
Le 5 mars 2026, OpenAI a lancé GPT-5.4. Une semaine plus tard, il a publié les variantes mini et nano. Dans le catalogue de templates d'Agents d'IA d'AsisteClick, les trois coexistent aujourd'hui : chacun résout un problème distinct, avec des profils de coût et de latence qui diffèrent d'un ordre de grandeur.
Si vous construisez un Agent d'IA sur WhatsApp, un copilot pour votre équipe de support ou un sous-agent qui résout une tâche spécifique, le choix du modèle définit 70% de l'économie du produit : coût par conversation, temps de réponse perçu et taux de résolution autonome.
Ce guide compare GPT-5.4 mini vs nano vs default avec des données officielles d'OpenAI, des benchmarks publiés et des cas concrets du catalogue d'AsisteClick. Au final, vous saurez exactement quel modèle choisir pour chaque type d'agent, combien cela vous coûtera et quand il convient de passer au flagship.
La famille GPT-5.4 : ce qui a changé par rapport à GPT-5
GPT-5.4 est la première famille qu'OpenAI a lancée avec utilisation native de l'ordinateur intégrée dans le modèle de base (pas comme un outil externe), 1 million de tokens de contexte dans la version flagship et un mécanisme de tool search qui réduit le coût des tokens dans les tâches avec de nombreux outils jusqu'à 47%.
Les trois modèles partagent :
- Knowledge cutoff : 31 août 2025.
-
Modalités : entrée de texte et d'image, sortie de texte. Audio et vidéo non supportés (pour l'audio, vous avez toujours besoin de
gpt-4o-audioou Whisper). - Capacités d'API : function calling, structured outputs, streaming, parallel tool use.
- Tool use : web search, file search, code interpreter, image generation, skills, MCP.
Ce qui change entre eux est puissance de raisonnement, taille du contexte, coût par token et latence. Et cette différence est celle qui vous oblige à penser comme un architecte avant de lancer un prompt.
Spécifications officielles : les 3 variantes dans un tableau
Données extraites de la documentation officielle d'OpenAI au 19 avril 2026.
| Spécification | gpt-5.4 | gpt-5.4-mini | gpt-5.4-nano |
|---|---|---|---|
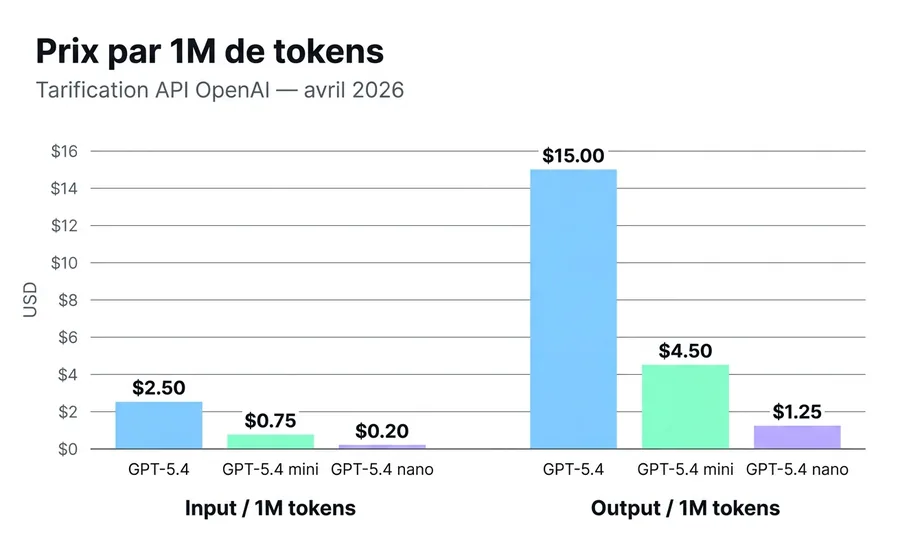
| Input / 1M tokens | $2.50 | $0.75 | $0.20 |
| Output / 1M tokens | $15.00 | $4.50 | $1.25 |
| Cached input / 1M tokens | $0.25 | $0.075 | $0.02 |
| Context window | 1.050.000 | 400.000 | 400.000 |
| Max output tokens | 128.000 | 128.000 | 128.000 |
| Function calling | Oui | Oui | Oui |
| Structured outputs | Oui | Oui | Oui |
| Utilisation native de l'ordinateur | Oui | Oui | Non |
| Tool search (optimisation) | Oui | Oui | Non |
| Modalités d'entrée | Texte + image | Texte + image | Texte + image |
| Effort de raisonnement | none / low / medium / high / xhigh | low / medium / high | low / medium / high |
Deux détails souvent négligés :
Le prix double après 272 000 tokens de prompt sur le flagship. Si vous chargez un document long ou un historique étendu, l'input passe de 2,50 $ à 5,00 $ par million de tokens. Cela fait du "1M de contexte" du flagship plus un plafond architectural qu'une invitation à envoyer des prompts géants.
