
Os 30% dos tickets de suporte em SaaS são repetitivos: a mesma pergunta de onboarding, o mesmo "não recebo o e-mail de reset", o mesmo "como troco de plano" cem vezes por semana. É o que diz o Zendesk CX Trends Report 2024, e qualquer pessoa que tenha operado uma equipe de suporte por mais de seis meses confirma isso sem precisar de um benchmark. Se a sua equipe de Customer Success gasta mais de quatro horas por dia respondendo a mesma coisa, este post é para você.
Mas a pergunta importante não é quantos tickets reduzir. É quais, como, e sem derrubar o CSAT no processo. A Klarna automatizou o trabalho de 700 agentes em fevereiro de 2024, anunciou como triunfo e, um ano depois, estava contratando humanos de novo. Automação malfeita é pior do que sobrecarga: corrói a confiança do cliente e desmoraliza a equipe que sobra.
Este guia propõe uma resposta diferente: uma arquitetura de 3 camadas (self-service estruturado, bot conversacional e Agente de IA generativo com copilot humano) que, bem implementada, reduz o volume de tickets entre 40% e 60% em seis meses sem sacrificar a satisfação. Você vai encontrar o framework completo, os benchmarks da indústria, os KPIs que importam, as quatro fases de implementação e a lista de erros que quase todas as empresas SaaS cometem no caminho.
Por que o volume de tickets escala com o SaaS (e por que isso é um problema)
O suporte em um SaaS B2B tem um problema estrutural: escala linearmente com a base de clientes, mas a receita nem sempre acompanha. Cada cliente novo gera entre 0,5 e 3 tickets por mês em média, segundo o Intercom Customer Service Trends 2024, dependendo da complexidade do produto e da maturidade do onboarding. Se você passa de 200 para 1.000 clientes, não precisa multiplicar sua equipe de suporte por cinco, mas precisa multiplicar por algo. E esse "algo" é o que define se o negócio escala ou se afoga.
O outro problema é a composição do volume. A regra 80/20 se aplica com violência no suporte SaaS: 20% das consultas explicam entre 70% e 80% do volume total. Essas consultas não são as complexas, são as repetitivas. E são as que a equipe humana resolve pior quando chega o cansaço de sexta-feira à tarde.
As categorias típicas em SaaS B2B se distribuem assim:
| Categoria | % do volume típico | Tipo de resolução |
|---|---|---|
| Account & access (login, password reset, MFA, convites a usuários) | 18-25% | Quase 100% automatizável |
| Billing & subscriptions (faturas, mudanças de plano, métodos de pagamento) | 15-22% | 70-90% automatizável |
| Onboarding & setup (primeiros passos, configuração inicial, integrações) | 12-18% | 40-60% automatizável |
| How-to & features (como fazer X, onde está Y) | 20-30% | 60-80% automatizável |
| Technical issues & bugs (erros reais, comportamento inesperado) | 15-25% | 10-30% automatizável, o resto precisa de humano |
| Strategic & advisory (consultas de uso avançado, integrações custom) | 5-10% | Não automatizável, NÃO se deve automatizar |
Fonte: composição típica observada em clientes SaaS B2B da AsisteClick, consistente com HubSpot Service Hub benchmarks 2024.
A conclusão operacional é clara: há um 50-65% do volume que é razoavelmente automatizável sem sacrificar qualidade, desde que você diferencie bem as categorias. O erro mais comum é tentar automatizar tudo, incluindo os 5-10% estratégicos, ou não automatizar nada por medo de perder qualidade. Nenhum dos dois extremos funciona.

Antes de seguir, um esclarecimento de vocabulário. No restante do post você vai ler dois termos que costumam ser confundidos: chatbot (de regras, NLP, intents predefinidos) e Agente de IA (modelo generativo tipo GPT-5.4 com acesso à sua base de conhecimento via RAG). Não são sinônimos, e a diferença importa para a taxa de deflexão. Se você quiser aprofundar em como decidir entre um e outro, temos um post dedicado em chatbot NLP vs GPT vs híbrido.
Deflection rate: a métrica que de fato importa
Se o seu relatório mensal de suporte tem "% de tickets fechados", "tickets recebidos" e "tempo de resposta médio", você está medindo a sintomatologia, não a saúde do sistema. A métrica que conecta automação, equipe humana e experiência do cliente em um único número é o deflection rate.
