
On March 5, 2026, OpenAI launched GPT-5.4. A week later, it released the mini and nano variants. Today, all three coexist in AsisteClick's AI Agent template catalog: each solving a different problem, with cost and latency profiles that differ by an order of magnitude.
If you are building an AI Agent on WhatsApp, a copilot for your support team, or a sub-agent that solves a specific task, the choice of model defines 70% of the product's economics: cost per conversation, perceived response time, and autonomous resolution rate.
This guide compares GPT-5.4 mini vs nano vs default with official OpenAI data, published benchmarks, and concrete use cases from the AsisteClick catalog. By the end, you will know exactly which model to choose for each type of agent, how much it will cost you, and when it's advisable to scale up to the flagship.
The GPT-5.4 family: what changed compared to GPT-5
GPT-5.4 is the first family that OpenAI launched with native computer-use integrated into the base model (not as an external tool), 1 million context tokens in the flagship version and a mechanism for tool search that reduces token cost in tasks with many tools by up to 47%.
The three models share:
- Knowledge cutoff: August 31, 2025.
-
Modalities: text and image input, text output. Audio and video not supported (for audio, you still need
gpt-4o-audioor Whisper). - API capabilities: function calling, structured outputs, streaming, parallel tool use.
- Tool use: web search, file search, code interpreter, image generation, skills, MCP.
What changes between them is reasoning power, context size, cost per token, and latency. And that difference is what forces you to think like an architect before issuing a prompt.
Official Specifications: the 3 variants in a table
Data extracted from the official OpenAI documentation as of April 19, 2026.
| Specification | gpt-5.4 | gpt-5.4-mini | gpt-5.4-nano |
|---|---|---|---|
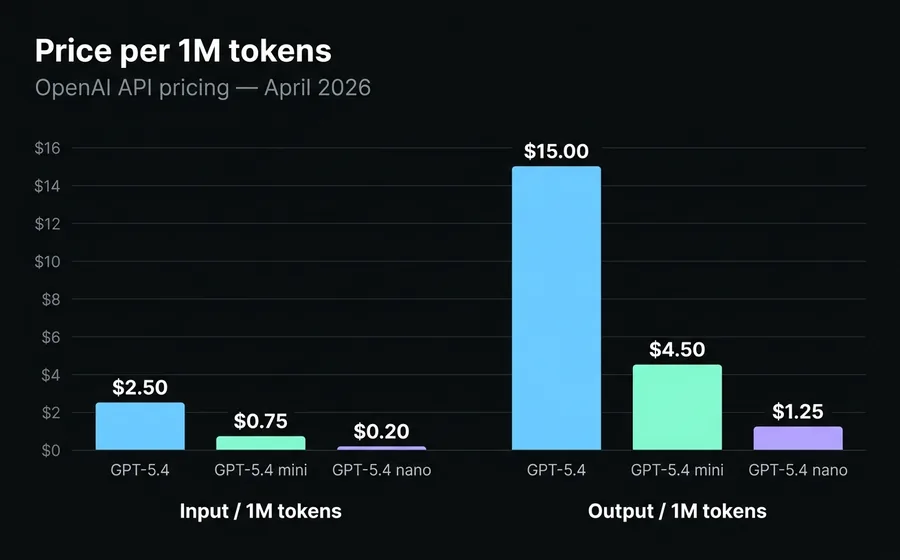
| Input / 1M tokens | $2.50 | $0.75 | $0.20 |
| Output / 1M tokens | $15.00 | $4.50 | $1.25 |
| Cached input / 1M tokens | $0.25 | $0.075 | $0.02 |
| Context window | 1.050.000 | 400.000 | 400.000 |
| Max output tokens | 128.000 | 128.000 | 128.000 |
| Function calling | Yes | Yes | Yes |
| Structured outputs | Yes | Yes | Yes |
| Native computer use | Yes | Yes | No |
| Tool search (optimization) | Yes | Yes | No |
| Input modalities | Text + image | Text + image | Text + image |
| Reasoning effort | none / low / medium / high / xhigh | low / medium / high | low / medium / high |
Two details often overlooked:
The price doubles after 272,000 prompt tokens in the flagship. If you load a long document or an extensive history, the input goes from $2.50 to $5.00 per million tokens. This makes the flagship's "1M context" more of an architectural ceiling than an invitation to send giant prompts.
