
De buscar a perguntar: a mudança que já está acontecendo
Há um dado que convém ter presente antes de qualquer discussão sobre GEO: a busca tradicional não está morrendo, está perdendo participação. O Google segue processando bilhões de consultas por dia. Mas a fatia da descoberta está se redistribuindo, e a porção que os motores de IA generativa estão levando cresceu de algo marginal em 2023 para um canal estrutural em 2026.
Os dados públicos confirmam isso por vários ângulos. A SimilarWeb registrou em maio de 2025 que o ChatGPT recebeu 4,7 bilhões de visitas mensais globais, com um crescimento interanual de 137%. A Perplexity, mais nicho mas crescendo a 200% interanual, passou de 200 milhões de visitas. O Google adicionou AI Overviews (as respostas geradas que aparecem acima do SERP tradicional) em mais de 60% das consultas informacionais, segundo medições da Authoritas e SE Ranking de março de 2026. E os motores de busca nativos de IA — o OAI-SearchBot da OpenAI, o Claude-SearchBot da Anthropic, o ChatGPT Search lançado no final de 2024 (a diferença entre esses motores cobrimos na comparativa NLP vs GPT vs híbrido) — são agora um canal de tráfego independente que qualquer site com presença LATAM deveria medir separadamente.
A mudança importa porque as duas lógicas são distintas. Em uma busca tradicional, você produz o documento e o usuário decide entrar ou não. A distância entre você e a decisão do usuário é um clique. Em uma consulta a um LLM, você produz o documento, o modelo o processa, e entrega ao usuário uma síntese. A distância entre você e a decisão é uma citação — se ele te mencionou, você ganhou atenção; se não, você não existe. E ao contrário do SEO clássico, onde dois resultados podem coexistir na página um, em uma resposta do ChatGPT só entram três ou quatro nomes. O espaço é brutalmente mais finito.
Isso explica por que as empresas que entenderam cedo a mudança estão investindo em GEO com a mesma seriedade com que investiram em SEO em 2010: não é opcional, é a próxima camada de visibilidade. A diferença é que o campo técnico ainda está se formando. As regras não estão escritas com o detalhe das diretrizes do Google. Há padrões emergentes (o llms.txt proposto por Jeremy Howard em setembro de 2024), sinais que sabemos que importam (estrutura semântica, autoridade temática, freshness) e muitas hipóteses razoáveis que estão sendo validadas com dados.
A pergunta operativa é a mesma de sempre: como você aumenta a probabilidade de que sua marca apareça quando alguém pergunta? A diferença é que a resposta mudou.

Como um LLM te cita: o pipeline técnico
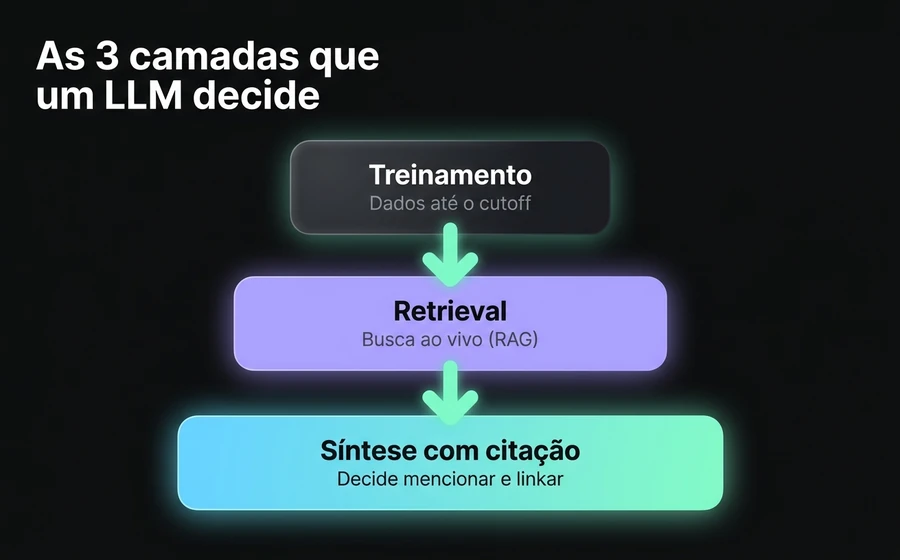
Para entender por que algumas coisas funcionam em GEO e outras não, convém olhar como um modelo de linguagem produz uma resposta quando alguém lhe pergunta sobre sua marca ou seu vertical. Há três camadas que operam em simultâneo, e cada uma tem mecânicas distintas.
