
From searching to asking: the shift that's already happening
There's a data point worth keeping in mind before any GEO discussion: traditional search isn't dying, it's losing share. Google still processes billions of queries per day. But the discovery pie is being redistributed, and the slice taken by generative AI engines grew from something marginal in 2023 to a structural channel in 2026.
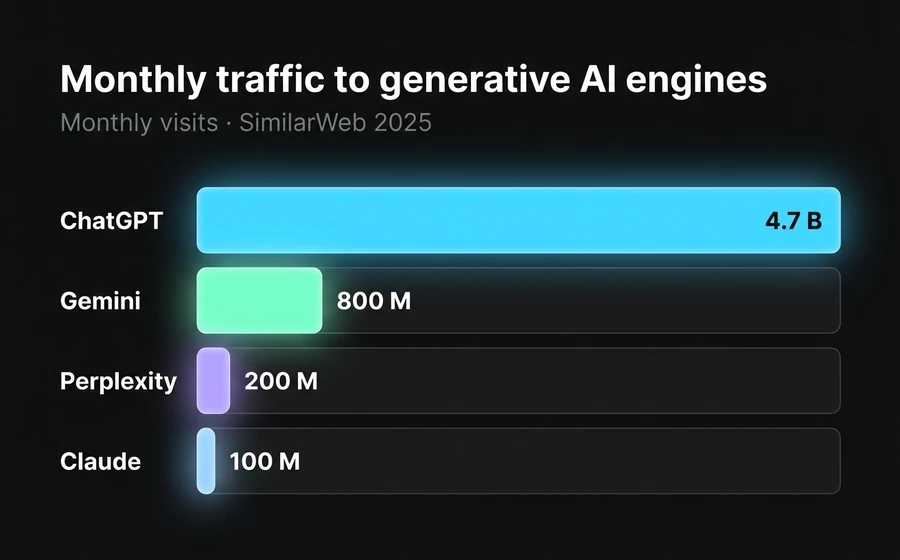
Public data backs this from several angles. SimilarWeb recorded in May 2025 that ChatGPT received 4.7 billion monthly global visits, with 137% year-over-year growth. Perplexity, more niche but growing at 200% YoY, passed 200 million visits. Google added AI Overviews (the generated answers that appear above the traditional SERP) in more than 60% of informational queries, according to Authoritas and SE Ranking measurements from March 2026. And native AI search engines — OpenAI's OAI-SearchBot, Anthropic's Claude-SearchBot, the ChatGPT Search launched in late 2024 (the difference between these engines we cover in the NLP vs GPT vs hybrid comparison) — are now an independent traffic channel that any site with LATAM presence should measure separately.
The shift matters because the two logics are different. In a traditional search, you produce the document and the user decides whether to click. The distance between you and the user's decision is one click. In a query to an LLM, you produce the document, the model processes it, and delivers a synthesis to the user. The distance between you and the decision is one citation — if it mentioned you, you won attention; if not, you don't exist. And unlike classic SEO, where two results can coexist on page one, in a ChatGPT response only three or four names make it in. The space is brutally more finite.
That explains why companies that understood the shift early are investing in GEO with the same seriousness they invested in SEO in 2010: it's not optional, it's the next layer of visibility. The difference is that the technical playing field is still forming. The rules aren't written with the detail of Google's guidelines. There are emerging standards (the llms.txt proposed by Jeremy Howard in September 2024), signals we know matter (semantic structure, topical authority, freshness) and many reasonable hypotheses being validated with data.
The operational question is the same as always: how do you increase the probability that your brand appears when someone asks? The difference is that the answer changed.
How an LLM cites you: the technical pipeline
To understand why some things work in GEO and others don't, it's worth looking at how a language model produces an answer when someone asks about your brand or your vertical. There are three layers operating simultaneously, and each one has different mechanics.