Cached input is the biggest economic lever. In the mini, a cached token costs $0.075/1M compared to $0.75/1M for normal input. If your agent has a long system prompt that is reused in every conversation (which is typical), caching it lowers the effective cost by 60% to 80%.
The parameter nobody explains: reasoning_effort
GPT-5.4 introduced a parameter that redefines how you pay for intelligence: reasoning_effort. It controls how much the model "thinks" before responding. The values are none, low, medium, high, and xhigh (only flagship supports xhigh).
Each level consumes invisible reasoning tokens that you pay for as output, but which do not appear in the final response. That is: with high, the model can spend 2,000-5,000 internal tokens before writing the first visible word.
Practical heuristic:
-
noneolow: conversational responses, FAQ, greetings, simple classification. The model responds almost instantly. -
medium: the reasonable default. Customer service, lead qualification, triage. There is an analysis step, but it remains responsive. -
high: tasks with multiple steps or ambiguity. Sub-agent orchestration, technical diagnosis, negotiation. -
xhigh: reserved for long agentic workflows where an error costs more than five seconds of latency. Compliance, financial decisions, critical code.
In the AsisteClick catalog, the multi-agent orchestrator uses gpt-5.4-mini with
reasoning_effort=high because it must decide which sub-agent to delegate to. A conversation summarizer uses low because the task is mechanical.
Official Benchmarks: where each variant performs
OpenAI published verified results on industry-standard benchmarks at the time of release.
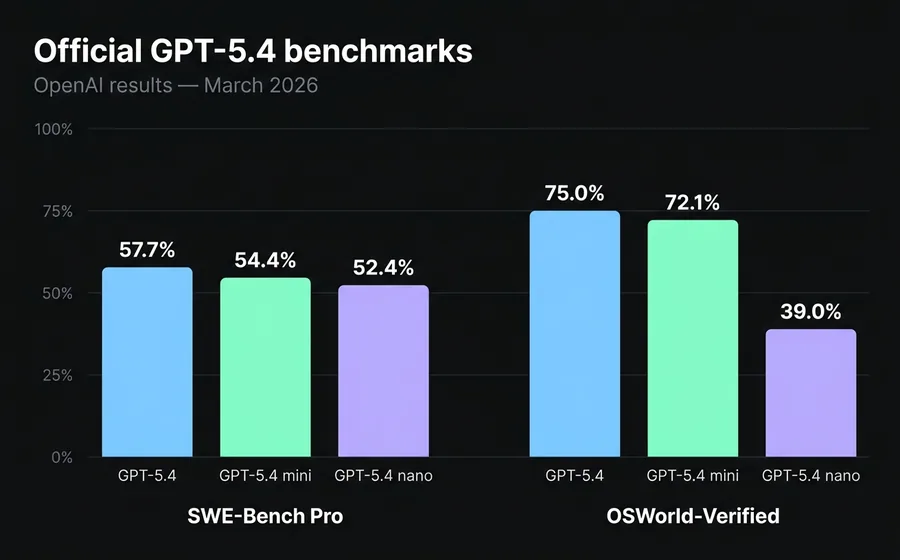
SWE-Bench Pro (real software engineering tasks):
- gpt-5.4: 57.7%
- gpt-5.4-mini: 54.4%
- gpt-5.4-nano: 52.4%
- gpt-5-mini (legacy): 45.7%
OSWorld-Verified (desktop environment navigation, proxy for "computer use"):
- gpt-5.4: 75.0% (exceeds average human performance, 72.4%)
- gpt-5.4-mini: 72.1%
- gpt-5.4-nano: 39.0%
The important takeaway is not "who wins", but where each model's performance profile lies. Between flagship and mini, there are 3.3 points in coding and 2.9 in computer use. Between mini and nano, there are only 2 points in coding, but 33 points in computer use. Nano is not designed for complex agentic tasks: it is a high-volume classifier and extractor that incidentally understands natural language.