O que é e como se calcula
O deflection rate é o percentual de consultas que se resolvem sem escalar para um humano. A fórmula básica é:
Deflection Rate = (Tickets resueltos por self-service o IA / Tickets totales recibidos) × 100
Mas a definição operacional tem nuances que mudam tudo. "Resolvido" não quer dizer "o bot disse algo". Quer dizer o cliente obteve a informação que precisava e não voltou a abrir um ticket pelo mesmo tema nas 24-48 horas seguintes. Essa é a diferença entre deflection rate honesto e deflection rate vanity.
Há duas formas de medir, e vale a pena ter as duas no dashboard:
- Deflection rate por sessão: % de conversas com o bot/IA que terminam sem "falar com humano" nem reabrir ticket em 48h.
- Deflection rate por ticket: % de tickets que o sistema fecha automaticamente e o cliente não reabre.
O número honesto costuma ficar entre 30% e 60% em SaaS maduros. Os relatórios que mostram 85% geralmente contam "o bot respondeu" como deflection, o que é trapaça.
Benchmarks por indústria
Os dados do Intercom Customer Service Trends 2024 e Zendesk CX Trends 2024 dão a seguinte foto para SaaS B2B:
| Etapa de maturidade | Deflection rate típico | Tecnologia associada |
|---|---|---|
| Apenas FAQ estática + base de conhecimento | 8-15% | Help Center indexável |
| Bot NLP treinado (top 20 intents) | 25-35% | Chatbot de regras ou NLP |
| Bot NLP + handoff inteligente | 35-45% | Chatbot + fila priorizada |
| Agente de IA generativo com RAG | 45-60% | LLM + base de conhecimento conectada |
| Agente de IA + copilot para o humano | 55-70% | LLM + assistente ao agente |
Fonte: composição agregada de Intercom Customer Service Trends 2024, Zendesk CX Trends 2024 e HubSpot Service Hub benchmarks.
Quando alguém te diz "atingimos 80% de deflection com IA", peça a metodologia antes de acreditar. O número realista de empresas SaaS bem implementadas, medindo honestamente, fica entre 45% e 60% após um ano de implementação.
Por que deflection ≠ "taxa de resposta automática"
Aqui está o erro mais visto. Uma empresa instala um bot, mede quantas conversas passaram pelo bot e reporta isso como "80% de automação". Mas se o bot diz "não entendi, escreva de novo" e o cliente abandona ou escala manualmente, isso não é deflection. É frustração automatizada.
A diferença operacional: deflection se mede em resolução, não em resposta. O cliente resolveu seu problema ou não. Se não, contou como ticket mesmo que não tenha escalado formalmente.
Por isso sempre deve ser observado junto ao CSAT post-deflection (satisfação do cliente depois da interação com o bot/IA, sem escalonamento). Se o deflection sobe mas o CSAT post-deflection cai, você não está melhorando, está escondendo o problema. Voltaremos a esse ponto na seção de KPIs.
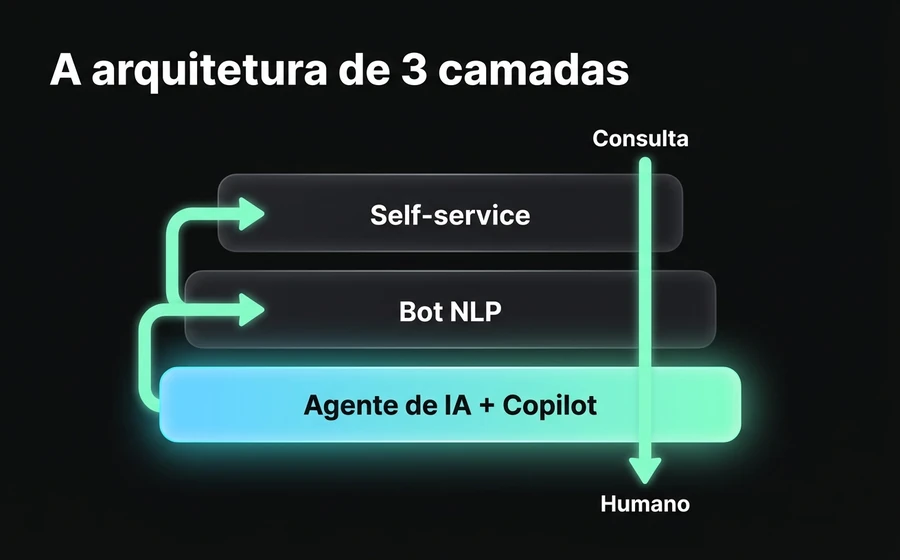
A arquitetura de 3 camadas para reduzir tickets
Aqui vem o core do post. A pergunta operacional não é "coloco um bot?", é "o que coloco em cada camada para que o volume caia sem que o cliente se frustre?". A arquitetura que recomendamos — e que aplicamos em clientes SaaS da AsisteClick — tem três camadas que trabalham em ordem ascendente de complexidade.
