In February 2024, Klarna's CEO proudly announced that its AI Agent — built with OpenAI — had done the work of 700 human agents in its first month. It processed 2.3 million conversations, cut resolution time from 11 minutes to under 2, and was on track to save the Swedish fintech 40 million dollars in 2024. The tech press was euphoric. The CEO publicly declared that "AI can already do all the jobs we humans do." 18 months later, Klarna is hiring humans back.
Not out of moral regret. Because of a measurable quality problem the initial dashboard didn't show.
This post is not an opinion column. It's the operational analysis of what happened inside Klarna, what patterns of the same mistake we see repeated in LATAM operations, and what concrete architecture works in practice to avoid the same fate. The reason this deserves its own post — not just a paragraph — is that the Klarna case is the first public, documented example of a company that bet "everything on AI" in customer service, measured the results honestly, and reversed course. The entire industry is watching how this story ends to decide its own next move.
Act 1: the promise of February 2024
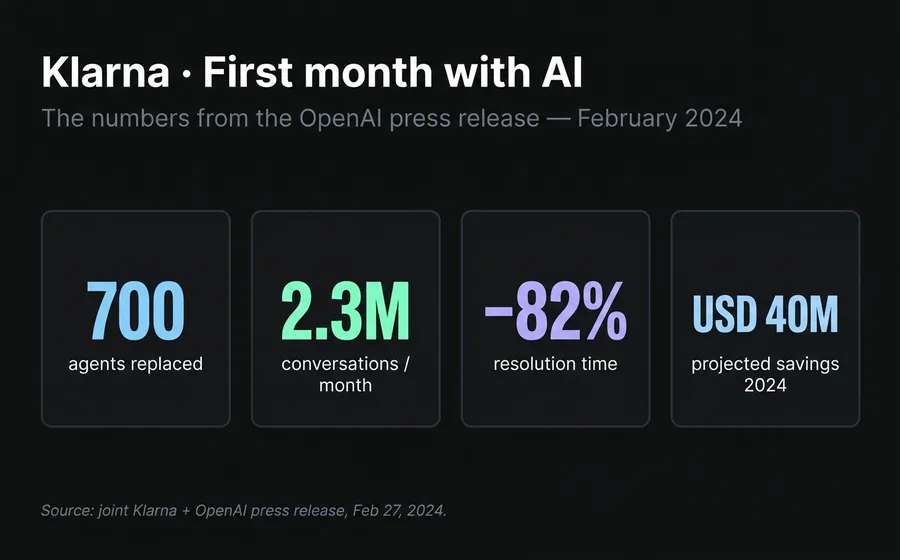
On February 27, 2024, Klarna and OpenAI published a joint announcement. The numbers from the AI Agent's first month in production were hard to ignore:
- 2.3 million conversations processed in 30 days
- Two-thirds of all customer service inquiries
- Average resolution time: under 2 minutes, compared to 11 minutes before
- 25% fewer repeat inquiries, indicating answers resolved on first contact
- 23 markets, 35+ languages from day one
- Projected impact: USD 40 million in profit improvement for 2024
Brad Lightcap, OpenAI's COO at the time, sealed it with a quote: "Klarna is at the very forefront among our partners in AI adoption and practical application." Sebastian Siemiatkowski, Klarna's CEO, went even further in interviews: "AI can already do all the jobs we humans do."
It's important to understand why the promise was credible at that moment. The initial numbers were real. The bot was working. Average satisfaction was comparable to that of human agents. Klarna wasn't lying — it was presenting the data it had with the most optimistic interpretation possible.
The mistake wasn't in the presentation. It was in which data point was chosen to look at.
Act 2: the silent degradation
What Klarna's dashboard showed was the average. What it hid was the distribution.
When a financial services company handles 2.3 million conversations per month, most of those inquiries are routine: "how much do I owe?", "when's the next payment?", "how do I change my card?". For those questions, a well-built AI Agent answers better than a human. It's faster, more consistent, never tires, never makes mistakes from distraction. Klarna wasn't wrong on that diagnosis.
The problem began appearing in what was statistically invisible — the 5-10% of complex cases. Disputed refunds. Incorrect charges. Hardship payment plans. Fraud cases. Situations where the customer arrives frustrated, with little emotional bandwidth, and a poorly answered detail can escalate into a regulatory complaint.
Three patterns were documented in the following months:
Hallucinations on fees and refunds policies. Klarna's AI Agent would respond confidently about terms that hadn't been correctly loaded, or that had changed between versions. In an e-commerce company, an incorrect answer about a coupon is an inconvenience. In a fintech, an incorrect answer about a charge or due date is a compliance problem.