Camada 1: dados de treinamento (knowledge cutoff). Cada modelo tem um corpus de treinamento com uma data de corte. GPT-5 foi treinado com dados até o início de 2025. Claude Opus 4 até março de 2025. Gemini 2.5 até início de 2025. Isso significa que o conhecimento "estável" do modelo sobre sua marca depende do que você havia publicado e como sua marca era citada até essa data. Se seu site já existia e tinha autoridade, o modelo já tem representações internas sobre você. Se você acabou de lançar há dois meses, não.
Esta camada é a mais difícil de modificar no curto prazo: você não controla quando o próximo modelo é treinado. O que você sim controla é qual corpus ele encontra quando é treinado: se seu conteúdo é exaustivo, citável, bem estruturado e referenciado por terceiros, vai entrar no training set com um peso maior (cobrimos isso em detalhe em as 3 camadas de conhecimento de um Agente de IA). É SEO clássico levado a outro plano.
Camada 2: retrieval em tempo real (RAG e search grounding). Aqui está a alavanca curta do GEO. A maioria dos motores modernos não responde apenas a partir de seus pesos: faz uma busca ao vivo quando recebe sua pergunta. ChatGPT com busca ativada (através do ChatGPT Search e do bot OAI-SearchBot), Perplexity (que é RAG-first por design), Claude com busca web habilitada (Claude-SearchBot), Google Gemini com search grounding integrado. Todos eles consultam a web enquanto geram a resposta.
Essa busca usa sinais distintos aos do Google. A Perplexity, por exemplo, prioriza fontes que considera "autoritativas" — um mix de domínios estabelecidos, qualidade de conteúdo, e match com a query. O ChatGPT Search, segundo declarações públicas da OpenAI, pondera presença editorial, frequência de atualização e estrutura. O que quase todos compartilham é a preferência por conteúdo que pode ser ingerido limpo: HTML semântico, dados estruturados, headers claros, e arquivos como llms.txt que lhes digam onde encontrar o conteúdo relevante sem ter que crawlear cem páginas.
Camada 3: síntese com ou sem citação. Uma vez que o modelo tem material (do seu treinamento + do retrieval), produz a resposta. E aqui há uma decisão que o modelo toma na hora: ele menciona a fonte ou não?
A Perplexity sempre cita. É parte de seu produto. O ChatGPT Search cita a maior parte das vezes. O Claude cita quando o modelo considera que a informação vem de uma fonte identificável. O Gemini cita seletivamente. E em respostas "off-search" (quando o modelo não precisa buscar porque já sabe), as citações são incomuns ou inexistentes.
A implicância operativa é enorme: seu objetivo não é apenas aparecer na resposta, é aparecer citado com sua URL. Uma menção sem link é alguma coisa. Uma menção com link ao seu site é tráfego, conversão e autoridade acumulada. As práticas GEO modernas otimizam para a segunda.
GEO vs SEO clássico: o que muda
Se você pensa GEO como "SEO com esteroides" vai otimizar para o motor errado. Há diferenças estruturais que mudam a tática.
| Dimensão | SEO clássico | GEO |
|---|---|---|
| Unidade de sucesso | Posição no SERP | Citação em resposta gerada |
| Densidade de competência | Top 10 visível, top 3 com CTR alto | 3-5 marcas mencionadas no máximo |
| Sinal de intent do usuário | Keyword (às vezes ambíguo) | Pergunta natural completa |
| Autoridade | Backlinks, domínio, expertise | Citações cruzadas + estrutura semântica + presença prévia em training set |
| Freshness | Crawl rate + sitemap | Cutoff do modelo + retrieval ao vivo |
| Long-tail | Cauda longa de keywords | Cauda longa de perguntas (muito mais diversa) |
| Métrica direta | Ranking, cliques, impressões (GSC) | Citações (não há equivalente unificado, é preciso medi-lo manualmente ou com ferramentas externas) |
| Volatilidade | Movimentos por algorithm updates | Mudanças por novas versões do modelo + mudança em retrieval logic |
| Caminho de tráfego | SERP → seu site | Pergunta → resposta sintetizada → citação → seu site (mais fricção) |
As duas disciplinas compartilham uma base: conteúdo de qualidade, site rápido, estrutura clara, autoridade temática. A diferença é o que você soma em cima.