A ideia-chave é que cada camada absorve o que a anterior não conseguiu resolver, sem que o cliente sinta o handoff. Se o self-service estruturado resolve, ótimo. Se não, o bot conversacional assume o controle. Se o bot não consegue, o Agente de IA generativo entra em jogo. E se tudo isso falha, o humano recebe o ticket com todo o contexto prévio, não do zero.
Camada 1: Self-service estruturado
Esta é a camada mais subestimada e a que mais absorve volume quando bem feita. O cliente não quer conversar com ninguém, quer encontrar a resposta rápido. O self-service estruturado tem três componentes:
- Help Center com busca funcional: uma base de conhecimento pública, indexável pelo Google, com um buscador que entende sinônimos. A métrica de sucesso aqui é "% de visitas ao Help Center que NÃO terminam em um ticket aberto nas 24h seguintes". Se o seu Help Center existe mas o deflection a partir dele é baixo, não é um problema de conteúdo, é de findability.
- FAQ contextual dentro do produto: links diretos para artigos relevantes no momento exato em que o usuário trava. Se o usuário está na tela de configuração de webhooks, o botão de ajuda deve levá-lo ao artigo de webhooks, não ao Help Center genérico.
- Status do sistema e changelog: uma página pública de status (uptime, incidentes ativos) e um changelog visível. Isso absorve os 5-10% de tickets que são "está fora do ar?" ou "quando vão lançar a feature X?".
Deflection esperado desta camada: 10-18% segundo Intercom e benchmarks próprios. É a camada mais barata de implementar e a que mais é negligenciada.
Esta camada funciona porque o cliente prefere resolver sozinho. 67% dos consumidores preferem self-service antes de falar com um representante (HubSpot Service Hub data 2024). A camada 1 não é um "fallback", é a primeira opção para o cliente moderno.
Camada 2: Bot conversacional NLP
Quando o self-service não é suficiente — porque o usuário não encontra o artigo, ou porque a consulta requer parâmetros (um nome, um ID, uma data) — entra o bot conversacional. Aqui falamos de um bot do tipo NLP: treinado sobre intents (intenções do usuário) que cobrem o top 20-30 de consultas frequentes.
Um bot NLP bem treinado em SaaS tipicamente cobre:
- Reset de password e convites a usuários.
- Status de faturamento e download de faturas.
- Mudança de plano ou método de pagamento (com escalonamento para humano no fechamento).
- Consultas de status da conta (uso, limites, data de renovação).
- Perguntas frequentes com resposta fechada ("vocês integram com Salesforce?").
- Triagem inicial: capturar o problema e roteá-lo ao departamento correto.
A chave do bot NLP é que ele é determinístico: dado um intent reconhecido, a resposta é sempre a mesma. Isso o torna previsível, auditável e barato de operar, mas o limita: se o cliente pergunta algo que não está nos intents treinados, o bot tem que dizer "não entendi" ou derivar para humano. Não improvisa.
Deflection esperado desta camada: 15-25% sobre o volume que chegou até aqui. Somado à Camada 1, você vai estar em 25-40% de deflection total.
O bot NLP se treina sobre dados reais. A armadilha comum é treiná-lo com intents teóricos ("usuários podem perguntar X, Y, Z") em vez do histórico real de tickets. Se você for treinar um, exporte os últimos 6 meses de tickets, clusterize-os e construa os intents a partir dos dados. Temos um post completo sobre isso em prompt engineering para chatbots de atendimento.
