
L'erreur la plus courante lors de la construction d'un Agent d'IA n'est pas de mal choisir le modèle ni le canal. C'est tout mettre au même endroit.
Cela arrive toujours : quelqu'un configure un Agent d'IA pour le service client, et commence à insérer dans le prompt principal les politiques de retour, le catalogue de produits, les flux de recouvrement, le manuel de ton, les cas d'escalade, la liste des intégrations avec l'ERP, les questions fréquentes historiques et trois versions différentes de salutations selon le canal. Le prompt finit par contenir 8.000 mots. L'Agent devient lent, confond les contextes, répond avec des informations qui ne correspondent pas au cas, et coûte le double en tokens.
La solution n'est pas de "mieux écrire le prompt". C'est de comprendre que un Agent d'IA professionnel dispose de trois couches de connaissance bien différenciées, et chaque type d'information vit dans une couche distincte.
Ce guide explique quelles sont ces trois couches, ce qui va dans chacune, et comment les mapper aux outils réels que vous utilisez dans le constructeur de bots. Au final, vous pourrez regarder n'importe quel bloc d'instructions et dire avec certitude : "ceci va ici".
Table des matières
- Pourquoi un Agent d'IA n'est pas une encyclopédie
- Couche 1 : le prompt caché — ce que l'Agent sait toujours
- Couche 2 : la base de connaissance — ce que l'Agent consulte en cas de besoin
- Couche 3 : les interactions spécifiques — ce que l'Agent charge uniquement en contexte
- Comment décider dans quelle couche va chaque chose
- Erreurs courantes lors de la structuration des connaissances
- Questions fréquentes
Pourquoi un Agent d'IA n'est pas une encyclopédie
Imaginez que vous embauchez quelqu'un de nouveau pour le service client. Comment le formez-vous ?
Vous ne lui jetez pas le manuel complet de 500 pages le premier jour. Vous ne lui laissez pas non plus toutes les procédures imprimées sur le bureau pour qu'il les lise à voix haute à chaque appel. Ce que vous faites est autre chose :
- Vous lui enseignez les règles de base habituelles: comment saluer, le ton de la marque, ce qu'il peut et ne peut pas promettre, à qui escalader s'il n'a pas de réponse. Peu de texte, fort impact. C'est son manuel d'intégration, court et mémorable.
- Vous lui montrez où chercher quand il a besoin d'informations spécifiques: le wiki interne, le manuel de produit, le barème tarifaire actualisé. Il ne le mémorise pas, il sait que cela existe et le consulte lorsqu'une question concrète apparaît.
- Vous lui expliquez des procédures spécifiques lorsque le cas se présente: si un client demande un retour, ce jour-là vous lui expliquez les 12 étapes du processus de retour. Vous ne lui chargez pas les procédures de retour, d'échange, d'annulation, de réclamation et de nouvelle inscription toutes ensemble avant qu'il ne commence à servir les clients.
Un Agent d'IA professionnel fonctionne de la même manière. Il dispose de trois couches de connaissance qui remplissent ces trois fonctions distinctes. Ce qui change par rapport à un employé humain, c'est que Dans un Agent d'IA mal structuré, la couche 1 finit par être remplie d'informations qui devraient se trouver dans la couche 2 ou 3.. Et c'est là que le désastre commence.