Para SEO clássico a alavanca são as keywords, os backlinks, a velocidade e a satisfação do usuário medida por dwell time. Para GEO a alavanca é a citabilidade: quão fácil é para um modelo entender o que você faz, encontrar a informação correta sobre você, e decidir mencioná-lo como resposta a uma pergunta específica. Uma página inicial bonita mas opaca pode rankear bem no Google e ser invisível no ChatGPT. Uma página densa, estruturada, com definições claras e dados pode rankear medíocre no Google e ser citada pela Perplexity toda semana.
Há um detalhe que muitos guias GEO subestimam: o SEO clássico não se substitui. Conservar o tráfego indexado é o piso. GEO se constrói em cima. As duas otimizações se reforçam: o conteúdo que rankeia bem no Google é o que entra no training set dos modelos na próxima iteração. Cancelar SEO para "ir para GEO" é um erro de novato. O correto é fazer SEO bem E adicionar a camada GEO.
O stack técnico GEO 2026
Esta é a parte densa do guia. Cinco camadas técnicas que qualquer site pode implementar em uma semana de trabalho. Vamos usar asisteclick.com como referência porque é o que temos vivo e publicamente inspecionável.
4.1 llms.txt: o padrão Howard
Jeremy Howard (cofundador da Answer.AI, fast.ai) propôs em setembro de 2024 um padrão simples que muitos sites já estão adotando: um arquivo llms.txt na raiz do domínio que dá ao LLM um mapa estruturado do site. Não é uma config de crawler. É conteúdo editorial pensado para ser lido por um modelo.
A estrutura é markdown e tem três blocos:
# Nome do site
> Resumo executivo em uma ou duas frases que explica o que o site faz.
Bloco de contexto opcional: quem, onde, escala, proposta de valor.
## Seção 1
- [Título da página](url): Descrição breve.
- [Outra página](url): Descrição breve.
## Seção 2
...O segredo é que a primeira linha blockquote (>) é o "elevator pitch" que um LLM pode citar literalmente se a pergunta for "o que é X?". O resumo que você escreve ali, dito nas suas palavras, é exatamente o que um modelo vai usar quando um usuário te buscar. Se seu blockquote é genérico, sua citação vai ser genérica.
Nosso llms.txt (publicado em asisteclick.com/llms.txt, 22 KB, acessível publicamente) abre assim:
AsisteClick é uma plataforma SaaS de atendimento ao cliente omnichannel com chatbots IA. Unifica WhatsApp, Facebook, Instagram, Telegram, email e webchat com bots GPT/NLP, CRM nativo e envios em massa.
Uma frase. Categoria (SaaS de atendimento ao cliente). Diferenciador (omnichannel com IA). Stack (canais). Módulos-chave (bots, CRM, massivos). Se um modelo precisa responder "o que é AsisteClick" em trinta palavras, essa é a resposta. Sem essa frase explícita, o modelo improvisa — e a improvisação de um LLM sobre sua marca é exatamente o que você quer evitar.
Depois vêm as seções: produtos, canais, soluções por indústria, integrações, blog. Cada link tem uma descrição de uma linha. Não se replica o conteúdo de cada página: dá-se o contexto suficiente para que o modelo saiba quando recomendá-la. Se alguém pergunta "qual chatbot para imobiliárias você me recomenda?", o modelo vê a linha "WhatsApp para imobiliárias: responde, qualifica e agenda visitas" e conecta o match.
4.2 llms-full.txt: conteúdo completo curado
Se llms.txt é o mapa, llms-full.txt é o conteúdo. É um arquivo mais pesado (no nosso caso 1 MB) que concatena as páginas relevantes do site em markdown plano, sem navegação, sem scripts, sem bloat. É o que você quer que um LLM ingira se decidir aprofundar.
Por que dois arquivos? Porque os modelos têm janelas de contexto. O llms.txt de 22 KB cabe em qualquer janela. O llms-full.txt de 1 MB cabe em GPT-5 (que tem contexto estendido) mas não em modelos menores. Oferecendo os dois, você deixa que o cliente escolha conforme sua capacidade.