Le cached input est le plus grand levier économique. Sur le mini, un token cacheado coûte 0,075 $/1M contre 0,75 $/1M pour l'input normal. Si votre agent a un system prompt long qui est réutilisé à chaque conversation (ce qui est typique), le cacher réduit le coût effectif entre 60 % et 80 %.
Le paramètre que personne n'explique : reasoning_effort
GPT-5.4 a introduit un paramètre qui redéfinit la façon dont vous payez pour l'intelligence : reasoning_effort. Il contrôle combien le modèle "pense" avant de répondre. Les valeurs sont none, low, medium, high et xhigh (seul le flagship supporte xhigh).
Chaque niveau consomme des tokens de raisonnement invisibles que vous payez comme output, mais qui n'apparaissent pas dans la réponse finale. C'est-à-dire : avec high, le modèle peut dépenser 2 000 à 5 000 tokens internes avant d'écrire le premier mot visible.
Heuristique pratique :
-
noneolow: réponses conversationnelles, FAQ, salutations, classification simple. Le modèle répond presque instantanément. -
medium: le default raisonnable. Service client, qualification de leads, triage. Il y a une étape d'analyse mais il reste responsive. -
high: tâches avec plusieurs étapes ou ambiguïté. Orchestration de sous-agents, diagnostic technique, négociation. -
xhigh: réservé aux agentic workflows longs où une erreur coûte plus que cinq secondes de latence. Compliance, décisions financières, code critique.
Dans le catalogue d'AsisteClick, l'orchestrateur multi-agent utilise gpt-5.4-mini avec
reasoning_effort=high parce qu'il doit décider à quel sous-agent déléguer. Un résumeur de conversations utilise low parce que la tâche est mécanique.
Benchmarks officiels : où chaque variante est performante
OpenAI a publié des résultats vérifiés sur les benchmarks standards de l'industrie au moment de la publication.
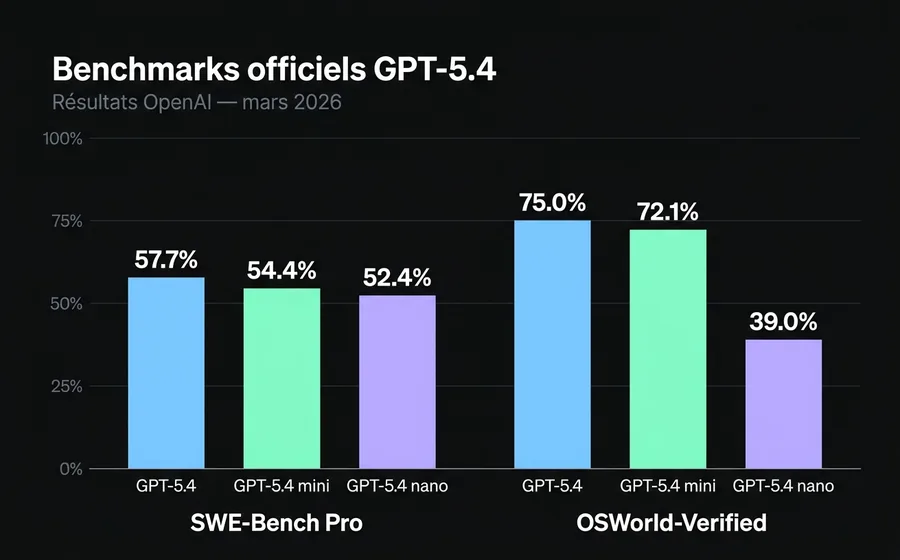
SWE-Bench Pro (tâches d'ingénierie logicielle réelles) :
- gpt-5.4: 57.7%
- gpt-5.4-mini: 54.4%
- gpt-5.4-nano: 52.4%
- gpt-5-mini (legacy): 45.7%
OSWorld-Verified (navigation d'environnements de bureau, proxy de "computer use") :
- gpt-5.4: 75.0% (dépasse la performance humaine moyenne, 72.4%)
- gpt-5.4-mini: 72.1%
- gpt-5.4-nano: 39.0%
La lecture importante n'est pas "qui gagne", mais où chaque modèle se distingue. Entre le flagship et le mini, il y a 3.3 points en coding et 2.9 en computer use. Entre le mini et le nano, il n'y a que 2 points en coding, mais 33 points en computer use. Nano n'est pas conçu pour des tâches agéntiques complexes : c'est un classificateur et extracteur à haut volume qui comprend fortuitement le langage naturel.