Camada 3: Agente de IA generativo + Copilot para o humano
Aqui é onde a matemática do deflection rate muda de escala. Um Agente de IA generativo (baseado em um LLM como o GPT-5.4, conectado via RAG à sua base de conhecimento, documentação de produto e, opcionalmente, dados da conta do cliente) não precisa de intents predefinidos. Raciocina sobre a consulta, busca contexto e responde em linguagem natural.
O que um Agente de IA faz bem e um bot NLP não:
- Consultas longas e ambíguas: "Olá, tenho um problema com a integração do HubSpot, os contatos novos não estão entrando desde ontem, já verifiquei a API key, o que faço". Um bot NLP se perde. Um Agente de IA identifica os passos de diagnóstico, pergunta um a um e resolve ou escala com contexto completo.
- Combinação de vários intents em uma única consulta: "Quero mudar meu plano e também preciso adicionar três usuários novos, como faço?". O Agente de IA divide a consulta e resolve por partes.
- Personalização com dados da conta: se o Agente de IA tem acesso (via API) ao status real da conta do usuário, pode responder "seu plano atual é Pro até 15 de junho, você pode trocá-lo em Settings > Billing, segue o link direto" em vez da resposta genérica.
Mas há algo ainda mais importante, que define a diferença entre uma empresa SaaS que reduz tickets e uma que reduz tickets sem destruir o CSAT: o Copilot para o humano.
Quando uma consulta escala para a equipe humana (porque a IA decidiu escalar, ou porque o cliente pediu explicitamente), o agente humano não recebe o ticket do zero. Recebe:
- O histórico completo da conversa com a IA.
- Um resumo do problema gerado pelo Agente de IA.
- Sugestões de resposta baseadas na base de conhecimento.
- Dados da conta do cliente já carregados (plano, data de cadastro, uso, tickets anteriores).
Isso se chama Copilot e reduz o AHT (Average Handle Time) do agente humano entre 25% e 40% segundo o McKinsey State of AI 2024. Se você quiser aprofundar nisso, veja Copilot: agentes de IA com respostas em tempo real.
Deflection esperado desta camada: 20-30% adicional. Somado às anteriores, uma empresa SaaS bem implementada chega a 50-65% de deflection total.
Se você se interessa pelo detalhe técnico de como se monta a base de conhecimento para que a Camada 3 funcione bem (chunking, embeddings, RAG, refresh frequency), temos um post completo em as 3 camadas de conhecimento de um Agente de IA.
Comparativo das 3 camadas
| Camada | Tecnologia | Quando se aplica | Deflection típico | Complexidade de implementação | Custo operacional |
|---|---|---|---|---|---|
| 1. Self-service | Help Center + FAQ + status page | Consultas com resposta fixa, públicas | 10-18% | Baixa (1-2 semanas) | Baixo (manutenção de docs) |
| 2. Bot NLP | Intents treinados + fluxos | Top 20-30 consultas, requer parâmetros | 15-25% | Média (4-6 semanas) | Médio (retreinamento mensal) |
| 3. Agente de IA + Copilot | LLM + RAG + handoff com contexto | Consultas longas, ambíguas, personalizadas | 20-30% | Alta (8-12 semanas) | Médio-Alto (tokens + curadoria) |
As três camadas juntas, operando em ordem, levam a um deflection acumulado realista de 45-65% em seis meses. Acima disso, os retornos diminuem rapidamente e você entra na zona de risco Klarna: querer automatizar o que não se deve automatizar.
Como NÃO fazer: o caso Klarna e outros erros comuns
Em fevereiro de 2024, a Klarna anunciou que seu Agente de IA estava fazendo o trabalho equivalente a 700 agentes humanos full-time, com CSAT igual ao humano e resolução 25% mais rápida. A ação reagiu, a imprensa tech comemorou e todas as empresas SaaS perguntaram "como conseguiram?".