A regra operativa para llms-full.txt: inclua as páginas que você quer que um modelo aprenda profundamente — produtos centrais, casos de sucesso com métricas, comparativas, FAQ exaustivas, post pillar do seu blog. Exclua: páginas legais, índices, navegação, conteúdo obsoleto. Markdown plano sem tabelas exóticas. Cada seção com sua URL canônica ao lado para que o modelo possa linkar.
4.3 robots.txt para AI crawlers: a política explícita
O robots.txt sempre foi território de SEO. Em 2026 também é de GEO, mas com uma virada: agora há mais de 20 user-agents novos correspondentes a bots de IA, e cada um cumpre uma função distinta. Você precisa de uma política explícita, não uma omissão.
Os principais bots a considerar:
| Bot | Empresa | Função |
|---|---|---|
GPTBot |
OpenAI | Crawl para training |
ChatGPT-User |
OpenAI | Fetch on-demand quando um usuário menciona sua URL no ChatGPT |
OAI-SearchBot |
OpenAI | Crawl para ChatGPT Search |
ClaudeBot |
Anthropic | Crawl para training |
Claude-Web |
Anthropic | Fetch on-demand |
Claude-User |
Anthropic | Fetch on-demand iniciado por usuário |
Claude-SearchBot |
Anthropic | Crawl para busca |
PerplexityBot |
Perplexity | Crawl + retrieval |
Perplexity-User |
Perplexity | Fetch on-demand |
Google-Extended |
Opt-in separado para training do Gemini (não afeta indexação do Google Search) | |
Bytespider |
ByteDance / TikTok | Crawl para Doubao |
Meta-ExternalAgent |
Meta | Crawl para LLaMA |
Amazonbot |
Amazon | Crawl para Alexa / Q |
Applebot-Extended |
Apple | Opt-in separado para training |
A decisão estratégica: você permite tudo, bloqueia tudo, ou aplica uma política mista? As três são válidas conforme o caso.
- Allow all (a nossa): maximizar a probabilidade de aparecer em qualquer LLM. Faz sentido se seu modelo de negócio se beneficia da visibilidade, você não precisa proteger conteúdo premium e sua publicação pública já é a oferta.
- Block training, allow retrieval: bloquear
GPTBot,ClaudeBot,Google-Extended(todos os que treinam), mas permitirChatGPT-User,Claude-User,OAI-SearchBot,PerplexityBot. Faz sentido se você quer ser citado em tempo real mas não fazer parte do próximo modelo "for free". É a política de muitos veículos grandes (New York Times, Wall Street Journal). - Block all: bloquear todos os bots IA. Faz sentido apenas se seu conteúdo é proprietário, seu modelo é de paywall estrito e você não quer nenhum vazamento.
Nossa política completa em asisteclick.com/robots.txt é ALLOW ALL explícito para os crawlers de IA. Escolhemos porque AsisteClick vende a um mercado LATAM onde a visibilidade em LLMs é a próxima fronteira da descoberta, e bloquear bots seria bloquear participação de mercado em formação.
4.4 Schema.org: o sinal estruturado que os LLMs sim leem
Os dados estruturados com JSON-LD existem há anos para SEO. Mas os LLMs os leem com mais entusiasmo que o Google em alguns casos, porque lhes permitem parsear o conteúdo sem ambiguidade. Três tipos que importam especialmente para GEO:
Articleem posts: inclui autor, data de publicação, data de modificação, descrição, headline. Um LLM que avalia se seu post sobre "WhatsApp Business API" é citável olha odateModifiedpara saber se a informação segue vigente.Organizationna home e no footer: inclui nome, logo, descrição, endereço, contatos, redes sociais, fundadores. É o "cartão de apresentação" para entidades — os LLMs constroem representações de entidades a partir desses dados.FAQPageonde você tenha FAQ visível: cada pergunta-resposta fica parseável. Isso é ouro puro para GEO: quando alguém pergunta a um LLM "como funciona X?", o modelo pode levantar a resposta do seu FAQ quase literal.
Uma decisão técnica importante: usar JSON-LD em <script type="application/ld+json"> e não microdata em HTML. JSON-LD é o que os LLMs leem com facilidade. Microdata está mais em desuso.