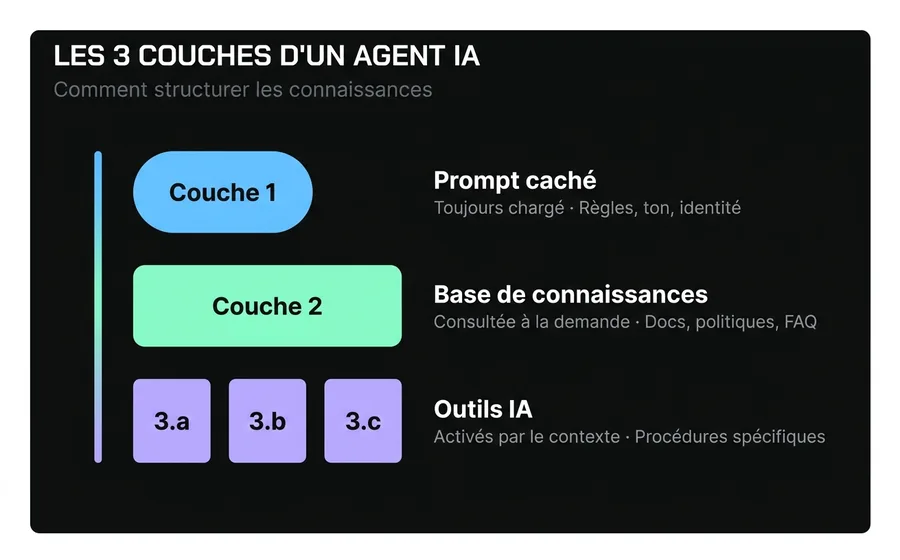
Couche 1 : le prompt caché — ce que l'Agent sait toujours
Le prompt caché est l'ensemble d'instructions que l'Agent d'IA reçoit à chaque conversation, avant de voir le message du client. Il est toujours chargé, consomme des tokens à chaque tour, et définit le cadre dans lequel l'Agent va opérer.
C'est pourquoi, ce que vous mettez ici doit remplir deux conditions :
- S'applique à toutes les conversations. Si quelque chose ne s'applique qu'à un flux spécifique, cela ne va pas ici.
- C'est compact et stable. Si cela change souvent, cela ne va pas ici (cela vous oblige à redéployer).
Ce qui va dans le prompt caché
- Identité de l'Agent: qui il est, pour qui il travaille, quel est son rôle. "Vous êtes l'assistant virtuel de [entreprise], une [industrie] en [pays]."
- Ton et langage: formel, informel, avec tutoiement, avec vouvoiement, neutre. Mots interdits. Emojis oui ou non.
- Règles métier strictes: "ne promettez jamais de dates de livraison exactes", "ne révélez pas les prix des produits sans confirmer la disponibilité", "si le client demande à parler à un humain, transférez sans demander".
- Critères d'escalade: quand transférer à un humain, à quelle équipe, avec quel contexte.
- Format de réponse par défaut: messages courts, utilisation de puces, utilisation d'emojis si applicable.
Ce qui NE va PAS dans le prompt caché
- Catalogues complets de produits.
- Politiques étendues (confidentialité, retours, conditions légales).
- Procédures étape par étape qui ne s'appliquent qu'à des cas spécifiques.
- Listes de prix changeantes.
- FAQs longues.
Règle pratique : si votre prompt caché dépasse les 1 000 mots, quelque chose ne va pas.
Un prompt masqué bien conçu pour le service client ne devrait pas dépasser 500 à 800 mots. Si le vôtre en a 3 000, vous mélangez presque certainement la couche 1 avec la couche 2 et la couche 3. Le modèle se déconcentre, la qualité diminue et le coût augmente.
En AsisteGPT, le prompt masqué est configuré par bot et est modifiable depuis l'interface. Vous n'avez pas besoin de toucher au code.
Couche 2 : la base de connaissances — ce que l'Agent consulte en cas de besoin
La base de connaissances est l'ensemble des documents, politiques, manuels, catalogues et FAQs que l'Agent peut consulter à la demande. La différence clé avec la couche 1 est que cela n'est pas chargé à chaque conversation. L'Agent consulte la base de connaissances uniquement lorsqu'il détecte qu'il a besoin d'informations de celle-ci pour répondre.
La technologie qui rend cela possible s'appelle RAG (Retrieval-Augmented Generation, ou "génération augmentée par récupération"). En pratique, cela fonctionne ainsi :
- Vous téléchargez vos documents dans la base de connaissances de l'Agent.
- La plateforme les divise en fragments et les indexe avec une recherche sémantique.
- Lorsque le client pose une question, l'Agent recherche des fragments pertinents et les utilise pour construire la réponse.
- Optionnellement, l'Agent peut citer d'où il a tiré l'information.
Ce qui va dans la base de connaissances
- Politiques complètes: retours, échanges, garanties, confidentialité, termes et conditions.