Um ano depois, em maio de 2025, a Klarna estava contratando humanos de novo. O CEO Sebastian Siemiatkowski admitiu em entrevistas que a qualidade havia caído, que os clientes queriam falar com humanos e que a cobertura de IA havia sido mais uma declaração de intenções do que uma realidade operacional. A lição não é "a IA não funciona". A lição é que automatizar o trabalho de 700 pessoas em poucos meses, sem ter a arquitetura de fallback nem os KPIs de qualidade bem medidos, termina mal.
Se você se interessa pela análise detalhada, escrevemos um post completo sobre o que se pode aprender com o caso em Klarna e o erro de IA em customer service. Aqui resumimos os anti-patterns mais comuns que esse caso exemplifica e que vemos repetidos em clientes novos:
Substituir humanos de um dia para o outro
O erro da Klarna não foi usar IA, foi eliminar a capacidade humana antes de validar a cobertura da IA em produção real. O correto é o contrário: a IA escala primeiro, a equipe humana é redimensionada depois, com base em dados de seis meses no mínimo. A automação não se mede em "quantos humanos tirei", se mede em "que porcentagem do volume resolvi bem sem escalar". O segundo te dá espaço para decidir o primeiro com dados. O primeiro feito sem o segundo é uma bomba-relógio.
Automatizar onboarding complexo
Os clientes novos têm uma necessidade psicológica de falar com um humano nas duas primeiras semanas. Não porque a IA não saiba responder, mas porque estão avaliando se a empresa "está lá" para eles. Automatizar o onboarding antes dos 14-30 dias é um dos preditores mais fortes de churn precoce. A regra operacional: o onboarding é a última coisa que se automatiza, não a primeira. E quando se automatiza, sempre com escalonamento fácil ao humano.
Eliminar o botão "falar com humano"
Algumas equipes escondem o botão de escalonamento para forçar deflection. É um anti-pattern. O cliente que quer falar com humano e não consegue, abandona ou reescala por outro canal (Twitter, e-mail para um executivo, review pública). A visibilidade do escalonamento humano deve ser sempre alta. Se a taxa de deflexão cai porque o botão está visível, não esconda o botão: melhore a IA.
Medir só deflection, ignorar CSAT post-deflection
Como dissemos antes: deflection sem CSAT post-deflection é vanity. A métrica única que importa é a dupla deflection + CSAT post-deflection. Se o deflection sobe 10 pontos e o CSAT cai 15 pontos, você perdeu. Vamos ver isso em detalhe na seção de KPIs.
Achar que a IA "já está treinada"
Nenhum Agente de IA em produção está pronto. A revisão semanal de consultas não resolvidas, a melhoria de prompts, o refresh da base de conhecimento são trabalho permanente. As empresas que tratam o setup como "projeto" (com início e fim) em vez de "operação" (contínua) são as que veem a taxa de deflexão degradar depois de 6 meses.
Implementação prática: 4 fases
Uma pergunta razoável depois de ler tudo isso é: "OK, por onde começo?". A resposta curta: meça antes de automatizar. A resposta longa é este roadmap de quatro fases que aplicamos em implementações SaaS com AsisteClick.
Fase 1: Medir baseline (semana 1-2)
Antes de comprar qualquer ferramenta ou treinar qualquer bot, você precisa saber onde está parado. O que precisa medir, idealmente com seis meses de histórico:
- Volume total de tickets/mês: média, mediana, pico da semana.
- Distribuição por categoria: usar as 6 categorias da primeira seção como base, ajustar ao seu produto.
- Top 20 consultas por frequência: agrupar tickets por similaridade e ordenar. Você vai descobrir que 20 consultas explicam 70% do volume.
- AHT médio por categoria: quanto tempo sua equipe humana leva para resolver cada tipo.
- CSAT atual: o baseline contra o qual você vai comparar depois.
- Tickets escalados / reabertos: % de tickets que não se resolvem no primeiro contato. Esse número raramente é medido e é dos mais importantes.
Saída desta fase: um documento de uma página com o estado atual. Sem isso, qualquer melhoria posterior é invisível.
Fase 2: Self-service estruturado + Bot NLP (semana 3-8)
Implementação das camadas 1 e 2 em paralelo. Em seis semanas você precisa ter:
- Help Center com os 30-50 artigos que cobrem o top 20 de consultas. Cada artigo com título claro, resposta direta nos dois primeiros parágrafos, e vídeo ou screenshot quando aplicável.