Layer 1: training data (knowledge cutoff). Each model has a training corpus with a cutoff date. GPT-5 was trained with data through early 2025. Claude Opus 4 through March 2025. Gemini 2.5 through early 2025. This means the model's "stable" knowledge of your brand depends on what your brand had published and how it was cited up to that date. If your site already existed and had authority, the model already has internal representations of you. If you just launched two months ago, it doesn't.
This layer is the hardest to modify in the short term: you don't control when the next model gets trained. What you do control is what corpus it finds when it trains: if your content is exhaustive, citable, well-structured and referenced by third parties, it will enter the training set with greater weight (we cover this in detail in the 3 knowledge layers of an AI Agent). It's classic SEO taken to another plane.
Layer 2: real-time retrieval (RAG and search grounding). This is the short lever of GEO. Most modern engines don't answer only from their weights: they perform a live search when they receive your question. ChatGPT with search enabled (via ChatGPT Search and the OAI-SearchBot), Perplexity (which is RAG-first by design), Claude with web search enabled (Claude-SearchBot), Google Gemini with integrated search grounding. All of them query the web while generating the response.
That search uses signals different from Google. Perplexity, for example, prioritizes sources it considers "authoritative" — a mix of established domains, content quality, and match with the query. ChatGPT Search, according to OpenAI's public statements, weighs editorial presence, update frequency and structure. What almost all of them share is the preference for content that can be ingested clean: semantic HTML, structured data, clear headers, and files like llms.txt that tell them where to find the relevant content without having to crawl a hundred pages.
Layer 3: synthesis with or without citation. Once the model has material (from its training + from retrieval), it produces the answer. And here there's a decision the model makes on the fly: does it mention the source or not?
Perplexity always cites. It's part of its product. ChatGPT Search cites most of the time. Claude cites when the model considers the information comes from an identifiable source. Gemini cites selectively. And in "off-search" responses (when the model doesn't need to search because it already knows), citations are rare or nonexistent.
The operational implication is huge: your goal isn't just to appear in the response, it's to appear cited with your URL. A mention without a link is something. A mention with a link to your site is traffic, conversion and accumulated authority. Modern GEO practices optimize for the second.

GEO vs classic SEO: what changes
If you think of GEO as "SEO on steroids" you'll optimize for the wrong engine. There are structural differences that change the tactics.
| Dimension | Classic SEO | GEO |
|---|---|---|
| Unit of success | Position in SERP | Citation in generated response |
| Competition density | Top 10 visible, top 3 with high CTR | 3-5 brands mentioned at most |
| User intent signal | Keyword (sometimes ambiguous) | Complete natural question |
| Authority | Backlinks, domain, expertise | Cross citations + semantic structure + prior presence in training set |
| Freshness | Crawl rate + sitemap | Model cutoff + live retrieval |
| Long-tail | Long tail of keywords | Long tail of questions (much more diverse) |
| Direct metric | Ranking, clicks, impressions (GSC) | Citations (no unified equivalent — must be measured manually or with external tools) |
| Volatility | Movements from algorithm updates | Changes from new model versions + changes in retrieval logic |
| Traffic path | SERP → your site | Question → synthesized response → citation → your site (more friction) |
Both disciplines share a base: quality content, fast site, clear structure, topical authority. The difference is what you add on top.
For classic SEO the levers are keywords, backlinks, speed and user satisfaction measured by dwell time. For GEO the lever is citability: how easy it is for a model to understand what you do, find the right information about you, and decide to mention you as the answer to a specific question. A pretty but opaque homepage can rank well on Google and be invisible in ChatGPT. A dense, structured page with clear definitions and data can rank mediocre on Google and be cited by Perplexity every week.
There's a detail many GEO guides underestimate: classic SEO is not replaced. Conserving your indexed traffic is the floor. GEO is built on top. The two optimizations reinforce each other: content that ranks well on Google is the content that enters the training set of models in the next iteration. Canceling SEO to "go GEO" is a rookie mistake. The right thing is to do SEO well AND add the GEO layer.