If your agent needs to handle GUIs or execute multi-tool steps with state, mini is your baseline. Nano will never close that gap even if you increase its reasoning_effort.
Real Cost: how much it costs to operate each model
Pricing per million tokens sounds cheap until you multiply it by volume. Let's do the math with a concrete case: an AI Agent on WhatsApp that processes 10,000 conversations per month, where each conversation has an average of 6 turns and 200 tokens per turn (half input, half output).
That results in 6 million input tokens + 6 million output tokens monthly.
Estimated monthly cost without caching:
- gpt-5.4: $15 (input) + $90 (output) = $105/month
- gpt-5.4-mini: $4.50 + $27 = $31.50/month
- gpt-5.4-nano: $1.20 + $7.50 = $8.70/month
With cached input (reused system prompt, assuming 80% cache hit):
- gpt-5.4-mini: $0.90 + $27 = $27.90/month
- gpt-5.4-nano: $0.24 + $7.50 = $7.74/month
For an operator with 100,000 conversations/month, the difference between mini and flagship is $1,000 per month. For 1,000,000 conversations, $10,000 per month. The model decision is literally an operating margin decision.
How we solve it at AsisteClick: the 3 agent types and their model
Within AsisteClick's active catalog there are 33 templates of AI Agents and copilots, classified into three categories. The model assigned to each template is not arbitrary: it responds to the relationship between task complexity, tolerable latency, and cost per interaction.
Today the catalog is in gradual migration towards the 5.4 family. New templates already start in gpt-5.4-mini o gpt-5.4-nano. Legacy ones (created before March 2026) still run on gpt-5-mini and are updated as they are individually reviewed, because changing the model can alter the agent's behavior in production.
Autonomous AI Agents (ai-agent) — 18 templates
These are agents that converse directly with the end customer on WhatsApp, webchat, Instagram, or other channels. They answer queries, qualify leads, schedule appointments, manage orders, or collections.
Recommended model: gpt-5.4-mini with reasoning_effort=medium.
Why: conversation with a human on WhatsApp tolerates 1-3 seconds of latency at most before it feels "slow". Mini with medium falls within that range and maintains sufficient reasoning quality for 95% of interactions. The flagship is only justified when the agent needs to perform agentic workflows (call 5+ tools in sequence, reason over long documents).
Catalog examples:
-
AI Collections (
ai-collections):gpt-5.4-mini, medium. Determines tone, finalizes payment plans, escalates complex cases. In detail, the template is aligned with what we discussed in WhatsApp collections chatbot for fintech and connects with integrations such as Loan Collection. -
AI Sales (
ai-sales):gpt-5.4-mini, medium. Qualifies leads and schedules demos. Pattern explained in qualifying WhatsApp leads with AI chatbot. -
Multi-Agent Orchestrator (
ai-orchestrator):gpt-5.4-mini, high. It is the only exception where reasoning is elevated because it must choose between subagents. -
Scheduler with Calendar APIs (
ai-asiste-booking):gpt-5.4-mini, medium, with code interpreter enabled. It is the only template that uses code because it needs to calculate availability against timezones and calendar rules. We detail it on the landing page for appointment scheduling.
Copilots (internal assistants for human agents) — 9 templates
These models do not speak with the client. They assist the human agent: suggest responses, translate messages, summarize conversations, detect sales opportunities, de-escalate tense situations. The complete pattern detail is in AI agent copilots: real-time responses.
Default recommended model: gpt-5.4-mini with
reasoning_effort=low o medium depending on the task.
The interesting exception: the copilot for real-time translation
(copilot-translator) is the only template in the catalog that uses . Conversational translation is deterministic, does not require chain-of-thought reasoning, and the human agent is waiting for the text to send it. Nano responds with half the latency of mini and at a fifth of the cost. A copilot that is triggered 200 times per hour of service must be cheap or nothing justifies it.
gpt-5.4-nanoOther copilots in the catalog: email, summary, KB, suggested response, test, de-escalation, sales opportunity, internal notes.
