
Votre entreprise a besoin d'un chatbot. Vous l'avez déjà décidé. La question qui vous freine maintenant est autre : quel type de chatbot ? Car tous les chatbots ne sont pas identiques, et un mauvais choix vous coûte des mois d'implémentation, la frustration de l'équipe et —le pire— des clients qui partent sans réponse.
En 2026, les options réelles se réduisent à trois approches : NLP traditionnel (le bot entraîné avec des questions et réponses), GPT / IA générative (celui qui comprend et génère du langage naturel avec un grand modèle), et l' hybride (qui combine les deux). Chacun présente des compromis concrets en termes de contrôle, de flexibilité, de coût et de vitesse d'implémentation.
Ce guide compare les trois sans détour, avec des critères de production réels —pas des démos de laboratoire— afin que vous puissiez décider lequel correspond à votre opération.
Tableau comparatif rapide
| Critère | NLP traditionnel | GPT / IA générative | Hybride |
|---|---|---|---|
| Précision des réponses connues | Excellent (déterministe) | Bonne (dépend du contexte) | Excellent |
| Gestion des questions inattendues | Mauvais (ne comprend pas ce qui n'a pas été entraîné) | Excellent (génère des réponses naturelles) | Excellent |
| Risque d'« hallucinations » | Zéro | Élevé sans garde-fous | Faible (contrôlé) |
| Coût par conversation | Faible | Moyen-élevé (tokens LLM) | Moyen |
| Temps de mise en œuvre | Moyen (2-6 semaines) | Rapide (jours avec RAG) | Moyen (3-6 semaines) |
| Maintenance | Élevé (réentraîner continuellement) | Faible (mettre à jour la base de connaissances) | Moyen |
| Contrôle sur les réponses | Total | Limité | Élevé (là où c'est important) |
| Évolutivité vers de nouveaux sujets | Lente (entraîner par sujet) | Rapide (ajouter des documents au RAG) | Rapide |
| Idéal pour | Flux prévisibles, conformité | Conversation ouverte, support L1 | Production réelle, multi-cas |
Qu'est-ce qu'un chatbot NLP traditionnel
Un chatbot NLP (Natural Language Processing) fonctionne avec un modèle de classification d'intentions. Vous l'entraînez avec des paires de questions et réponses : "quel est l'horaire d'ouverture ?" → catégorie horario → réponse prédéfinie. Lorsqu'un utilisateur écrit quelque chose, le bot classe l'intention et renvoie la réponse associée.
Comment cela fonctionne en interne
- Entraînement : vous lui donnez 10-50 variations de la même question par intention ("horaire d'ouverture", "à quelle heure ouvrent-ils", "sont-ils ouverts le dimanche"). Le modèle apprend à classer le texte dans ces intentions.
- Correspondance: lorsqu'un nouveau message arrive, le bot calcule la similarité avec les intentions entraînées et choisit celle ayant la plus grande confiance.
- Réponse: si la confiance dépasse un seuil (généralement 70-85%), il renvoie la réponse prédéfinie. Sinon, il tombe sur le fallback ("je n'ai pas compris, pouvez-vous reformuler ?").
Avantages concrets
- Déterministe. La même question donne toujours la même réponse. Cela est important en cas de réglementations, de compliance ou d'informations sensibles (prix, conditions légales, disponibilité des stocks).
- Auditable. Vous pouvez voir exactement quelle intention a été activée, avec quelle confiance, et quelle réponse a été donnée. Debugging clair.
- Coût prévisible. Vous ne payez ni pour les tokens ni pour les appels à une API externe. Le coût est fixe : hébergement + maintenance du modèle.
- Fonctionne hors ligne ou en edge. Ne dépend pas d'une API tierce pour chaque réponse.
Limitations réelles
- Rigide. Si un utilisateur formule la question d'une manière que vous n'avez pas entraînée, le bot ne comprend pas. Et il existe une infinité de façons de poser la même question.
- Maintenance élevée. Chaque fois qu'un nouveau sujet apparaît (un produit, une promotion, un changement de politique), il faut créer de nouvelles intentions, écrire des variations, réentraîner et tester.