The 2026 GEO technical stack
This is the dense part of the guide. Five technical layers any site can implement in a week of work. We'll use asisteclick.com as reference because it's what we have live and publicly inspectable.
4.1 llms.txt: the Howard standard
Jeremy Howard (co-founder of Answer.AI, fast.ai) proposed in September 2024 a simple standard that many sites are already adopting: a llms.txt file in the domain's root that gives the LLM a structured map of the site. It's not a crawler config. It's editorial content meant to be read by a model.
The structure is markdown and has three blocks:
# Site name
> Executive summary in one or two sentences explaining what the site does.
Optional context block: who, where, scale, value proposition.
## Section 1
- [Page title](url): Brief description.
- [Another page](url): Brief description.
## Section 2
...The trick is that the first blockquote line (>) is the "elevator pitch" that an LLM can quote literally if the question is "what is X?". The summary you write there, in your own words, is exactly what a model will use when a user searches for you. If your blockquote is generic, your citation will be generic.
Our llms.txt (published at asisteclick.com/llms.txt, 22 KB, publicly accessible) opens like this:
AsisteClick is an omnichannel customer service SaaS platform with AI chatbots. It unifies WhatsApp, Facebook, Instagram, Telegram, email and webchat with GPT/NLP bots, native CRM and bulk messaging.
One sentence. Category (customer service SaaS). Differentiator (omnichannel with AI). Stack (channels). Key modules (bots, CRM, bulk messaging). If a model needs to answer "what is AsisteClick" in thirty words, that's the answer. Without that explicit sentence, the model improvises — and an LLM improvising about your brand is exactly what you want to avoid.
Then come the sections: products, channels, vertical solutions, integrations, blog. Each link has a one-line description. It does not replicate the content of each page: it gives enough context for the model to know when to recommend it. If someone asks "what chatbot for real estate do you recommend?", the model sees the line "WhatsApp for real estate: answers, qualifies and books visits" and connects the match.
4.2 llms-full.txt: curated full content
If llms.txt is the map, llms-full.txt is the content. It's a heavier file (1 MB in our case) that concatenates the relevant site pages in plain markdown, without navigation, without scripts, without bloat. It's what you want an LLM to ingest if it decides to dig deeper.
Why two files? Because models have context windows. The llms.txt of 22 KB fits in any window. The llms-full.txt of 1 MB fits in GPT-5 (which has extended context) but not in smaller models. By offering both, you let the client choose according to their capacity.
The operational rule for llms-full.txt: include the pages you want a model to learn deeply — core products, case studies with metrics, comparisons, exhaustive FAQs, blog pillar posts. Exclude: legal pages, indexes, navigation, obsolete content. Plain markdown without exotic tables. Each section with its canonical URL next to it so the model can link.
4.3 robots.txt for AI crawlers: the explicit policy
The robots.txt was always SEO territory. In 2026 it's also GEO territory, but with a twist: there are now 20+ new user-agents corresponding to AI bots, and each one performs a different function. You need an explicit policy, not an omission.
The main bots to consider:
| Bot | Company | Function |
|---|---|---|
GPTBot |
OpenAI | Crawl for training |
ChatGPT-User |
OpenAI | On-demand fetch when a user mentions your URL in ChatGPT |
OAI-SearchBot |
OpenAI | Crawl for ChatGPT Search |
ClaudeBot |
Anthropic | Crawl for training |
Claude-Web |
Anthropic | On-demand fetch |
Claude-User |
Anthropic | User-initiated on-demand fetch |
Claude-SearchBot |
Anthropic | Crawl for search |
PerplexityBot |
Perplexity | Crawl + retrieval |
Perplexity-User |
Perplexity | On-demand fetch |
Google-Extended |
Separate opt-in for Gemini training (does not affect Google Search indexing) | |
Bytespider |
ByteDance / TikTok | Crawl for Doubao |
Meta-ExternalAgent |
Meta | Crawl for LLaMA |
Amazonbot |
Amazon | Crawl for Alexa / Q |
Applebot-Extended |
Apple | Separate opt-in for training |
The strategic decision: do you allow everything, block everything, or apply a mixed policy? All three are valid depending on the case.