CSAT drop on complex cases. The average remained stable because routine cases were so many that they hid the deterioration. But when segmented by complexity, cases that escalated to a human after passing through the bot showed significantly worse satisfaction levels than those going directly to a human. The reason: the customer repeated all the information, felt the bot had wasted their time, and arrived at the human already angry.
Customer Effort Score increase. The metric that measures how much effort it takes the customer to resolve their problem started rising month over month. At first it was attributed to the change. When the curve didn't flatten, it became clear it was a structural pattern, not transitional.
The Better Business Bureau accumulated more than 900 formal complaints against Klarna in three years, the majority on refunds and billing — exactly the quadrant where a confident but incorrect answer does more damage than silence.
By mid-2025, Klarna's internal team began hiring human agents again. Without public announcement. Without visible reversal. Just a silent course correction.
Act 3: the reversal
The silence ended in May 2025. Siemiatkowski spoke with Bloomberg and said, in a phrase that became the inflection point of an entire industry era: "We went too far."
The CEO's exact words in that interview and the ones that followed draw a map of the mistake:
"We focused too much on cost. The result was lower quality."
"From a brand perspective, from a company perspective, I just think it's so critical that you are clear to your customer that there will always be a human if you want."
The new model Klarna announced is not a return to the traditional call center. It's hybrid. The company described the format as "Uber-style": remote human agents with flexible hours, mostly students and parents with partial availability, equipped with AI tools that assist them in every conversation. AI keeps handling the bulk of routine volume. Humans take on the complex, the emotional, and what requires judgment.
It's important to note the difference with the "AI doesn't work" narrative. Klarna didn't say that. Klarna said "AI works, but not for everything, and the cost of finding out where it doesn't work turned out higher than what we saved." That distinction is what defines which companies will survive the cycle and which ones will be making the same announcement in 2027.
Why it happened: the 3 structural mistakes
The Klarna case is not a technical failure. The technology worked. What failed was the evaluation logic. Three mistakes recur when analyzing what happened.
Mistake 1: confusing deflection with resolution
Deflection rate measures what percentage of inquiries don't reach a human. Resolution rate measures what percentage of customer problems actually get resolved. They are not the same thing.
An AI Agent can have 85% deflection and 60% resolution. That means out of 100 inquiries, 85 didn't escalate to a human — but only 60 were resolved. The other 25 closed without resolution: the customer gave up, used an alternative channel, or simply abandoned.
Klarna's dashboard showed deflection. The customer's reality was resolution. When the two numbers diverge, the first deceives the second.
Mistake 2: ignoring Polanyi's paradox
30 days ago we published an analysis on the paradox of automation, inspired by philosopher Michael Polanyi's idea: "we know more than we can say." There is human knowledge that can't be articulated in rules — reading customer frustration before it's stated, sensing when the right answer is the wrong answer, adjusting tone in real time.
Generative AI captured part of that tacit knowledge by learning from millions of conversations. But it captured the surface layer — response patterns. The deeper layer — contextual judgment — remains human. Klarna automated the surface layer believing it had automated everything. The difference showed up in edge cases, which are precisely the ones that matter most in a fintech.
Mistake 3: underestimating the cost of confident but wrong answers in compliance
There are industries where an incorrect answer has low cost. If a delivery service AI Agent answers wrong about hours of operation, the customer gets annoyed and the case closes. There are other industries where the same incorrect answer can generate a regulatory fine, a formal complaint, or a legal case.
Fintech collections, insurance, healthcare, consumer credit: all are quadrants where the speed and confidence with which the bot answers wrong are proportionally harmful. In LATAM this is amplified by Consumer Protection regulation — a poorly worded message can be used as evidence in a claim.
Klarna sits exactly in that quadrant. Buy now, pay later. Charges. Due dates. Disputes. The company chose the highest-risk vertical to run the most radical experiment.
What we're seeing in LATAM
As operators of a customer service platform with hundreds of active accounts in Latin America, we see the Klarna pattern repeat in miniature every month. It's consistent enough to describe it as an anti-pattern.
The typical sequence is this. A company decides to automate support. In the first quarter, deflection rate rises from 60% to 85%. The team celebrates. In the second quarter, someone notices CSAT dropped 1.5 points but is within statistical variance. In the third quarter, social media complaints rise. In the fourth quarter, the operations team reports that the re-contact rate — customers returning with the same problem — went up 18 points. By then, brand deterioration cost has already exceeded what was saved on headcount.
What happened at Klarna at global scale, at a LATAM company of 100 thousand customers happens at local scale. The shape of the curve is the same.
There are three regional particularities worth flagging:
Higher expectation of "human when I need one." In LATAM, customer service culture has lower friction with escalation to a human. The Argentine or Mexican customer who sees the "talk to a person" button uses it faster than the European one. This has operational implication: if your AI Agent hides the handoff, you penalize it harder than in other markets.