4.5 Outros sinais: open graph, sitemap, semântica do HTML
Três sinais menores mas que somam:
- Open Graph completo com
og:title,og:description,og:image,og:type: embora pensado originalmente para social media, os LLMs o usam como descrição concisa quando não encontram algo melhor. - Sitemap XML com
lastmodreal: os crawlers de IA priorizam páginas frescas. Se seu sitemap diz que tudo foi modificado hoje, eles não acreditam. Se diz datas reais, te crawleiam com a frequência correta. - HTML semântico:
<article>,<section>,<header>,<main>,<aside>. Soa básico mas muitos sites usam<div>para tudo. Os LLMs processam melhor estrutura semântica que<div>-soup.
Auditoria de citabilidade: checklist de 10 pontos
Dez critérios acionáveis para auto-avaliar se seu site está GEO-ready. Cada um soma ou subtrai probabilidade de ser citado. Audite um por um com seu domínio em mente.
- Você tem
/llms.txtpublicado e acessível publicamente? Se a resposta é não, este é o primeiro passo. - A primeira frase da sua home responde "o que X faz" em menos de 30 palavras? Se você precisa de 200 palavras, o LLM não vai te citar ali.
- Seu
robots.txttem regras explícitas para AI crawlers? Não regras implícitas. Explícitas. Os bots leem o que está escrito. - Seu blog tem JSON-LD
Articleem cada post? Se não, os modelos têm que inferir autor e data. Inferência = perda de confiança. - Suas FAQ estão marcadas com
FAQPageschema? Se seu FAQ é texto plano sem schema, os LLMs o processam, mas perdem a estrutura pergunta-resposta que é ideal para citá-lo. - Seu conteúdo pillar tem 3000+ palavras com headers H2/H3 lógicos e dados concretos? Os LLMs não citam posts de 500 palavras genéricos. Citam exaustividade.
- Você menciona cifras próprias, casos com nome e métricas verificáveis? "Aumentamos as vendas em X%" sem contexto não é citado. "O cliente Y passou de 1% a 3% de conversão em 6 meses com AsisteClick" sim é citado.
- Seu site carrega sem JS pesado? Alguns modelos fazem retrieval com motores que executam JS, outros não. Se seu conteúdo está atrás de um render JS, o conteúdo invisível ao
curlé invisível ao LLM em muitos casos. - Sua marca está mencionada em sites autoritativos do seu vertical (mídia, partners, agregadores)? As citações cruzadas são a moeda de autoridade para LLMs assim como os backlinks o são para o Google.
- Você tem um protocolo de atualização de conteúdo? Posts com
dateModifiedde dois anos atrás perdem peso. Refrescar os pillar a cada 6-12 meses é parte do trabalho.
Se você marca 8 ou mais, está na primeira fila de marcas GEO-ready do seu vertical em LATAM. Se marca 4-7, há trabalho claro pela frente. Se marca menos de 4, o upside de investir em GEO agora é enorme: qualquer passo soma.

Como medir se funciona
Aqui vamos ser honestos: a mensuração GEO em 2026 ainda está em formação. Não existe um Search Console para LLMs. O que sim existem são três tipos de sinais que, combinados, te dão um panorama útil.
Sinal 1: referrals em GA4. Configure o GA4 para detectar referrals desde chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Quando um usuário clica em uma citação que um LLM colocou em sua resposta, esse tráfego chega ao seu site com esses referrers. É a métrica mais direta de citações com conversão.
No GA4, crie um canal personalizado "AI Referrals" com esses domínios. Se você começa do zero, o volume vai ser baixo (LLMs ainda citam pouco com cliques). Mas a tendência importa mais que o número absoluto. Se passa de 5 sessões/mês a 50/mês em seis meses, você vai por bom caminho. Se se mantém em zero, há um problema de citabilidade.
Sinal 2: Google Search Console para queries naturais. Embora seja contraintuitivo, GSC segue sendo útil para GEO. Por quê? Porque as queries que aparecem ali — "o que é X", "como funciona Y", "diferenças entre A e B" — são exatamente as queries que as pessoas fazem a um LLM. Se seu site aparece para essas queries no Google, há alta probabilidade de que também apareça em LLMs. GSC é seu proxy de "intent conversacional coberto".