Subagents (specialized tools) — 6 templates
They are agents that do not converse: they execute a specific action invoked by another agent. They consult billing, integrate with Zapier or n8n, process a MercadoPago checkout, consult the weather.
They are agents that do not converse: they execute a specific action invoked by another agent. They consult billing, integrate with Zapier or n8n, process a MercadoPago checkout, consult the weather.
Recommended model: gpt-5.4-mini with reasoning_effort=low. Brief output, deterministic task, invoked many times per session.
The subagent-weather is the only one with image generation enabled (to return the forecast as a composite image), a detail that shows how each template is surgically configured according to the tool it needs.
Decision matrix: which model for which case
If you are building an AI Agent from scratch and don't know where to start, this table solves 90% of cases.
| Use case | Model | Reasoning | Why |
|---|---|---|---|
| Intent classification | gpt-5.4-nano | low | Deterministic task, high volume |
| Structured data extraction | gpt-5.4-nano | low | Fixed output schema, structured outputs |
| Real-time translation | gpt-5.4-nano | low | Critical latency, no reasoning |
| WhatsApp customer service | gpt-5.4-mini | medium | Conversational with context |
| Lead qualification | gpt-5.4-mini | medium | Decisions on multiple variables |
| Automated collections | gpt-5.4-mini | medium | Tone + negotiation + rules |
| Scheduling with tools | gpt-5.4-mini | medium | Function calling + code interpreter |
| Multi-agent orchestrator | gpt-5.4-mini | high | Routing with context |
| Ticket summary | gpt-5.4-mini | low | Batch, non-conversational |
| Analysis of long documents (>400K tokens) | gpt-5.4 | medium / high | Requires 1M context |
| Compliance / high-risk decisions | gpt-5.4 | xhigh | Maximum reasoning available |
| Agentic workflow with 10+ tools | gpt-5.4 | high / xhigh | Tool search + deep reasoning |
This matrix is not theoretical: it replicates the logic with which the AsisteClick catalog templates are configured today.
When to scale up to the flagship GPT-5.4
Mini is the new default for 80% of cases. Flagship is warranted when one of these conditions is met:
- Context greater than 400,000 tokens. Mini and nano cut off at 400K. If your agent needs to analyze a complete legal file, a month's session log, or a knowledge base without chunking, the flagship with its 1,050,000 token context is the only option. Remember that exceeding 272K doubles the input price.
-
Agentic workflow with more than 10 tools. The
tool_searchof the flagship is optimized to reduce token cost when many tools are simultaneously available. A technical support agent navigating between CRM, ticketing, KB, monitoring, and billing benefits here. - Computer use in complex visual environments. If the agent has to operate an unknown graphical interface (OSWorld-Verified 75% vs 72.1% of mini), the difference justifies the cost.
-
Reasoning
xhigh. Only the flagship supports this level. Legal decisions, financial auditing, production code review: you pay more, but the margin of error is reduced.
In the AsisteClick catalog, no template currently runs on flagship by default. It is reserved as a manual option for IA Plus plan customers with specific cases of document analysis or compliance.
Recommended migration path: start with mini, scale up where it hurts
If you are starting an AI Agent from scratch, the most efficient path is:
Step 1 — Start with gpt-5.4-mini y reasoning_effort=medium. It's the 80/20 of the family. You will cover almost all cases with sufficient quality and controlled cost.
Step 2 — Measure latency and quality by interaction type. Separate conversations by intent and measure two things: average response time and resolution rate without human escalation. If latency is an issue in a specific category (e.g., initial classification), lower that node to
nano with reasoning=low.
Step 3 — Scale up to flagship only where you fail. If a specific case has a low autonomous resolution rate despite reasoning=high in mini, try the flagship with
xhigh. But measure: the difference is usually 2-4 accuracy points at 3-4× the cost.