Compliance verticals more exposed. Argentina and Brazil have active consumer protection regulation. A WhatsApp conversation with an incorrect answer about a charge or a collection can be presented as formal evidence. The quality bar in response is not "satisfy the customer." It's "don't expose the company to a fine."
Accelerated adoption of WhatsApp as primary channel. 80% of first commercial interactions in LATAM happen through messaging. Klarna's mistake on web chat is amplified on WhatsApp because the conversation stays on the customer's phone as evidence — capturable, shareable, and reproducible on social media if it goes wrong.
The 3 operational lessons
If Klarna left us anything, it's three actionable rules. We apply them in production and recommend them to any company evaluating full AI replacement today.
Lesson 1: handoff is the metric that defines whether your AI Agent works
Not deflection. Not speed. The handoff.
A good hybrid system is recognized because: (a) when the bot escalates to a human, it does so with the entire conversation transferred — the customer doesn't repeat information; (b) the SLA after handoff is realistic, not "shortly"; (c) the human agent sees the context, the bot's suggestions, and decides in seconds.
If your current platform doesn't let you measure handoff timing, handoff completion rate, and resolution rate after handoff, you're measuring Klarna's dashboard from February 2024.
Lesson 2: hybrid > pure AI, in any vertical with compliance or emotion
This is not a philosophical choice. It's a risk choice. Pure AI is efficient when the cost of error is low. As soon as the cost of error rises — regulatory fines, brand damage, customer abandonment — the hybrid model dominates.
In the architecture we recommend, an NLP module handles predictable flows (balance inquiry, scheduling, FAQs). A GPT module with proprietary knowledge base handles open inquiries that require contextual understanding. A Copilot assists the human agent when the conversation escalates. And a unified inbox with routing guarantees handoff is instant and with preserved context.
Lesson 3: compliance verticals require specific guardrails, not more training
When an incorrect answer can generate a fine, the problem isn't solved with "more training data." It's solved with guardrails: pre-approved responses for charges, fees, refunds, and disputes; automatic escalation to a human when keywords of legal complaint appear; total conversation logging with timestamping for audit.
The three-layer knowledge architecture — hidden prompt, knowledge base, specific interactions — is precisely the framework that lets you define those guardrails without the bot losing fluency in the non-sensitive parts.
What a well-built hybrid system looks like
For the lesson to be actionable, it helps to ground the architecture. A well-built hybrid system has three components and a protocol.
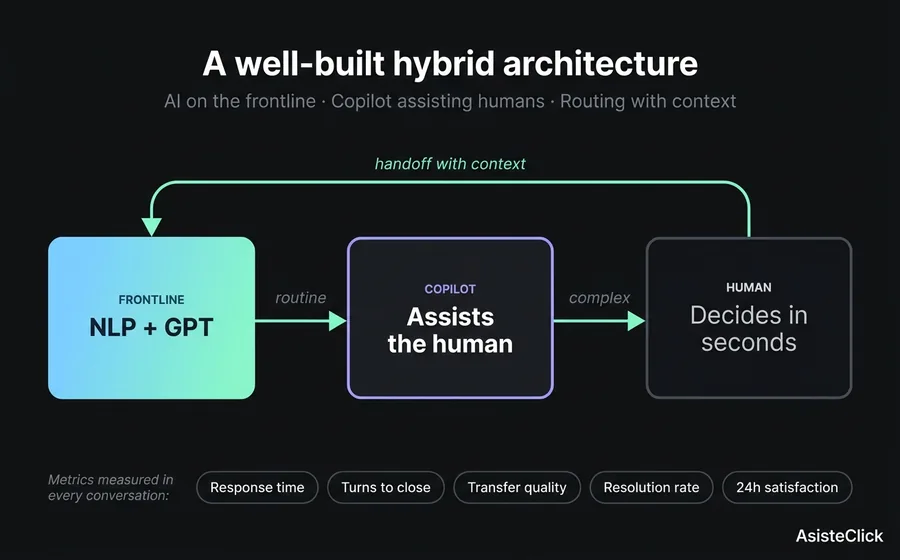
Component 1: the automated frontline. The bulk of volume comes here. Routine inquiries, FAQs, known transactional processes. An NLP module covers the predictable with precision and speed. A GPT module with proprietary knowledge base covers what's open but bounded to the business domain. The important thing: this level never handles what carries compliance risk without explicit escalation.
Component 2: the human agent's Copilot. When the conversation escalates, the human receiving it doesn't enter blind. They see the full transcript, an automatic context summary, response suggestions based on similar prior cases, and customer data loaded from the CRM. The hybrid human's speed approaches the bot's, but with judgment built in.
Component 3: the unified inbox with routing. The customer doesn't know — and doesn't care — whether the answer came from the bot, the Copilot, or a pure human. To them it's a continuous conversation. Behind the scenes, the system routes each turn to the right resource: bot for known questions, human for sensitive cases, Copilot for assisted human.