Si votre agent a besoin de gérer des GUIs ou d'exécuter des étapes multi-tool avec état, mini est votre seuil. Nano ne comblera jamais cet écart même si vous augmentez reasoning_effort.
Coût réel : combien coûte l'opération de chaque modèle
Le pricing par million de tokens semble bon marché jusqu'à ce que vous le multipliiez par le volume. Faisons le calcul avec un cas concret : un Agent d'IA sur WhatsApp qui traite 10 000 conversations par mois, où chaque conversation a en moyenne 6 tours et 200 tokens par tour (moitié input, moitié output).
Cela donne 6 millions de tokens input + 6 millions output mensuels.
Coût mensuel estimé sans mise en cache :
- gpt-5.4 : $15 (input) + $90 (output) = $105/mois
- gpt-5.4-mini : $4.50 + $27 = 31,50 $/mois
- gpt-5.4-nano : $1.20 + $7.50 = 8,70 $/mois
Avec cached input (system prompt réutilisé, en supposant un taux de réussite du cache de 80 %) :
- gpt-5.4-mini : $0.90 + $27 = 27,90 $/mois
- gpt-5.4-nano : $0.24 + $7.50 = 7,74 $/mois
Pour un opérateur avec 100 000 conversations/mois, la différence entre mini et flagship est de 1 000 $ par mois. Pour 1 000 000 de conversations, 10 000 $ par mois. La décision concernant le modèle est littéralement une décision de marge opérationnelle.
Comment nous le résolvons chez AsisteClick : les 3 types d'agents et leur modèle
Dans le catalogue actif d'AsisteClick, il y a 33 templates d'agents IA et de copilotes, classés en trois catégories. Le modèle attribué à chaque template n'est pas arbitraire : il répond à la relation entre la complexité de la tâche, la latence tolérable et le coût par interaction.
Aujourd'hui, le catalogue est en migration progressive vers la famille 5.4. Les nouveaux templates démarrent déjà en gpt-5.4-mini o gpt-5.4-nano. Les legacy (créés avant mars 2026) fonctionnent toujours sur gpt-5-mini et sont mis à jour au fur et à mesure qu'ils sont révisés individuellement, car changer le modèle peut altérer le comportement de l'agent en production.
Agents IA autonomes (ai-agent) — 18 templates
Ce sont des agents qui conversent directement avec le client final sur WhatsApp, webchat, Instagram ou d'autres canaux. Ils répondent aux questions, qualifient les leads, planifient des rendez-vous, gèrent les commandes ou les recouvrements.
Modèle recommandé : gpt-5.4-mini avec reasoning_effort=medium.
Pourquoi : la conversation avec un humain sur WhatsApp tolère 1 à 3 secondes de latence au maximum avant de paraître "lente". Mini avec medium se situe dans cette fourchette et maintient une qualité de raisonnement suffisante pour 95 % des interactions. Le flagship ne se justifie que lorsque l'agent doit effectuer des agentic workflows (appeler plus de 5 tools en séquence, raisonner sur des documents longs).