- Évolutivité lente. Passer de 20 intentions à 200 nécessite des semaines de travail d'un bot builder dédié.
- Conversation plate. Ne "comprend" pas le contexte précédent. Chaque message est classifié indépendamment. Si l'utilisateur dit "et le prix ?" après avoir demandé un produit, le bot ne sait pas à quel produit il se réfère.
Quand choisir le NLP pur
- Vous avez moins de 30 intentions bien définies.
- Les réponses ne peuvent pas varier (compliance, réglementaire, prix fixes).
- Vous ne voulez pas dépendre d'APIs externes (GPT d'OpenAI, Google, etc.).
- Votre équipe dispose d'un bot builder dédié qui peut maintenir la formation.
Qu'est-ce qu'un chatbot GPT / IA générative
Un chatbot GPT (ou basé sur un LLM — Large Language Model) ne classe pas les intentions : comprend le langage naturel et génère des réponses originales pour chaque message. Derrière, il y a un modèle comme GPT-4, GPT-4o, Claude, Gemini ou un modèle open-source.
Comment cela fonctionne en interne
- Prompt système : vous donnez des instructions au modèle ("vous êtes un assistant de service client de [entreprise]. Votre ton est professionnel. N'inventez pas d'informations qui ne figurent pas dans la base de connaissances").
- Base de connaissances (RAG) : vous joignez des documents avec les informations réelles de votre entreprise — FAQs, manuels, prix, politiques. Le modèle recherche dans ces documents avant de répondre (Retrieval-Augmented Generation).
- Génération : étant donné le message de l'utilisateur + le contexte du RAG + le prompt système, le modèle génère une réponse en langage naturel, sans être limité à des réponses prédéfinies.
Avantages concrets
- Flexible. Il comprend les reformulations, les fautes d'orthographe, le mélange de langues, les questions complexes à plusieurs parties. Vous n'avez pas besoin d'entraîner de variations.
- Conversationnel. Il maintient le contexte au sein de la conversation. Si l'utilisateur pose une question sur un produit et demande ensuite "combien ça coûte ?", le modèle sait à quoi il fait référence.
- Évolutivité rapide. Le catalogue de produits a-t-il changé ? Vous mettez à jour le document dans le RAG. Il n'y a rien à réentraîner.
- Implémentation rapide. Avec une bonne base de connaissances et un prompt affiné, vous pouvez avoir un bot fonctionnel en quelques jours, pas en semaines.
Limitations réelles
- Hallucinations. Le modèle peut inventer des informations qui semblent correctes mais sont fausses. Sans garde-fous, il peut dire au client qu'un produit est disponible alors qu'il ne l'est pas, ou donner un prix incorrect.
- Coût variable. Chaque message consomme des tokens de l'API. Pour des volumes élevés (des milliers de conversations quotidiennes), le coût augmente. Un plan GPT-4o peut représenter USD 200-500/mois rien qu'en tokens pour une opération de taille moyenne.
- Contrôle limité. Vous ne pouvez pas garantir que la réponse sera exactement X. Vous pouvez guider avec des prompts, mais la génération a toujours un degré de variabilité.
- Latence. La réponse prend 1-3 secondes (le modèle "réfléchit"). Sur les canaux synchrones comme WhatsApp, l'utilisateur remarque le délai par rapport à un bot NLP qui répond en millisecondes.
- Dépendance vis-à-vis de tiers. Si l'API d'OpenAI (ou du fournisseur que vous utilisez) a un outage, votre bot reste muet.
Quand choisir le GPT pur
- Votre base de connaissances change fréquemment (catalogues, prix, politiques).
- Les questions sont ouvertes et variées (elles ne rentrent pas dans 30 intentions fixes).
- Vous souhaitez implémenter rapidement (jours, pas semaines).
- Le risque d'une réponse légèrement imprécise est tolérable (support L1, questions générales, pas de transactions financières).