Filtre no GSC por queries que começam com "o que", "como", "qual", "por que", "quando". Essas são suas queries conversacionais. O volume e o ranking ali te dizem sua posição competitiva em intent conversacional, que se transfere parcialmente a GEO.
Sinal 3: testes manuais sistemáticos. Uma vez por mês, faça o seguinte protocolo:
- Lista de 10-20 perguntas que um cliente potencial faria a um LLM sobre sua categoria (não sobre sua marca: sobre a categoria).
- Pergunte ao ChatGPT (com busca ativada), Perplexity, Claude, Gemini.
- Registre: te mencionam? Como? Com link ou sem link? Antes, durante ou depois dos concorrentes? A descrição que dão de você é a que você quer?
- Compare mês a mês.
É trabalho manual, mas até que as ferramentas de monitoramento automatizado amadureçam, é o método mais confiável. Existem ferramentas comerciais emergentes — Otterly, BrandRanker, Profound, HubSpot AI Search Grader, AthenaHQ — que automatizam parte disso. Vale a pena avaliá-las se seu vertical é competitivo. A maioria começa com planos gratuitos ou de baixo custo para tracking de poucas marcas/queries.
Sinal 4 (avançado): logs do servidor. Os crawlers de IA deixam seu user-agent em seus logs. Filtre por GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot. A frequência com que te visitam é um indicador antecipado: se visitam pouco, estão te descobrindo pouco. Se visitam muito, há interesse do modelo em seu conteúdo. Isso é um proxy ruidoso mas útil.
Caso AsisteClick: o que fizemos
Nossa implementação GEO começou em março de 2026, no contexto mais amplo de migrar o site asisteclick.com de WordPress para Astro (uma mudança que tem sua própria história, mas que abriu a oportunidade de tratar GEO como parte do design técnico desde o início em vez de bolt-on depois).
O stack atual, todo público e verificável:
asisteclick.com/llms.txt— 22.939 bytes. Resumo executivo + 10 produtos + 7 canais + pricing + 11 verticais + 5 integrações + 32 posts do blog + 7 casos de sucesso. Markdown plano, gerado automaticamente a partir do metadata do site.asisteclick.com/llms-full.txt— 1.003.695 bytes (~1 MB). Conteúdo completo das landings-chave e dos posts pillar do blog, concatenados em markdown sem bloat. Para modelos com janela de contexto grande que queiram aprofundar.asisteclick.com/robots.txt— política ALLOW ALL explícita para mais de 20 user agents de IA. Comentário inline que documenta a decisão e mantém auditável a lógica.- JSON-LD
Article+FAQPage+BreadcrumbListnos mais de 30 posts do blog, gerado em build time a partir do meta de cada post. - JSON-LD
Organizationna home com info estruturada da empresa. - Sitemap XML com
lastmodreal e hreflang multi-idioma (es/en/fr/pt).
Por trás do stack há um skill próprio (/ai-seo) que automatiza a regeneração do llms.txt y llms-full.txt cada vez que se publica um post novo ou se muda uma landing. Isso é importante porque a manutenibilidade é onde GEO costuma falhar: os llms.txt que estão desatualizados três meses depois de publicados são a regra, não a exceção.
Resultados? Aqui vem a parte honesta: temos poucos meses de tracking, então os números são preliminares. Vemos crescimento em referrals desde chat.openai.com y perplexity.ai no GA4 (de zero a um par de sessões por semana), aumento em queries conversacionais no GSC (impressões para "o que é agente de IA", "como escolher chatbot whatsapp", etc.), e melhorias anedóticas em testes manuais: o ChatGPT começou a nos mencionar quando lhe perguntam por "plataformas WhatsApp Business para PMEs em LATAM", coisa que não fazia em janeiro. Não é evidência de scale. É evidência de método. A conclusão sólida vamos poder dar no final de 2026 com mais dois trimestres de data.
O método é replicável independentemente dos nossos números. O investimento em horas: uma semana de um dev para implementar o stack base, mais uma rotina mensal de auditoria (4 horas) e manutenção do llms.txt (1 hora por publicação nova).
Antipatterns: o que não funciona em GEO
O outro lado do checklist: erros que se cometem com frequência e que ativamente reduzem sua probabilidade de ser citado.