Step 4 — Implement prompt caching from day one. A cached system prompt saves you up to 80% of the input cost. If your agent has a system prompt of 3,000 tokens and you use it 10,000 times a month, that's 30M tokens that with cache you pay at $0.075/1M instead of $0.75/1M.
This is the same path we follow at AsisteClick when we migrate a client from legacy chatbots to AI agents. We never start with flagship. We scale up only when there is evidence that mini is not sufficient.
If you want to delve deeper into how to design the prompts that accompany this decision, read our guide on prompt engineering for customer service agents. If you are comparing this approach with traditional chatbots, the underlying discussion is in chatbot NLP vs GPT vs hybrid.
Implementation in AsisteClick
The AsisteClick platform gives you access to the complete catalog of templates without you having to choose the
model manually: each template comes pre-configured with the model, reasoning_effort,
tools (web search, code interpreter, image generation) and recommended variables for its use case.
If you're starting from scratch, AsisteGPT it allows you to clone a template from the catalog (collections, sales, support, scheduling, translation, orchestrator) and adjust it to your company in minutes. If you already have a human team operating channels, AsisteCopilot it adds the 9 copilots from the catalog (response suggestion, translation, summary, de-escalation) without touching the agent's flow.
Plans that include the AI agent family start at AI Plus from $260/month (or $208/month with annual billing).
Frequently asked questions
Is GPT-5.4 mini better than GPT-5 mini?
Yes, in all published metrics. GPT-5.4 mini scored 54.4% on SWE-Bench Pro against 45.7% for GPT-5 mini, and runs more than 2× faster with the same pricing. OpenAI recommended in the release to call it "the new default" for production applications. The only reason to stick with GPT-5 mini is if an agent in production is performing well and you don't want to alter its tuning.
What is the latency difference between mini and nano?
OpenAI did not publish exact latencies for the 5.4 family, but the observed behavior is consistent
with the previous generation: nano responds with time to first token (TTFT) close to 900ms and mini in the
range of 1.2-1.8s with reasoning=medium. The difference is noticeable in live chats where
the user expects to see "typing…" without long pauses.
Can I use GPT-5.4 nano for a WhatsApp chatbot?
You can, but it's not the best choice except for very specific tasks like intent classification or data extraction at the beginning of the flow. For the full conversation, mini is better: nano performs 33 points worse than mini in OSWorld-Verified (agentic tasks) and tends to fail when it needs to reason about long conversational context.
Is the flagship's 1 million token context useful in practice?
It is useful for specific cases: file analysis, processing of complete logs, documentary auditing. But the price doubles after 272,000 tokens, so it's not an invitation to send giant prompts by default. Most cases are better resolved with chunking + retrieval (RAG) on mini than by sending all raw context to the flagship.
How do I calculate the real cost of my AI agent?
Take the monthly volume of conversations, multiply by the average tokens per conversation
(typically 1,000-3,000 total between input and output) and apply the pricing of the model you plan to use.
Add 10-30% buffer for invisible reasoning tokens (if you use reasoning_effort
medium or high). If you cache the system prompt, the effective input drops between 60% and 80%.
When is the knowledge cutoff updated?
GPT-5.4 has a cutoff of August 31, 2025. If your agent needs later information (regulatory changes, new products, updated prices), you have two options: enable web search as a tool (all models support it) or connect your own knowledge base via RAG. The second is cheaper, faster, and more controllable.
Does function calling work the same in all three variants?
Yes, all three support function calling and structured outputs with the same fidelity. The difference
appears when there are many tools simultaneously: the flagship has tool_search which optimizes
the choice, mini has most of the optimization, and nano can degrade with more than 10 tools
available.
Choosing the right model is not an isolated technical decision: it defines operational cost, perceived latency, and the capability ceiling of your product. With GPT-5.4, the default answer is no longer "the cheapest that works" or "the flagship just in case". It's mini with reasoning medium, scaling surgically where you measure it fails.
If you want to see the 33 templates from the catalog running on WhatsApp, webchat, and other channels, request a demo of AsisteGPT.