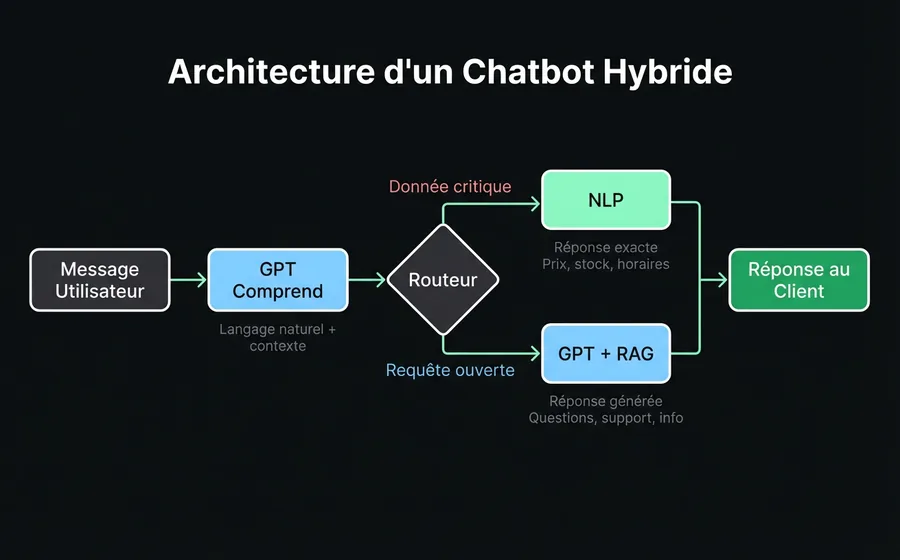
Qu'est-ce qu'un chatbot hybride
L'approche hybride n'est pas une troisième technologie : c'est une architecture qui combine le NLP et le GPT dans la même conversation, activant l'un ou l'autre selon le contexte.
Comment cela fonctionne en interne
- Couche de compréhension (GPT). Le message de l'utilisateur arrive et le modèle génératif le comprend en langage naturel, avec tout son contexte conversationnel.
- Routeur de décision. Un système de règles évalue : ce sujet nécessite-t-il une réponse déterministe (prix, stock, état d'une commande, donnée réglementaire) ? Si oui, il passe au module NLP. Sinon, le GPT répond directement depuis la base de connaissances.
- Couche NLP (routes déterministes). Pour les cas où la précision est non négociable, les réponses proviennent d'intentions entraînées : exactes, auditables, sans variation.
- Base de connaissances (RAG). Les deux couches consultent la même source de vérité : les documents de votre entreprise. Le GPT pour générer des réponses naturelles, le NLP pour valider des données spécifiques.
Avantages concrets
- Le meilleur des deux mondes. Flexibilité conversationnelle du GPT là où la précision exacte n'est pas primordiale, déterminisme du NLP là où elle est importante.
- Garde-fous natifs. Les hallucinations sont contenues car les données critiques (prix, disponibilité, horaires, statuts de commande) NE passent JAMAIS par la génération libre — elles passent par la voie NLP.
- Expérience utilisateur supérieure. Le client a l'impression de parler à quelqu'un qui comprend (GPT), mais les réponses métier sont fiables à 100 % (NLP).
- Maintenance équilibrée. Les intentions NLP ne couvrent que les 15-30 cas critiques (pas les 300 possibles), donc la maintenance est gérable. Le GPT avec RAG couvre la longue traîne sans entraînement supplémentaire.
Limitations réelles
- Complexité de la configuration. Configurer le routeur (quand NLP, quand GPT) nécessite une réflexion de conception. Ce n'est pas plug & play.
- Coût des deux couches. Vous payez l'hébergement du modèle NLP + les tokens du GPT. Bien qu'en pratique, comme le NLP résout les cas fréquents (qui sont les moins chers à résoudre), le coût total est généralement inférieur à celui du GPT pur.
- Débogage plus complexe. Quand quelque chose échoue, il faut savoir si l'échec s'est produit dans la couche GPT ou dans le NLP. Cela nécessite des logs clairs de la route empruntée par chaque conversation.
Quand choisir l'hybride
- Vous avez des cas d'utilisation mixtes: questions ouvertes (support général) + requêtes de données concrètes (prix, stock, statut).
- La précision est importante sur certains sujets mais pas sur tous.