- Catalogues de produits ou services: fiches techniques, prix, spécifications.
- Manuels et guides d'utilisation du produit.
- FAQs étendues: les 200 questions les plus fréquentes avec leurs réponses officielles.
- Contenu du site web: les pages clés qui décrivent ce que vous faites et comment.
- Historiques des conversations précédentes que la plateforme utilise comme référence pour répondre comme un humain qualifié.
Ce qui NE va PAS dans la base de connaissances
- Procédures strictes étape par étape (elles vont dans la couche 3). Si un client demande à initier un retour, vous ne voulez pas que l'Agent cherche parmi des fragments épars du manuel — vous voulez qu'il suive la procédure exacte, dans l'ordre.
- Règles métier strictes (elles vont dans la couche 1). "Ne jamais promettre de dates" ne peut pas dépendre du fait que l'Agent trouve le bon fragment ; il doit toujours le savoir.
- Documents obsolètes ou contradictoires. Si vous téléchargez deux PDFs qui disent des choses différentes sur le même sujet, l'Agent citera celui qu'il trouvera en premier et la qualité de la réponse deviendra imprévisible.
Règle pratique : la curation est plus importante que le volume
Trois manuels mis à jour et clairs sont plus efficaces que 100 PDFs anciens, mal scannés et avec des informations superposées. La base de connaissance est un actif qui se maintient, pas un dépôt où l'on jette ce qui est en trop.
Couche 3 : les interactions spécifiques — ce que l'Agent charge uniquement en contexte
Voici la couche la plus sous-estimée — et celle qui fait la différence entre un Agent d'IA amateur et un professionnel.
Il existe un type de connaissance qui n'est ni générique (ne va pas dans la couche 1) ni recherchable (ne va pas dans la couche 2) : ce sont des procédures spécifiques qui n'ont de sens que lorsqu'un cas particulier se présente..
Exemples :
- Le flux de retour d'un produit : 12 étapes strictes dans l'ordre, avec des questions obligatoires, des validations et des bifurcations.
- Le processus de recouvrement pour un retard de 30 jours : ton spécifique, options de plan de paiement, escalade vers le service juridique en cas de désaccord.
- La prise de rendez-vous médical : demander la mutuelle, la spécialité, le lieu, proposer des horaires disponibles, confirmer les données, générer un rappel.
- La procédure de réclamation formelle : enregistrer le numéro de dossier, générer un ticket, assigner à une équipe, offrir un délai de réponse.
Si vous insérez les 4 procédures dans le prompt caché, le prompt atteint 5.000 mots et l'Agent se perd. Si vous les laissez dans la base de connaissance, l'Agent les consulte de manière incomplète (RAG fonctionne mal avec des instructions ordonnées, car il divise le document en chunks et mélange les étapes).
La solution correcte est de charger la procédure complète uniquement lorsque le cas se présente. Et l'outil pour ce faire est l' IA Tool.
Comment cela est mis en œuvre en pratique : IA Tools
Dans le module AsisteGPT, en plus du prompt caché et de la base de connaissance, l'Agent d'IA peut avoir IA Tools: des capacités que l'Agent lui-même décide d'invoquer lorsqu'il détecte que le cas le justifie.
Une IA Tool n'est pas un nœud de flux rigide. C'est une action que l'Agent sait exister (car il la voit listée avec sa description) et qu'il exécute lorsque le contexte de la conversation le justifie. Lorsqu'il l'exécute, la tool répond avec un bloc de texte qui est injecté comme contexte, et l'Agent rédige la réponse au client en utilisant cette information.
Il existe deux façons d'utiliser les IA Tools pour résoudre la couche 3 :
Option A : IA Tool mono-skill (la plus simple)
Un tool par procédure. Exemples :
- Tool "iniciar_devolucion" → lorsque l'Agent détecte que le client souhaite retourner quelque chose, il invoque ce tool. Le tool répond avec les 12 étapes de la procédure de retour. L'Agent suit ces étapes dans la conversation.
- Tool "consultar_plan_pago" → lorsque le client demande des options de paiement, le tool renvoie les tranches disponibles, les critères et les scripts suggérés.