- Allow all (ours): maximize the probability of appearing in any LLM. Makes sense if your business model benefits from visibility, you don't need to protect premium content and your public publication is already the offering.
- Block training, allow retrieval: block
GPTBot,ClaudeBot,Google-Extended(all those that train), but allowChatGPT-User,Claude-User,OAI-SearchBot,PerplexityBot. Makes sense if you want to be cited in real time but not become part of the next model "for free". It's the policy of many large media outlets (New York Times, Wall Street Journal). - Block all: block all AI bots. Makes sense only if your content is proprietary, your model is strict paywall and you don't want any leakage.
Our complete policy in asisteclick.com/robots.txt is explicit ALLOW ALL for AI crawlers. We chose it because AsisteClick sells to a LATAM market where visibility in LLMs is the next discovery frontier, and blocking bots would be blocking market share in formation.
4.4 Schema.org: the structured signal LLMs do read
Structured data with JSON-LD has existed for years for SEO. But LLMs read it with more enthusiasm than Google in some cases, because it lets them parse the content unambiguously. Three types that matter especially for GEO:
Articlein posts: include author, publication date, modification date, description, headline. An LLM evaluating whether your post on "WhatsApp Business API" is citable looks at thedateModifiedto know if the information is still current.Organizationon the home page and footer: include name, logo, description, address, contacts, social media, founders. It's the "business card" for entities — LLMs build entity representations from this data.FAQPagewherever you have visible FAQ: each question-answer becomes parseable. This is pure gold for GEO: when someone asks an LLM "how does X work?", the model can lift the answer from your FAQ almost verbatim.
An important technical decision: use JSON-LD in <script type="application/ld+json"> and not microdata in HTML. JSON-LD is what LLMs read easily. Microdata is more deprecated.
4.5 Other signals: Open Graph, sitemap, HTML semantics
Three minor signals but they add up:
- Complete Open Graph with
og:title,og:description,og:image,og:type: although originally designed for social media, LLMs use it as a concise description when they can't find anything better. - XML sitemap with
lastmodreal: AI crawlers prioritize fresh pages. If your sitemap says everything was modified today, they don't believe you. If it says real dates, they crawl you at the correct frequency. - Semantic HTML:
<article>,<section>,<header>,<main>,<aside>. Sounds basic but many sites use<div>for everything. LLMs process semantic structure better than<div>-soup.
Citability audit: 10-point checklist
Ten actionable criteria to self-assess whether your site is GEO-ready. Each one adds or subtracts probability of being cited. Audit one by one with your domain in mind.
- Do you have
/llms.txtpublished and publicly accessible? If the answer is no, this is the first step. - Does the first sentence of your home answer "what does X do" in fewer than 30 words? If you need 200 words, the LLM won't cite you there.
- Does your
robots.txthave explicit rules for AI crawlers? Not implicit rules. Explicit. Bots read what's written. - Does your blog have JSON-LD
Articleon each post? If not, models have to infer author and date. Inference = loss of confidence. - Are your FAQs marked up with
FAQPageschema? If your FAQ is plain text without schema, LLMs process it, but they lose the question-answer structure that's ideal for citing it. - Does your pillar content have 3000+ words with logical H2/H3 headers and concrete data? LLMs don't cite generic 500-word posts. They cite exhaustiveness.
- Do you mention your own numbers, named cases and verifiable metrics? "We increased sales by X%" without context isn't cited. "Client Y went from 1% to 3% conversion in 6 months with AsisteClick" is.