The protocol: end-to-end measurement. Every conversation is measured at five points. (1) time to first response, (2) number of turns until resolution or handoff, (3) if there was handoff, transfer quality (did the customer repeat info?), (4) resolution rate at close, (5) satisfaction at 24 hours post-close. If any one of these five degrades and the others stay flat, you already know where the problem is.
This is not a conceptual architecture. It's what's running today in LATAM accounts with monthly volumes ranging from 5 thousand to 500 thousand conversations.
Does this mean AI doesn't work?
No. And it's worth saying clearly because tech coverage is swinging from the 2024 enthusiasm to the symmetrical 2026 pessimism, and both extremes are wrong.
Generative AI in customer service works. It resolves volumes that were previously unthinkable. It cuts response times from minutes to seconds. It allows offering 24/7 attention without prohibitive operational cost. It captures tacit knowledge and distributes it across the team.
What doesn't work is the full replacement model. And not because AI is bad, but because customer service isn't just information processing — it's also management of trust, emotion, and risk. When a company tries to automate that second level without keeping humans, what's saved in operational costs is lost in brand value and regulatory exposure.
Klarna didn't fail by using AI. It failed by using it instead of humans rather than alongside humans. The difference between the two prepositions — "instead of" vs "alongside" — is the difference between the February 2024 announcement and the May 2025 Bloomberg interview.
The companies that will lead the coming years are the ones that learned from someone else's experiment before having to pay for their own.
Frequently asked questions
Does this mean Klarna is abandoning AI?
No. Klarna keeps its AI Agent in production handling the bulk of routine volume. What changed is that they hired humans back for cases where AI showed limits — disputes, complex refunds, financial hardship situations. The new model is hybrid: AI does what it does best, the human steps in where the cost of error rises.
Would the same thing happen to a LATAM company?
Yes, and we actually see it happen every month at smaller scale. When a LATAM company decides to replace human service with a pure AI Agent, the pattern is the same: deflection rises, average CSAT holds, but re-contact rate and complex case satisfaction silently deteriorate. The difference is that in LATAM the cycle is faster because of the more human-centric service culture and more active consumer protection regulation.
How much human is "enough" in a hybrid model?
It depends on the vertical, but the operational rule is that between 15% and 30% of conversations should escalate to a human in any business with a compliance, financial, or emotional component. If your deflection rate exceeds 85% in collections, insurance support, or healthcare support, there's a high probability you're hiding failed handoffs rather than avoiding them.
What metric replaces deflection rate as a success indicator?
Resolution rate weighted by 24-hour satisfaction. That is, what percentage of conversations closed the customer's problem AND at 24 hours the customer reports positive satisfaction. That metric is harder to measure but reflects the real value of service. Deflection is an operational metric that only works if it's correlated with resolution — and in many cases, it isn't.
Does this change with GPT-5 or open source models like Llama 4?
More capable models resolve more cases correctly, but they don't solve the structural lesson. Even if GPT-5 reduced hallucination rate to 1%, the customer who falls in that 1% still has the worst experience of your brand. The operational question is not "how good is AI on average," but "what happens with the customer when AI fails." That question is architectural, not model-related.
How to avoid Klarna's mistake from the start?
Three actionable rules. First, measure resolution rate and handoff quality from day one, not just deflection. Second, segment CSAT by case complexity — the aggregate average hides problems until they're already visible outside. Third, keep humans in the circuit from the start in any case with a regulatory or emotional component. Full replacement works in routine cases. Hybrid works for everything else.
Conclusion
The Klarna case will be studied in business schools for years. Not because of the decision to implement AI — that was correct and remains correct — but because of the decision to replace humans believing that the dashboard average was equivalent to the customer experience. The average is rarely the reality of an individual customer, and in customer service the individual customer is the unit of business.
The good news is that the mistake is documented. The CEO admitted the exact words. The degradation curve was measured. The course correction is public. Companies coming next can learn without paying the entry ticket.
If your company is evaluating full AI replacement today, the most strategic decision you can make this quarter is to read the Klarna case in detail, segment your metrics by complexity, and adjust your architecture before executing. The difference between leading the change and repeating the experiment is exactly the time you take to do that analysis.
Keep reading
- The paradox of automation: why more AI demands more humanity — the philosophical framework that predicted this reversal
- The 3 knowledge layers of an AI Agent — how to define guardrails without losing fluency
- WhatsApp collections chatbot in fintech — the highest-risk quadrant in LATAM
- Copilot for agents: how AI suggests responses without replacing the human — the model Klarna is implementing now
- Recovering abandoned carts via WhatsApp with AI — the hybrid architecture applied to a concrete operational case in eCommerce