparece quando há muitas tools simultaneamente: o flagship tem tool_search que otimiza a escolha, mini tem a maioria da otimização, e nano pode se degradar com mais de 10 tools disponíveis.
Escolher o modelo correto não é uma decisão técnica isolada: define custo operacional, latência percebida e teto de capacidades do seu produto. Com GPT-5.4, a resposta padrão não é mais "o mais barato que sirva" nem "o flagship por via das dúvidas". É mini com reasoning medium, escalando cirurgicamente onde você mede que falha.
Se você quiser ver os 33 templates do catálogo rodando no WhatsApp, webchat e demais canais, solicite uma demo do AsisteGPT.