- Does your site load without heavy JS? Some models do retrieval with engines that execute JS, others don't. If your content is behind a JS render, content invisible to
curlis invisible to the LLM in many cases. - Is your brand mentioned on authoritative sites in your vertical (media, partners, aggregators)? Cross citations are the currency of authority for LLMs the same way backlinks are for Google.
- Do you have a content update protocol? Posts with
dateModifiedfrom two years ago lose weight. Refreshing pillars every 6-12 months is part of the job.
If you check 8 or more, you're in the front row of GEO-ready brands in your vertical in LATAM. If you check 4-7, there's clear work ahead. If you check fewer than 4, the upside of investing in GEO now is enormous: any step adds up.

How to measure if it's working
Here we'll be honest: GEO measurement in 2026 is still forming. There's no Search Console for LLMs. What does exist are three types of signals that, combined, give you a useful picture.
Signal 1: referrals in GA4. Configure GA4 to detect referrals from chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. When a user clicks on a citation an LLM put in its response, that traffic reaches your site with those referrers. It's the most direct citation-with-conversion metric.
In GA4, create a custom channel "AI Referrals" with those domains. If you start from zero, the volume will be low (LLMs still cite little with clicks). But the trend matters more than the absolute number. If it goes from 5 sessions/month to 50/month in six months, you're on the right track. If it stays at zero, there's a citability problem.
Signal 2: Google Search Console for natural queries. Although counterintuitive, GSC remains useful for GEO. Why? Because the queries that appear there — "what is X", "how does Y work", "differences between A and B" — are exactly the queries people ask an LLM. If your site appears for those queries on Google, there's a high probability it also appears in LLMs. GSC is your proxy for "covered conversational intent".
Filter in GSC by queries that start with "what", "how", "which", "why", "when". Those are your conversational queries. The volume and ranking there tell you your competitive position in conversational intent, which partially transfers to GEO.
Signal 3: systematic manual tests. Once a month, follow this protocol:
- List of 10-20 questions a potential customer would ask an LLM about your category (not about your brand: about the category).
- Ask ChatGPT (with search enabled), Perplexity, Claude, Gemini.
- Record: do they mention you? How? With or without a link? Before, during or after competitors? Is the description they give of you the one you want?
- Compare month over month.
It's manual work, but until automated monitoring tools mature, it's the most reliable method. There are emerging commercial tools — Otterly, BrandRanker, Profound, HubSpot AI Search Grader, AthenaHQ — that automate part of this. Worth evaluating if your vertical is competitive. Most start with free or low-cost plans for tracking a few brands/queries.
Signal 4 (advanced): server logs. AI crawlers leave their user-agent in your logs. Filter by GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot. The frequency with which they visit you is a leading indicator: if they visit little, they're discovering you little. If they visit a lot, there's model interest in your content. This is a noisy but useful proxy.
AsisteClick case: what we did
Our GEO implementation began in March 2026, in the broader context of migrating the asisteclick.com site from WordPress to Astro (a change that has its own story, but which opened the opportunity to treat GEO as part of the technical design from the start instead of bolt-on later).
The current stack, all public and verifiable:
asisteclick.com/llms.txt— 22,939 bytes. Executive summary + 10 products + 7 channels + pricing + 11 verticals + 5 integrations + 32 blog posts + 7 case studies. Plain markdown, automatically generated from the site metadata.asisteclick.com/llms-full.txt— 1,003,695 bytes (~1 MB). Full content of the key landings and blog pillar posts, concatenated in markdown without bloat. For models with large context windows that want to dig deeper.asisteclick.com/robots.txt— explicit ALLOW ALL policy for 20+ AI user agents. Inline comment that documents the decision and keeps the logic auditable.- JSON-LD
Article+FAQPage+BreadcrumbListin the 30+ blog posts, generated at build time from the meta of each post. - JSON-LD
Organizationon the home page with structured company info. - XML sitemap with
lastmodreal and multi-language hreflang (es/en/fr/pt).