- Tool "agendar_turno" → lorsque le client souhaite un rendez-vous, le tool renvoie la procédure de capture de données et la consultation de l'agenda.
Avantage: simple, clair, chaque tool fait une chose. L'Agent décide quand utiliser chacun par sa description.
Inconvénient: si vous avez de nombreuses procédures, la liste des tools se remplit et le contexte de base s'agrandit (même si c'est petit à petit, chaque description prend de la place).
Option B : IA Tool dispatcher (un seul tool avec un paramètre classificateur)
Un seul tool, par exemple "cargar_procedimiento", qui reçoit un paramètre de type Bot Question qui classifie quelle procédure apporter. Le paramètre a un enum avec les options disponibles ("devolucion", "cambio", "cobranza", "cancelacion", "alta_nueva", etc.).
Lorsque l'Agent détecte un cas qui nécessite une procédure spécifique, il invoque le tool avec la valeur correcte du paramètre, le tool répond avec le prompt de la procédure correspondante, et l'Agent suit cette procédure.
Avantage: s'adapte à de nombreuses procédures sans remplir la liste des tools. Un seul tool, de nombreuses destinations.
Inconvénient: nécessite de bien réfléchir au paramètre classificateur et à son enum. Si les options ne sont pas bien définies, l'Agent peut invoquer avec la mauvaise valeur.
Lequel choisir
- Jusqu'à 5 procédures: mono-skill. C'est plus transparent et plus facile à itérer.
- Plus de 5 procédures: dispatcher avec paramètre classificateur. S'adapte mieux.
- Mixte: vous pouvez avoir quelques tools mono-skill pour les procédures les plus critiques (où vous voulez un contrôle précis de leur activation) et un tool dispatcher pour le reste.
Ce qui va dans les interactions spécifiques (qu'il s'agisse de mono-skill ou de dispatcher)
- Flux opérationnels longs avec des étapes dans un ordre strict.
- Procédures avec questions obligatoires et validations.
- Flux avec bifurcations conditionnelles ("si le montant est supérieur à X, proposez un plan de paiement ; sinon, demandez un paiement unique").
- Processus qui nécessitent des appels à des API externes (ERP, CRM, agenda) dans le cadre du flux — dans ce cas, le tool peut, en plus de renvoyer du texte, déclencher l'appel API.
- Connaissance dense qui n'a de sens que dans un contexte spécifique.
Règle pratique : une tool = une procédure (ou une option du dispatcher)
Si quelque chose peut être décrit comme "lorsque le client demande X, je fais Y, Z, W dans l'ordre", c'est un candidat pour la couche 3. Ne le mettez pas dans le prompt caché. Créez une IA Tool (mono-skill ou dispatcher) pour ce cas.
Comment décider dans quelle couche va chaque élément
Lorsque vous avez une instruction ou un contenu et que vous ne savez pas où le placer, appliquez cet arbre de décision :
| Question | Si la réponse est... | Va dans... |
|---|---|---|
| S'applique-t-il à toutes les conversations ? | Oui | Couche 1 (prompt caché) |
| Est-ce une règle courte et immuable ? | Oui | Couche 1 (prompt caché) |
| Est-ce un document, un catalogue, une politique ou une FAQ étendue ? | Oui | Couche 2 (base de connaissances) |
| L'Agent doit-il rechercher le fragment pertinent ? | Oui | Couche 2 (base de connaissances) |
| Est-ce une procédure étape par étape avec un ordre strict ? | Oui | Couche 3 (IA Tool) |
| S'applique-t-il uniquement lorsque le client exprime une intention spécifique ? | Oui | Couche 3 (IA Tool) |
| Nécessite-t-il des appels à des APIs externes pendant le flux ? | Oui | Couche 3 (IA Tool) |
Exemples pratiques
Cas 1 : "Nos heures d'ouverture sont de 9h à 18h du lundi au vendredi."
→ Couche 1. C'est une information courte, immuable, qui s'applique toujours. Le prompt caché peut la mentionner pour que l'Agent réponde immédiatement sans rien consulter.