1. Keyword stuffing adaptado. Alguns sites estão montando llms.txt com listas de keywords e variantes ("chatbot WhatsApp, chat bot whatsapp, chatbot wapp, bot WhatsApp..."). Os LLMs detectam o padrão e desvalorizam. O padrão Howard é markdown com descrições naturais, não listas de keywords. Se seu llms.txt parece um dump de Ahrefs, você está fazendo errado.
2. Conteúdo IA-sobre-IA sem ângulo. O tema GEO vai explodir este ano. Você vai ver uma avalanche de posts genéricos sobre "como aparecer no ChatGPT" escritos por IA sem verificação, repetindo os mesmos quatro conselhos. Esses posts não são citáveis porque não trazem informação nova. Se vai escrever sobre GEO, faça com ângulo próprio (caso, dado, vertical específico).
3. Paywall em conteúdo pillar. Se seu melhor conteúdo está atrás de um login ou um paywall, os crawlers de IA não o leem. Há um debate legítimo sobre quanto liberar de graça, mas estrategicamente, o pillar content que você quer que o ChatGPT te cite precisa ser público.
4. JavaScript-heavy rendering. Se seu site renderiza o conteúdo principal com JS e um crawler básico não o vê, depende do bot se o processa. GPTBot y ClaudeBot não executam JS em todos os casos. Server-side rendering ou static generation é mais seguro.
5. Hidden content para LLMs ("cloaking"). Alguns estão testando servir conteúdo distinto a humanos vs LLMs (texto extra invisível para humanos mas parseável por crawlers). Isso é a versão 2026 do black-hat SEO e vai terminar penalizado igual que o cloaking dos 2010s. Não faça isso.
6. Listicles genéricos sem substância. "10 melhores plataformas de X", "7 ferramentas para Y" sem critérios claros e sem diferenciadores. Os LLMs as leem mas não as citam: há infinitas listas como essas. O que se cita é análise com critérios e dados.
7. Informação desatualizada sem marca de data. Posts de 2022 sem dateModified atualizado, falando de preços e features que mudaram. Os modelos modernos checam dateModified. Se não há, assumem worst case.
8. Tom robótico gerado. Curiosamente, conteúdo gerado com IA sem edição humana tem menos chances de ser citado por IA. Os modelos detectam o padrão e desvalorizam. O paradoxo é real: para que a IA te cite, você tem que soar humano.
Cinco passos acionáveis esta semana
Se você quer começar sem esperar, esta é a ordem mínima viável:
Dia 1 — Publique seu /llms.txt. Uma hora de trabalho. Pegue sua home, decomponha-a em blocos (produtos, serviços, recursos), escreva uma linha de blockquote que diga o que sua empresa faz, liste as URLs principais com descrição de uma linha. Suba à raiz do domínio. Se você tem WordPress, pode gerá-lo com um plugin (LlmsTxt, AI SEO ou similar) ou subi-lo manualmente.
Dia 2 — Atualize seu robots.txt. Trinta minutos. Decida sua política (ALLOW ALL, block training, mista) e escreva as regras explícitas para os mais de 15 user-agents listados acima. Teste com curl https://tudominio.com/robots.txt para confirmar que se serve.
Dia 3 — Audite seu Schema.org. Uma hora. Use o Schema Validator do Google para ver que JSON-LD você tem na sua home, em um post do blog e em uma landing de produto. Se faltar Organization, Article o FAQPage, adicione. Se seu site é WordPress, há plugins (RankMath, Yoast, SchemaPro) que automatizam.
Dia 4 — Configure GA4 para AI Referrals. Trinta minutos. No GA4, crie uma view "AI Referrals" com domínios de origem chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Comece a trackear desde hoje para ter baseline.
Dia 5 — Teste manual sistemático. Uma hora. Escreva 10 perguntas que um cliente potencial faria a um LLM sobre sua categoria. Pergunte no ChatGPT, Perplexity, Claude. Registre quem te menciona, como, em que ordem. Salve os screenshots. Repita em 30 dias para medir progresso.
Com esses cinco passos em uma semana, você está no primeiro quartil de marcas que estão fazendo GEO com seriedade em LATAM em 2026. O que segue (manter o llms.txt, refrescar o conteúdo pillar, monitorar referrals, iterar o stack) é operativa contínua. Mas a base se constrói em cinco dias.