- Vous allez évoluer (vous commencez avec 20 intentions NLP + GPT pour le reste, et vous développez organiquement).
- Vous voulez du contrôle là où vous en avez besoin et flexibilité là où non.
Comparaison détaillée
Précision et fiabilité
| Scénario | NLP | GPT | Hybride |
|---|---|---|---|
| "Combien coûte le plan Business ?" | Réponse exacte : 20 $/mois | Probablement correcte si elle est dans le RAG, risque d'erreur | Réponse exacte (chemin NLP) |
| "Je veux comprendre comment fonctionne l'IA conversationnelle pour mon entreprise" | Fallback (non entraîné) | Réponse naturelle et utile depuis le RAG | Réponse naturelle (chemin GPT) |
| "Annuler mon abonnement" | Chemin vers l'agent ou réponse prédéfinie | Peut tenter de résoudre seul (risqué) | Chemin vers l'agent (règle déterministe) |
| "Bonjour, j'ai un problème avec une commande que j'ai passée hier" | Fallback probable | Demande plus de données et escalade | Demande des données (GPT), consulte le CRM (NLP), répond |
L'hybride l'emporte dans les scénarios mixtes car il ne force pas toutes les conversations par le même canal.
Coût total d'exploitation (TCO)
Pour une opération de 2,000 conversations/mois avec ~8 messages en moyenne par conversation :
| Composant | NLP | GPT | Hybride |
|---|---|---|---|
| Plateforme de base | USD 50-150/mois | USD 50-150/mois | USD 100-260/mois |
| Tokens LLM | $0 | USD 80-200/mois | USD 40-100/mois |
| Bot builder (maintenance) | 8-16 h/mois | 2-4 h/mois | 4-8 h/mois |
| Coût des erreurs (clients perdus) | Moyen (fallbacks) | Élevé (hallucinations) | Faible |
| TCO estimé | USD 150-350/mois | USD 200-450/mois | USD 200-400/mois |
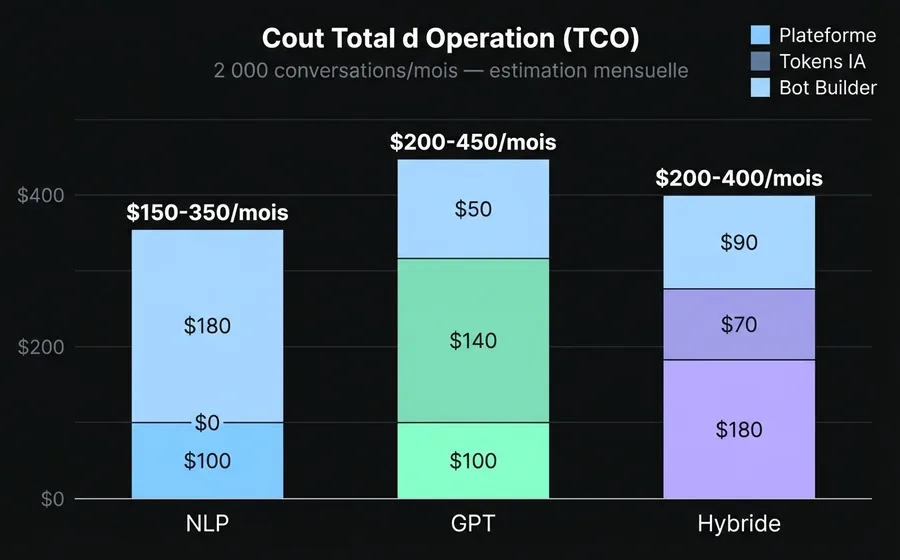
Le NLP semble moins cher jusqu'à ce que vous comptiez les heures du bot builder et le coût des fallbacks (clients qui n'obtiennent pas de réponse et partent). Le GPT semble cher jusqu'à ce que vous comptiez que vous n'avez pas besoin d'un bot builder à temps plein. L'approche hybride optimise les deux côtés.