Cas 2 : "Nous avons 340 produits dans le catalogue avec leurs prix et leur stock."
→ Couche 2. C'est un volume élevé, l'Agent ne consulte que lorsque le client pose une question sur un produit spécifique.
Cas 3 : "Le processus de désabonnement comporte 8 étapes obligatoires et nécessite de valider l'identité du titulaire."
→ Couche 3. C'est une procédure stricte, elle ne s'applique que lorsque le client exprime l'intention de se désabonner.
Cas 4 : "Notre politique de retour autorise 30 jours à compter de l'achat si le produit n'est pas ouvert."
→ Couche 2. Elle fait partie de la politique, l'Agent la consulte lorsque le client pose des questions sur les retours. Si le client souhaite également initier un retour, cela déclenche un flux de couche 3.
Cas 5 : "N'offrez jamais de réductions de votre propre initiative."
→ Couche 1. C'est une règle commerciale stricte, elle s'applique toujours.
Erreurs courantes lors de la structuration des connaissances
Erreur 1 : inclure le catalogue complet dans le prompt caché
Le cas typique : un e-commerce avec 500 produits charge tout dans le prompt général "pour que le bot sache". Résultat : tokens gonflés, réponses plus lentes, et l'Agent se confond quand même car il ne distingue pas entre le produit demandé et les 499 autres. Où cela va: couche 2. Téléchargez le catalogue comme document structuré dans la base de connaissances.
Erreur 2 : écrire chaque procédure dans le prompt caché
Exemple : "Si le client demande un retour, demandez le numéro de commande, validez la date, proposez un avoir ou un remboursement...". Si vous avez 10 procédures comme celles-ci, votre prompt caché explose. Où cela va: couche 3. Chaque procédure est son propre IA Tool (mono-skill) ou une option d'un tool dispatcher.
Erreur 3 : télécharger n'importe quel PDF dans la base de connaissances sans le curer
Manuels scannés avec un mauvais OCR, documents dupliqués, anciennes versions qui contredisent les nouvelles. L'Agent cite ce qu'il trouve en premier et la qualité des réponses devient imprévisible. Comment y remédier: curez la base comme s'il s'agissait d'un manuel public. Moins de quantité, plus de qualité.
Erreur 4 : descriptions d'IA Tool vagues
Vous créez un tool de retour parfait, mais sa description dit "gère les retours". Le client écrit "je veux retourner le téléphone" et l'Agent ne l'invoque pas car il n'a pas compris clairement quand le faire. Comment y remédier: la description de chaque IA Tool doit expliquer avec précision quand doit être invoquée, avec des exemples. Ex: "Invoquer lorsque le client demande à retourner, rendre, rembourser ou échanger un produit acheté. Mots-clés typiques : retour, remboursement, ça ne m'a pas servi, je veux changer". Si vous utilisez un dispatcher, la même chose s'applique au paramètre classificateur.
Erreur 5 : mélanger le ton entre les couches
Le prompt caché dit "ton formel avec tutoiement", mais la base de connaissances contient des documents écrits en "vous" (vouvoiement). L'Agent copie le ton du document qu'il cite et semble incohérent. Comment y remédier: le ton est la responsabilité de la couche 1 et doit écraser ce qui vient de la couche 2. Instruisez explicitement l'Agent : "Répondez toujours en tutoiement, même si les documents de référence utilisent le vouvoiement."
Erreur 6 : ne pas auditer le prompt après avoir ajouté des fonctionnalités
Chaque fois qu'un nouveau cas est ajouté, quelqu'un ajoute une ligne au prompt général. Au bout de six mois, le prompt contient 40 règles qui se contredisent. Comment y remédier: révision trimestrielle du prompt caché. Déplacer vers la couche 2 ou 3 tout ce qui n'est pas indispensable, et déprécier les règles obsolètes.
Questions fréquentes
Quelle doit être la longueur de mon prompt caché ?
Entre 200 et 800 mots est sain pour la plupart des cas de service client. S'il dépasse 1 000, c'est le signe que certaines choses devraient se trouver dans la couche 2 ou la couche 3. Plus long n'est pas mieux : le modèle distribue son attention sur tout ce qu'il lit, et un prompt gonflé dilue les règles importantes.