Se sua equipe é de marketing mas não de tech, e você precisa de um partner que se encarregue do stack técnico e da operativa de conteúdo conversacional otimizado para LLMs (não apenas SEO), na AsisteClick oferecemos implementação chave-na-mão dessa camada GEO para clientes existentes e novos. A diferença com um freelance SEO genérico: nossa equipe construiu o stack para nosso próprio site e o mantém como produção.
Perguntas frequentes
O que é Generative Engine Optimization (GEO)?
GEO é o conjunto de práticas técnicas e editoriais que aumentam a probabilidade de que sua marca, produto ou conteúdo seja mencionado por motores de busca generativa como ChatGPT, Perplexity, Claude ou Gemini quando um usuário faz uma consulta relacionada. Não substitui o SEO clássico: o complementa, otimizando para uma unidade de sucesso distinta (citação em resposta sintetizada em vez de posição no SERP).
GEO é a mesma coisa que AEO (Answer Engine Optimization)?
São termos próximos com matizes. AEO surgiu antes e se referia mais a aparecer em "answer boxes" e featured snippets do Google. GEO é mais amplo: inclui os motores generativos (LLMs) que produzem respostas sintetizadas com ou sem busca em tempo real. Na prática, muito conteúdo se sobrepõe. AIO ("AI Optimization") é um terceiro termo em uso. Para fins práticos, GEO é o mais usado em 2026 e cobre todo o espectro.
Quanto tempo leva para ver resultado de GEO?
Os efeitos de retrieval (citação em respostas que o modelo busca ao vivo, como Perplexity ou ChatGPT Search) se veem em semanas: se você publica llms.txt, atualiza robots.txt e melhora a estrutura, os crawlers de IA descobrem a mudança em 1-4 semanas. Os efeitos de training (que sua marca fique melhor representada no próximo modelo) se veem em meses, porque dependem de quando se treina a próxima versão do LLM. Prazo razoável para medir GEO com seriedade: 6 meses mínimo.
Preciso desindexar do Google se publicar llms.txt?
Não. llms.txt não afeta sua indexação no Google. São sistemas independentes. O Google ignora llms.txt (não é um padrão que use), e os crawlers de IA leem llms.txt além de seu site normal. Fazer GEO não implica sacrificar SEO; ao contrário, são sinérgicos.
Como sei se ChatGPT ou Perplexity já estão citando minha marca?
Três métodos: (1) teste manual — faça perguntas sobre sua categoria em cada motor e registre se te mencionam; (2) referrals em GA4 desde domínios como chat.openai.com y perplexity.ai; (3) ferramentas de monitoramento comercial (Otterly, BrandRanker, Profound) que rastreiam automaticamente menções de marca em LLMs. O teste manual é grátis e suficiente para começar. As ferramentas são úteis quando seu vertical é competitivo e você precisa de acompanhamento contínuo.
Bloquear bots de training me beneficia ou me prejudica?
Depende do seu modelo de negócio. Se seu conteúdo é proprietário e monetizado (mídia, paywall, base de dados), bloquear training pode fazer sentido para não "presentear" o corpus ao próximo modelo. Se seu conteúdo é marketing e você quer máxima visibilidade, convém permitir tudo. Uma política mista comum: permitir retrieval bots (que te podem citar em tempo real com link) e bloquear training bots (que ingerem seu conteúdo para treinar o próximo modelo). Cada empresa decide conforme prioridades.
Existe uma plataforma que combine atendimento ao cliente com presença em LLMs?
Hoje são camadas separadas: GEO se gerencia desde seu site (llms.txt, schema, conteúdo), e atendimento ao cliente com IA se gerencia desde uma plataforma como AsisteClick que integra WhatsApp, web, Instagram e CRM com agentes de IA próprios. O que sim você compartilha entre ambos é a base de conhecimento: o conteúdo que o ChatGPT cita para responder por você em geral, e o conteúdo que seu próprio agente de IA usa para responder a clientes no WhatsApp, idealmente vêm do mesmo corpus curado. Construir essa base uma única vez e usá-la em ambos os canais é a próxima fronteira de eficiência para equipes de marketing e customer experience.