Behind the stack is a proprietary skill (/ai-seo) that automates the regeneration of llms.txt y llms-full.txt every time a new post is published or a landing is changed. This is important because maintainability is where GEO usually fails: the llms.txt that are outdated three months after publication are the rule, not the exception.
Results? Here comes the honest part: we have few months of tracking, so the numbers are preliminary. We see growth in referrals from chat.openai.com y perplexity.ai in GA4 (from zero to a couple of sessions per week), an increase in conversational queries in GSC (impressions for "what is an AI agent", "how to choose a WhatsApp chatbot", etc.), and anecdotal improvements in manual tests: ChatGPT started mentioning us when asked about "WhatsApp Business platforms for SMBs in LATAM", which it didn't do in January. It's not evidence of scale. It's evidence of method. The solid conclusion we'll be able to give by the end of 2026 with two more quarters of data.
The method is replicable regardless of our numbers. The hours investment: one week of a dev to implement the base stack, plus a monthly audit routine (4 hours) and maintenance of the llms.txt (1 hour per new publication).
Anti-patterns: what doesn't work in GEO
The other side of the checklist: errors that are frequently made and that actively reduce your probability of being cited.
1. Adapted keyword stuffing. Some sites are building llms.txt with lists of keywords and variants ("chatbot WhatsApp, chat bot whatsapp, chatbot wapp, bot WhatsApp..."). LLMs detect the pattern and devalue. The Howard standard is markdown with natural descriptions, not keyword lists. If your llms.txt looks like an Ahrefs dump, you're doing it wrong.
2. AI-about-AI content without an angle. The GEO topic is going to explode this year. You'll see an avalanche of generic posts about "how to appear in ChatGPT" written by AI without verification, repeating the same four tips. Those posts aren't citable because they don't bring new information. If you're going to write about GEO, do it with your own angle (case, data, specific vertical).
3. Paywall on pillar content. If your best content is behind a login or paywall, AI crawlers don't read it. There's a legitimate debate about how much to release for free, but strategically, the pillar content you want ChatGPT to cite needs to be public.
4. JavaScript-heavy rendering. If your site renders the main content with JS and a basic crawler doesn't see it, it depends on the bot whether it processes it. GPTBot y ClaudeBot don't execute JS in all cases. Server-side rendering or static generation is safer.
5. Hidden content for LLMs ("cloaking"). Some are testing serving different content to humans vs LLMs (extra text invisible to humans but parseable by crawlers). This is the 2026 version of black-hat SEO and it will end up penalized just like 2010s cloaking. Don't do it.
6. Generic listicles without substance. "10 best X platforms", "7 tools for Y" without clear criteria and without differentiators. LLMs read them but don't cite them: there are infinite lists like those. What gets cited is analysis with criteria and data.
7. Outdated information without a date marker. Posts from 2022 without dateModified updated, talking about prices and features that changed. Modern models check dateModified. If there's none, they assume worst case.
8. Robotic generated tone. Curiously, AI-generated content without human editing has less chance of being cited by AI. Models detect the pattern and devalue. The paradox is real: for AI to cite you, you have to sound human.
Five actionable steps this week
If you want to start without waiting, this is the minimum viable order:
Day 1 — Publish your /llms.txt. One hour of work. Take your home, break it into blocks (products, services, resources), write a blockquote line that says what your company does, list the main URLs with a one-line description. Upload it to the domain root. If you have WordPress, you can generate it with a plugin (LlmsTxt, AI SEO or similar) or upload it manually.
Day 2 — Update your robots.txt. Thirty minutes. Decide your policy (ALLOW ALL, block training, mixed) and write explicit rules for the 15+ user-agents listed above. Test it with curl https://tudominio.com/robots.txt to confirm it's being served.
Day 3 — Audit your Schema.org. One hour. Use the Google Schema Validator to see what JSON-LD you have on your home, on a blog post and on a product landing. If Organization, Article o FAQPageis missing, add it. If your site is WordPress, there are plugins (RankMath, Yoast, SchemaPro) that automate it.