Exemples du catalogue :
-
Recouvrement IA (
ai-collections):gpt-5.4-mini, medium. Décide du ton, conclut des plans de paiement, délègue les cas complexes. En détail, le template est aligné avec ce que nous avons discuté dans chatbot de recouvrement WhatsApp pour les fintechs et se connecte avec des intégrations comme Loan Collection. -
Ventes IA (
ai-sales):gpt-5.4-mini, medium. Qualifie les leads et planifie des démos. Modèle expliqué dans qualifier les leads WhatsApp avec un chatbot IA. -
Orchestrateur Multi-Agents (
ai-orchestrator):gpt-5.4-mini, high. C'est la seule exception où le reasoning augmente car il doit choisir entre des sous-agents. -
Planificateur avec des API de Calendriers (
ai-asiste-booking):gpt-5.4-mini, medium, avec un code interpreter activé. C'est le seul template qui utilise du code car il doit calculer la disponibilité en fonction des fuseaux horaires et des règles de calendrier. Nous le détaillons sur la page de destination de prise de rendez-vous.
Copilots (assistants internes pour agents humains) — 9 templates
Ces modèles ne parlent pas avec le client. Ils assistent l'agent humain : suggèrent des réponses, traduisent des messages, résument des conversations, détectent des opportunités de vente, désamorcent des situations tendues. Le détail complet du modèle se trouve dans copilots d'agents IA : réponses en temps réel.
Modèle recommandé par défaut : gpt-5.4-mini avec
reasoning_effort=low o medium selon la tâche.
L'exception intéressante : le copilot de traduction en temps réel
(copilot-translator) est le seul template du catalogue qui utilise . La traduction conversationnelle est déterministe, ne nécessite pas de raisonnement en chaîne et l'agent humain attend le texte pour l'envoyer. Nano répond avec la moitié de la latence de mini et à un cinquième du coût. Un copilot qui se déclenche 200 fois par heure d'attention doit être bon marché ou rien ne le justifie.
gpt-5.4-nanoAutres copilots du catalogue : e-mail, résumé, KB, réponse suggérée, test, désescalade, opportunité de vente, notes internes.
Subagents (outils spécialisés) — 6 templates
Ce sont des agents qui ne conversent pas : ils exécutent une action ponctuelle invoquée par un autre agent. Ils consultent la facturation, s'intègrent avec Zapier ou n8n, traitent un paiement MercadoPago, consultent la météo.
Son agentes que no conversan: ejecutan una acción puntual invocada por otro agente. Consultan facturación, integran con Zapier o n8n, procesan un checkout de MercadoPago, consultan el clima.
Modèle recommandé : gpt-5.4-mini avec reasoning_effort=low. Sortie brève, tâche déterministe, invoqué de nombreuses fois par session.
Le subagent-weather est le seul avec image generation activée (pour renvoyer la prévision sous forme d'image composite), un détail qui montre comment chaque template est configuré chirurgicalement selon le tool nécessaire.
Matrice de décision : quel modèle pour quel cas
Si vous construisez un Agent d'IA à partir de zéro et ne savez pas par où commencer, ce tableau résout 90% des cas.
| Cas d'utilisation | Modèle | Reasoning | Pourquoi |
|---|---|---|---|
| Classification d'intents | gpt-5.4-nano | low | Tâche déterministe, volume élevé |
| Extraction de données structurées | gpt-5.4-nano | low | Output schema fixe, structured outputs |
| Traduction en temps réel | gpt-5.4-nano | low | Latence critique, sans raisonnement |
| Service client WhatsApp | gpt-5.4-mini | medium | Conversationnel avec contexte |
| Qualification de leads | gpt-5.4-mini | medium | Décisions sur de multiples variables |
| Recouvrements automatiques | gpt-5.4-mini | medium | Ton + négociation + règles |
| Planification avec tools | gpt-5.4-mini | medium | Function calling + code interpreter |
| Orchestrateur multi-agents | gpt-5.4-mini | high | Routing avec contexte |
| Résumé des tickets | gpt-5.4-mini | low | Batch, non conversationnel |
| Analyse de documents longs (>400K tokens) | gpt-5.4 | medium / high | Nécessite 1M de contexte |
| Compliance / décisions à haut risque | gpt-5.4 | xhigh | Raisonnement maximal disponible |
| Agentic workflow avec 10+ tools | gpt-5.4 | high / xhigh | Tool search + raisonnement profond |
Cette matrice n'est pas théorique : elle reproduit la logique avec laquelle les templates du catalogue d'AsisteClick sont configurés aujourd'hui.