- FAQ contextual dentro do produto (botões de ajuda nas telas críticas).
- Bot NLP treinado sobre os 20 intents mais frequentes. Mínimo de 50 exemplos por intent.
- Handoff para humano sempre visível e funcional, com captura do contexto prévio.
Deflection esperado ao final da Fase 2: 25-40%. Se o baseline era 100 tickets/dia, agora você vai estar entre 60 e 75. Se o número não cai nessa faixa, há um problema de implementação, não de tecnologia.
Esta fase é a mais subestimada. Empresas que pulam direto para "Agente de IA generativo" sem ter as Camadas 1 e 2 funcionando acabam com a IA respondendo o que um FAQ bem escrito já responderia, a um custo de tokens que não se justifica.
Fase 3: Agente de IA generativo + Copilot (semana 9-20)
Aqui entram as ferramentas mais sofisticadas. Nas 12 semanas seguintes:
- Conectar um LLM (GPT-5.4 ou equivalente) à sua base de conhecimento via RAG. Isso requer chunking da sua documentação, embeddings e um bom prompt de sistema.
- Conectar o Agente de IA com dados da conta do cliente via API (plano atual, status de uso, tickets anteriores). Sem isso, o Agente de IA é um FAQ chatty, não um assistente.
- Implementar o Copilot para a equipe humana: quando um ticket escala, o agente recebe contexto + resumo + sugestões de resposta.
- Definir as regras de handoff: quando escala automaticamente (consulta de billing crítica, erro de bug confirmado, conta enterprise, cliente com NPS baixo no histórico).
- Audit log de cada interação de IA para review manual semanal.
Deflection esperado ao final da Fase 3: 45-60% acumulado. Se você chega nisso com CSAT post-deflection ≥ CSAT geral, ganhou.
Fase 4: Loop de melhoria contínua (contínuo)
Esta não termina nunca. Cadência operacional semanal:
- Review de consultas não resolvidas: aquelas que o cliente reescalou ou abandonou. Ajustar prompts, adicionar artigos ao Help Center, retreinar intents.
- Refresh da base de conhecimento: cada feature release ou mudança de pricing deve se propagar para a base da IA em menos de 24 horas.
- Monitoramento de drift do CSAT post-deflection: se cair 5 pontos versus o baseline, pausar novas automações e investigar.
- A/B testing de prompts: a diferença entre um prompt de sistema medíocre e um bom é de 10-15 pontos de deflection com o mesmo modelo.
Se tudo isso soa como um processo operacional permanente, é porque é. A boa notícia é que é um processo operacional previsível e que escala. A menos boa é que muitas empresas SaaS não têm a capacidade interna para sustentá-lo, e aí é onde um setup managed (mais sobre isso no final) faz sentido.
KPIs para monitorar o sistema
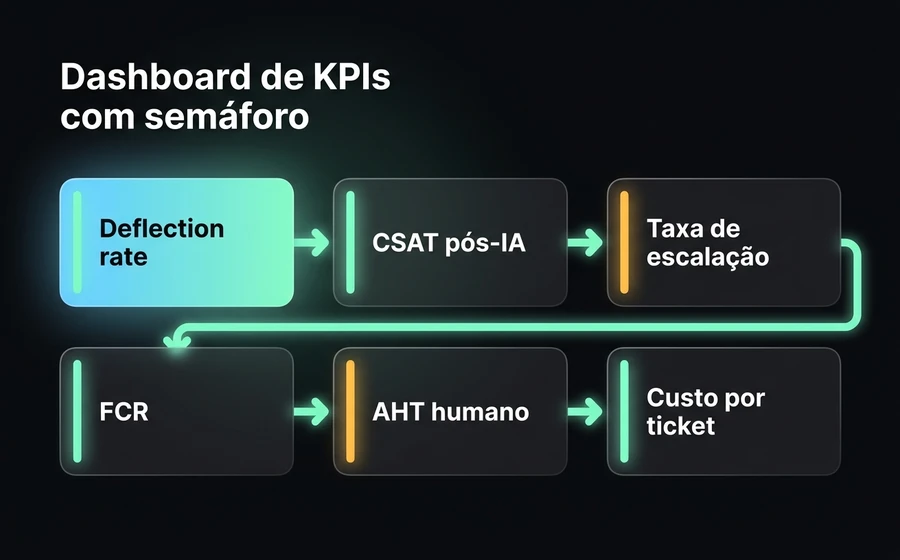
Aqui está o dashboard mínimo que um Head of Support deveria ter para operar este sistema. Os seis KPIs core, com seus thresholds de referência para SaaS B2B maduro:
| KPI | O que mede | Verde | Amarelo | Vermelho |
|---|---|---|---|---|
| Deflection rate | % de consultas resolvidas sem escalar | >50% | 30-50% | <30% |
| CSAT post-deflection | Satisfação após interação com IA, sem escalonamento | ≥CSAT geral | -5 a -10pts | <-10pts |
| Escalation rate | % de consultas escaladas para humano | <40% | 40-60% | >60% |