Temps de mise en œuvre
| Phase | NLP | GPT | Hybride |
|---|---|---|---|
| Setup initial | 1-2 semaines | 2-5 jours | 1-2 semaines |
| Formation / knowledge base | 2-4 semaines | 1-3 jours | 1-2 semaines |
| Tests et ajustements | 1-2 semaines | 3-5 jours | 1-2 semaines |
| Total | 4-8 semaines | 1-2 semaines | 3-6 semaines |
GPT gagne en vitesse, mais "rapide à implémenter" ne signifie pas "prêt pour la production". Un GPT mal configuré mis en production en 3 jours peut faire plus de dégâts que de ne pas avoir de bot.
Évolutivité
- NLP: faire évoluer = ajouter des intentions, entraîner des variations, tester. Croissance linéaire avec effort humain.
- GPT: faire évoluer = ajouter des documents au RAG. Croissance quasi instantanée.
- Hybride: faire évoluer le GPT (ajouter des docs) est rapide. Faire évoluer les routes NLP (nouvelles données critiques) est planifié. Croissance contrôlée.
Trois erreurs courantes lors du choix
1. "GPT résout tout, je n'ai pas besoin de NLP"
L'erreur la plus coûteuse de 2025-2026. Les entreprises implémentent GPT sans garde-fous, et deux semaines plus tard, elles découvrent que le bot a dit à un client que le produit a une garantie de 5 ans (ce qui n'est pas le cas) ou que la livraison est gratuite (ce qui n'est pas le cas). Une seule hallucination sur les prix ou les politiques peut vous coûter plus que 6 mois d'abonnement à la plateforme.
2. "NLP est plus sûr, je m'en tiens à ça"
Sûr oui, mais sourd. Un bot NLP qui répond "je n'ai pas compris" à 40% des questions n'est pas plus sûr — c'est pire. Chaque repli est un client qui est parti sans réponse. La vraie sécurité est de bien répondre, pas d'éviter de répondre.
3. "J'implémente GPT maintenant et j'ajoute NLP plus tard si nécessaire"
La dette technique s'accumule rapidement. Si vous commencez avec du GPT pur et que vous avez ensuite besoin de routes déterministes, vous devrez refactoriser les flux, réentraîner et recalibrer le routeur. Il est plus efficace de concevoir l'architecture hybride dès le premier jour, même si vous commencez avec peu de routes NLP.
Comment chaque approche est implémentée en pratique
NLP: le flux typique
- Cartographier les 20-50 motifs de contact les plus fréquents avec l'équipe de support
- Rédiger des réponses modèles pour chaque intention
- Écrire 10-30 variations de chaque question pour l'entraînement
- Entraîner le modèle et calibrer les seuils de confiance
- Configurer les fallbacks et l'escalade vers des agents
- Tester avec des conversations réelles et ajuster
- Répéter chaque mois avec de nouvelles intentions
Des plateformes comme AsisteNLP simplifient ce processus avec des interfaces d'entraînement visuel et de réentraînement continu basé sur des conversations réelles que le bot n'a pas su résoudre.
GPT : le flux typique
- Recueillir la base de connaissances (FAQs, manuels, politiques, catalogue)
- Configurer le prompt du système avec le ton, les limites et les règles
- Implémenter le RAG : le modèle recherche dans vos documents avant de répondre
- Définir les guardrails : ce que le bot NE peut PAS dire (disclaimers, sujets interdits)
- Tester avec des edge cases (questions malveillantes, hors sujet, dans d'autres langues)
- Surveiller les hallucinations les 2 premières semaines intensivement
AsisteGPT offre ce flux avec des bases de connaissances custom, des prompts cachés (l'utilisateur ne les voit pas) et un RAG intégré, sans avoir besoin de code.
Hybride : le flux typique
- Phase GPT : charger la base de connaissances et configurer le prompt (3-5 jours)
- Phase NLP : identifier les 10-20 cas où la précision est critique et entraîner ces intentions
- Configurer le router : définir les règles de quand il passe au NLP et quand au GPT
- Intégrer avec le CRM : les routes NLP peuvent consulter des données en temps réel (stock, commandes, soldes) via AsisteAPI
- Tester le handoff entre les couches : la transition NLP↔GPT est-elle naturelle ?