Quels documents est-il conseillé de télécharger dans la base de connaissances ?
Priorité élevée : politiques officielles, manuels de produit actualisés, FAQs étendues, fiches techniques, contenu du site web. Priorité basse : présentations commerciales, documents internes sans format public, contrats (à moins qu'il ne s'agisse d'un Agent juridique). Règle générale : ne téléchargez que ce que vous donneriez à un nouveau client pour qu'il comprenne comment vous travaillez.
Quand dois-je créer un IA Tool au lieu de l'ajouter au prompt caché ?
Lorsqu'il remplit deux conditions : (1) il a plus de 4 ou 5 étapes dans l'ordre, et (2) il ne s'applique que lorsque le client exprime une intention spécifique. S'il n'en remplit qu'une seule, vérifiez : s'il est court et s'applique toujours, il va dans la couche 1. S'il est long mais consultable par fragments, il va dans la couche 2. S'il est long et s'active par le contexte de la conversation, c'est la couche 3.
Comment savoir si mon Agent d'IA est mal structuré ?
Quatre signes : (1) le prompt caché dépasse les 1 500 mots, (2) les réponses prennent plus de temps que prévu, (3) l'Agent mélange les contextes (il répond sur les retours quand on lui pose des questions sur les horaires), (4) le coût par conversation est plus élevé que prévu. Si vous voyez deux de ces signes ou plus, il est temps de redistribuer les connaissances entre les trois couches.
Puis-je déplacer des connaissances d'une couche à l'autre par la suite ?
Oui, et vous devriez le faire chaque fois que l'Agent grandit. Typiquement : vous commencez avec tout dans la couche 1 car c'est rapide à itérer. Lorsque vous dépassez une certaine taille, vous migrez les documents vers la couche 2 et les procédures longues vers la couche 3 en tant qu'IA Tools. Ce n'est pas un refactoring, c'est la maturité du produit. Le prompt caché devrait se réduire avec le temps, pas croître.
Comment l'Agent décide-t-il quand invoquer un IA Tool ?
À partir de la description que vous donnez à chaque tool (ou à chaque option du paramètre dispatcher) et du contexte de la conversation. C'est l'Agent lui-même qui décide, en temps réel, si le cas justifie d'invoquer le tool. C'est pourquoi la description est critique : elle doit décrire avec précision quand il doit être utilisé. Un bon format : "Invoquer lorsque [situation spécifique]. Mots-clés : [liste]. Exemples : [2-3 phrases typiques du client]".
Conclusion
Un Agent d'IA n'est pas un cerveau auquel vous jetez des informations jusqu'à ce qu'il apprenne. C'est un système avec des couches bien différenciées, et le bot builder qui comprend cela construit des Agents qui évoluent. Celui qui ne le comprend pas construit des prompts gigantesques que personne ne peut maintenir.
La règle simple : prompt caché pour ce qui s'applique toujours, base de connaissances pour ce qui est consulté, IA Tools pour ce qui est activé par le contexte. Si votre Agent respecte cette séparation, vous pourrez continuer à ajouter des fonctionnalités sans que chaque nouvelle règle ne brise les précédentes.
Si vous voulez mesurer l'impact d'une bonne structuration de votre Agent, nous avons préparé un guide pour calculer le ROI d'un chatbot avec des chiffres réels. Et si vous construisez un Agent d'IA à partir de zéro ou si vous souhaitez faire passer le vôtre au niveau supérieur, vous pouvez voir comment configurer le prompt caché, la base de connaissances et les IA Tools dans le module AsisteGPT.
Lisez la suite
- Prompt engineering pour chatbots : 7 techniques pour que votre bot d'IA réponde comme un expert — pour approfondir comment mieux écrire la Couche 1
- Comment mesurer le ROI d'un chatbot (avec la formule utilisée par les entreprises qui renouvellent) — pour quantifier l'impact d'un Agent bien structuré
- GPT-5.4 mini vs nano vs default : comment choisir le modèle pour votre Agent d'IA — pour combiner les 3 couches avec le modèle adéquat