| First Contact Resolution (FCR) | % de tickets resolvidos no primeiro contato (humano + IA) | >75% | 60-75% | <60% |
| AHT humano (com Copilot) | Tempo médio do agente humano | -25% vs baseline | -10 a -25% | sem melhoria |
| Custo por ticket | OPEX total de suporte / tickets totais | -30% vs baseline | -10 a -30% | sem melhoria |
Algumas notas sobre interpretação:
- Deflection rate e CSAT post-deflection sempre se observam juntos. Subir um derrubando o outro não é ganhar.
- FCR é a métrica mais negligenciada. Um ticket que se resolve "rápido" porque o cliente abandonou não é um ticket resolvido. Meça FCR em 48h, não em 24h.
- AHT humano com Copilot deve cair 25-40% segundo McKinsey e benchmarks próprios. Se não cai, o Copilot não está bem implementado (provavelmente não passa o contexto completo ao humano). Veja AHT no WhatsApp: benchmarks para mais contexto sobre como medir AHT em canais conversacionais.
- Custo por ticket é a métrica que importa ao CFO. Se você quer justificar o investimento, é bom ter um modelo de ROI montado com antecedência, escrevemos em detalhe em ROI de um chatbot: a fórmula completa.
Adicionalmente, vale a pena ter duas métricas de saúde do sistema:
- % de consultas não entendidas pela IA: se passa de 15%, há um problema de cobertura da base de conhecimento.
- Latência média de resposta do Agente de IA: se passa de 8 segundos, os clientes começam a abandonar antes de ler.
Por que AsisteClick (e quando vale a pena managed service)
Você chegou até aqui, o que é um bom sinal. Antes do fechamento, uma observação honesta: muitas empresas SaaS tentam implementar isso self-serve e travam. Não é por falta de tecnologia (as ferramentas existem e são acessíveis), é pela curva de operação: treinar um bot NLP bem, montar um RAG funcional, ajustar prompts iterativamente, sustentar o loop de melhoria contínua, integrar com seu stack atual (Zendesk/Intercom/Freshdesk via API, dados de conta, single sign-on). Isso requer um perfil que poucas empresas SaaS de 50-500 funcionários têm full-time na equipe.
AsisteClick oferece este sistema como managed service: nossa equipe cuida do setup das três camadas, do treinamento do bot NLP sobre seu histórico real, da conexão do Agente de IA com sua base de conhecimento (via AsisteGPT e AsisteCopilot), das integrações com seu CRM/billing e do loop operacional semanal. Sua equipe foca no produto e nos clientes; nós nos encarregamos de reduzir o volume de tickets sem que você precise contratar uma equipe interna de Conversational AI Engineers.
Se você já tem uma equipe técnica que quer implementar isso self-serve, nossa plataforma e a API de integração estão disponíveis. Se você prefere delegar o setup e a operação, conversamos sobre um escopo de projeto com onboarding assistido.
Em qualquer um dos dois modos, o objetivo é o mesmo: que em seis meses o relatório de suporte mostre uma taxa de deflexão de 45-60% com CSAT estável ou melhor, custo por ticket em queda e uma equipe humana que dedica seu tempo às consultas que de fato precisam.
Perguntas frequentes
Quanto tempo leva para ver resultados de redução de tickets?