- Lancer et surveiller les deux couches
La combinaison de AsisteChat (boîte de réception omnicanal) + AsisteNLP (routes déterministes) + AsisteGPT (génération avec RAG) est exactement cette architecture. Ce n'est pas un hasard si ce sont des modules séparés qui se combinent : chaque entreprise peut activer uniquement ce dont elle a besoin et évoluer du NLP pur vers l'hybride sans migrer.
Foire aux questions
Puis-je commencer avec le NLP et ajouter le GPT après ?
Oui, et c'est une voie courante. De nombreuses entreprises commencent avec 20-30 intentions NLP pour résoudre les cas les plus fréquents, et lorsque le volume augmente et que les fallbacks s'accumulent, elles ajoutent le GPT avec RAG pour couvrir la longue traîne. La clé est que votre plateforme supporte les deux dès le début afin que la migration soit une configuration, et non une réécriture.
Le GPT remplace-t-il le NLP ?
Non. Le GPT remplace le NLP en conversation ouverte, mais pas pour les réponses qui exigent une précision absolue. Pensez-y ainsi : le GPT est le généraliste qui sait parler de tout, le NLP est le spécialiste qui ne se trompe jamais sur son sujet. Une bonne opération a besoin des deux.
Combien coûte le GPT en tokens par mois ?
Cela dépend du modèle et du volume. Pour une opération de 2 000 conversations/mois avec GPT-4o mini, le coût en tokens est d'environ 40-80 USD/mois. Avec GPT-4o complet, 150-300 USD/mois. Les modèles plus économiques (GPT-3.5 turbo, Claude Haiku) peuvent descendre à 15-30 USD/mois avec une qualité acceptable pour le support L1.
L'approche hybride est-elle plus difficile à maintenir ?
C'est plus complexe à configurer initialement, mais plus facile à maintenir à long terme. Le NLP pur nécessite un réentraînement chaque fois qu'un nouveau sujet apparaît. Le GPT pur nécessite une surveillance continue des hallucinations. L'hybride réduit les deux charges : le GPT s'auto-met à jour avec de nouveaux documents, et les routes NLP ne couvrent que les cas critiques (peu nombreux, stables).
Qu'en est-il de la confidentialité des données si j'utilise GPT ?
Les données des conversations passent par l'API du fournisseur du LLM (OpenAI, Anthropic, Google, etc.). La plupart offrent des contrats de traitement de données (DPA) et des options de non-entraînement. Si votre entreprise gère des données sensibles (santé, finances), vérifiez que le fournisseur respecte la réglementation de votre pays. Certaines plateformes permettent d'utiliser des modèles on-premise ou dans votre propre cloud pour éviter que les données ne sortent de votre infrastructure.
Verdict
Si nous devions résumer la décision en une phrase :
- Choisissez NLP si vos conversations sont prévisibles, réglementées, et que vous avez un bot builder dédié.
- Choisissez GPT si vous avez besoin de rapidité de mise en œuvre, vos questions sont variées, et le risque d'une réponse imprécise est tolérable.
- Choisissez l'hybride si vous passez en production réelle, avec des cas mixtes, où certaines erreurs sont coûteuses et d'autres sont acceptables.
La vérité qui dérange est que la plupart des entreprises qui commencent avec du NLP pur ou du GPT pur finissent par migrer vers l'hybride dans les 6 premiers mois. Le NLP pur devient insuffisant lorsque le volume augmente. Le GPT pur devient risqué lorsqu'une erreur coûte de l'argent. L'hybride est le point de convergence de l'industrie.
Si votre plateforme actuelle ne prend en charge qu'une des deux approches, vous devrez migrer lorsque vous aurez besoin de l'autre. Choisir une plateforme qui prend en charge NLP, GPT et la combinaison dès le début — comme Bruno, avec AsisteNLP + AsisteGPT + AsisteCopilot comme modules combinables — vous épargne cette migration et vous donne la flexibilité de croître au rythme de votre opération, et non au rythme de votre fournisseur.
Continuez à lire
- Comment Peugeot Belchamp a transformé sa stratégie de leads avec AsisteClick — un cas réel d'implémentation hybride avec des résultats quantifiés