Day 4 — Configure GA4 for AI Referrals. Thirty minutes. In GA4, create an "AI Referrals" view with source domains chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Start tracking from today to have a baseline.
Day 5 — Systematic manual test. One hour. Write 10 questions a potential customer would ask an LLM about your category. Ask them in ChatGPT, Perplexity, Claude. Record who mentions you, how, in what order. Save screenshots. Repeat in 30 days to measure progress.
With those five steps in one week, you're in the top quartile of brands doing GEO seriously in LATAM in 2026. What follows (maintaining the llms.txt, refreshing pillar content, monitoring referrals, iterating the stack) is ongoing operations. But the foundation is built in five days.
If your team is marketing but not tech, and you need a partner to handle the technical stack and the operations of conversational content optimized for LLMs (not just SEO), at AsisteClick we offer turnkey implementation of this GEO layer for existing and new clients. The difference vs a generic SEO freelancer: our team built the stack for our own site and maintains it as production.
Frequently asked questions
What is Generative Engine Optimization (GEO)?
GEO is the set of technical and editorial practices that increase the probability that your brand, product or content will be mentioned by generative search engines like ChatGPT, Perplexity, Claude or Gemini when a user makes a related query. It doesn't replace classic SEO: it complements it, optimizing for a different unit of success (citation in synthesized response instead of position in SERP).
Is GEO the same as AEO (Answer Engine Optimization)?
They are close terms with nuances. AEO emerged earlier and referred more to appearing in Google "answer boxes" and featured snippets. GEO is broader: it includes generative engines (LLMs) that produce synthesized responses with or without real-time search. In practice, much content overlaps. AIO ("AI Optimization") is a third term in use. For practical purposes, GEO is the most used in 2026 and covers the entire spectrum.
How long does it take to see GEO results?
Retrieval effects (citation in responses the model searches live, like Perplexity or ChatGPT Search) are seen in weeks: if you publish llms.txt, update robots.txt and improve the structure, AI crawlers discover the change in 1-4 weeks. Training effects (your brand being better represented in the next model) are seen in months, because they depend on when the next version of the LLM is trained. Reasonable timeframe to measure GEO seriously: 6 months minimum.
Do I need to deindex from Google if I publish llms.txt?
No. llms.txt doesn't affect your indexing on Google. They are independent systems. Google ignores llms.txt (it's not a standard it uses), and AI crawlers read llms.txt in addition to your normal site. Doing GEO doesn't mean sacrificing SEO; on the contrary, they are synergistic.
How do I know if ChatGPT or Perplexity are already citing my brand?
Three methods: (1) manual test — ask questions about your category in each engine and record whether they mention you; (2) referrals in GA4 from domains like chat.openai.com y perplexity.ai; (3) commercial monitoring tools (Otterly, BrandRanker, Profound) that automatically track brand mentions in LLMs. The manual test is free and sufficient to start. Tools are useful when your vertical is competitive and you need continuous tracking.
Does blocking training bots benefit or harm me?
It depends on your business model. If your content is proprietary and monetized (media, paywall, database), blocking training can make sense to not "give away" the corpus to the next model. If your content is marketing and you want maximum visibility, it's better to allow everything. A common mixed policy: allow retrieval bots (which can cite you in real time with a link) and block training bots (which ingest your content to train the next model). Each company decides according to priorities.
Is there a platform that combines customer service with presence in LLMs?
Today they are separate layers: GEO is managed from your site (llms.txt, schema, content), and AI customer service is managed from a platform like AsisteClick that integrates WhatsApp, web, Instagram and CRM with proprietary AI agents. What you do share between both is the knowledge base: the content ChatGPT cites to answer for you in general, and the content your own AI agent uses to answer customers on WhatsApp, ideally come from the same curated corpus. Building that base once and using it across both channels is the next frontier of efficiency for marketing and customer experience teams.