Os primeiros resultados aparecem entre 30 e 60 dias se as quatro fases do roadmap forem seguidas. A Fase 2 (self-service + bot NLP) entrega entre 25% e 40% de deflection rate em seis a oito semanas. A Fase 3 (Agente de IA generativo + Copilot) soma entre 15 e 25 pontos adicionais nos três meses seguintes. Esperar resultados sólidos antes de 30 dias é pouco realista; passar de seis meses sem ver melhoria indica um problema de implementação, não de tecnologia.
Que deflection rate posso esperar de forma realista para um SaaS B2B?
Com um bot NLP sozinho, o deflection rate realista fica entre 15% e 25%. Somando um Agente de IA generativo com RAG sobre a base de conhecimento, chega a 40% a 55%. Com a operação madura (camadas 1-2-3 trabalhando seis meses com loop de melhoria contínua), 50% a 65%. Acima de 70% o risco de degradar o CSAT cresce rápido, e acima de 80% geralmente a medição não é honesta ou estão automatizando consultas que não deveriam ser automatizadas.
É compatível com Zendesk, Intercom ou Freshdesk?
Sim, a AsisteClick se integra via API com os principais help desks. A integração típica deixa o sistema de tickets (Zendesk, Intercom, Freshdesk) como sistema de registro e adiciona a camada conversacional da AsisteClick por cima: o cliente interage com o Agente de IA por WhatsApp, webchat, e-mail ou o canal que usa, e os tickets escalados aparecem no seu help desk atual com todo o contexto prévio. Não requer substituir a ferramenta existente.
O que acontece com os tickets técnicos complexos que não podem ser automatizados?
Os tickets técnicos complexos (erros reais, comportamento inesperado, integrações custom) não se auto-resolvem e não deveriam tentar se auto-resolver. O que muda é o papel do Agente de IA: em vez de tentar responder, faz a triagem (captura o problema, dados da conta, passos para reproduzir) e escala ao humano com um ticket pré-montado. O Copilot reduz o AHT do agente humano de 25% a 40% sobre essa categoria porque começa com contexto completo em vez de zero.
Preciso de uma equipe técnica interna para implementar isso?
Depende do modo. No modo self-serve sim: você precisa pelo menos de um perfil que entenda APIs, integrações, prompt engineering e operação de suporte. No modo managed service com AsisteClick, não: nossa equipe cuida do setup técnico, do treinamento do bot, da conexão com sua base de conhecimento e da operação do loop semanal. A decisão típica é: se você já tem uma equipe de Conversational AI ou um CTO com bandwidth, self-serve funciona; se não, managed service evita seis meses de curva de aprendizado.
E se o Agente de IA der uma resposta incorreta a um cliente?
Três proteções em camadas: (1) escalonamento obrigatório a humano quando a confiança do modelo está abaixo de um threshold configurado ou quando aparecem palavras-gatilho (cancelamento, queixa formal, executivo); (2) audit log completo de cada interação para review manual semanal; (3) feedback loop do cliente diretamente (um thumbs up/down depois da resposta) que se incorpora ao retreinamento. O caso Klarna é ilustrativo justamente porque parece ter subdimensionado isso: respostas incorretas em produção sem guardrails nem audit terminam em problemas de marca. A arquitetura de 3 camadas com escalonamento sempre visível é a rede de segurança.
Conclusão
Reduzir tickets de suporte SaaS com um Agente de IA não é uma questão de tecnologia, é uma questão de arquitetura, medição e disciplina operacional. A tecnologia hoje permite chegar a 45-60% de deflection rate em seis meses com CSAT estável; o que separa as empresas que conseguem das que não conseguem é ter medido antes de automatizar, ter respeitado as três camadas em ordem e ter sustentado o loop de melhoria semanal.
Se você quer ver como essa arquitetura fica aplicada ao seu caso — com AsisteGPT, AsisteCopilot e a integração com seu help desk atual —, veja a plataforma de Agentes de IA da AsisteClick o agende uma demo e mostramos que porcentagem do seu volume de tickets atual seria razoável deflectir nos próximos seis meses.
Continue lendo
- Klarna e o erro de IA em customer service — análise completa do caso que ilustra cada anti-pattern
- Copilot de IA para agentes em tempo real — como a IA potencializa o humano sem substituí-lo
- As 3 camadas de conhecimento de um Agente de IA — o detalhe técnico do RAG na Camada 3