Quand passer au flagship GPT-5.4
Mini est le nouveau par défaut pour 80% des cas. Flagship se justifie lorsque l'une de ces conditions est remplie :
- Contexte supérieur à 400.000 tokens. Mini et nano coupent à 400K. Si votre agent doit analyser un dossier juridique complet, un log de sessions d'un mois ou une base de connaissances sans chunking, le flagship avec son contexte de 1.050.000 tokens est la seule option. N'oubliez pas qu'au-delà de 272K, le prix de l'input double.
-
Workflow agentique avec plus de 10 outils. Le
tool_searchdu flagship est optimisé pour réduire le coût des tokens lorsque de nombreux outils sont disponibles simultanément. Un agent de support technique qui navigue entre CRM, ticketing, KB, monitoring et facturation en bénéficie ici. - Usage informatique dans des environnements visuels complexes. Si l'agent doit opérer une interface graphique inconnue (OSWorld-Verified 75% vs 72.1% de mini), la différence justifie le coût.
-
Raisonnement
xhigh. Seul le flagship supporte ce niveau. Décisions juridiques, audit financier, révision de code en production : vous payez plus, mais la marge d'erreur est réduite.
Dans le catalogue d'AsisteClick, aucun template ne fonctionne aujourd'hui en flagship par défaut. Il est réservé comme option manuelle pour les clients du plan IA Plus avec des cas spécifiques d'analyse documentaire ou de compliance.
Chemin de migration recommandé : commencer avec mini, monter en gamme là où le besoin se fait sentir
Si vous démarrez un Agent d'IA à partir de zéro, le chemin le plus efficace est :
Étape 1 — Commencez avec gpt-5.4-mini y reasoning_effort=medium. C'est le 80/20 de la famille. Vous couvrirez presque tous les cas avec une qualité suffisante et un coût maîtrisé.
Étape 2 — Mesurez la latence et la qualité par type d'interaction. Séparez les conversations par intent et mesurez deux choses : temps de réponse moyen et taux de résolution sans escalade humaine. Si la latence vous pose problème dans une catégorie spécifique (ex: classification initiale), abaissez ce nœud à
nano avec reasoning=low.
Étape 3 — Passez au flagship uniquement là où vous échouez. Si un cas spécifique a un faible taux de résolution autonome malgré reasoning=high en mini, essayez le flagship avec
xhigh. Mais mesurez : la différence est généralement de 2-4 points d'accuracy pour 3-4× le coût.
Étape 4 — Implémentez le prompt caching dès le premier jour. Un system prompt mis en cache vous fait économiser jusqu'à 80% du coût de l'input. Si votre agent a un system prompt de 3.000 tokens et que vous l'utilisez 10.000 fois par mois, cela représente 30M de tokens que, avec le cache, vous payez à $0.075/1M au lieu de $0.75/1M.
C'est le même chemin que nous suivons chez AsisteClick lorsque nous migrons un client de chatbots legacy vers des agents d'IA. Nous ne commençons jamais en flagship. Nous passons à l'échelle uniquement lorsqu'il y a des preuves que mini ne suffit pas.
Si vous souhaitez approfondir la conception des prompts qui accompagnent cette décision, lisez notre guide de prompt engineering pour les agents de service client. Si vous comparez cette approche aux chatbots traditionnels, la discussion de fond se trouve dans chatbot NLP vs GPT vs hybride.
Implémentation dans AsisteClick
La plateforme AsisteClick vous donne accès au catalogue complet de templates sans que vous ayez à choisir le
modèle manuellement : chaque template est préconfiguré avec le modèle, reasoning_effort,
outils (web search, code interpreter, image generation) et variables recommandées pour votre cas d'utilisation.
Si vous partez de zéro, AsisteGPT vous permet de cloner un template du catalogue (recouvrement, ventes, support, planification, traduction, orchestrateur) et de l'adapter à votre entreprise en quelques minutes. Si vous avez déjà une équipe humaine opérant des canaux, AsisteCopilot il ajoute les 9 copilots du catalogue (suggestion de réponse, traduction, résumé, désescalade) sans modifier le flux de l'agent.
Les plans qui incluent la famille d'agents IA commencent à IA Plus à partir de 260 $/mois (ou 208 $/mois avec facturation annuelle).
Questions fréquentes
GPT-5.4 mini est-il meilleur que GPT-5 mini ?
Oui, sur toutes les métriques publiées. GPT-5.4 mini a obtenu 54,4 % sur SWE-Bench Pro contre 45,7 % pour GPT-5 mini, et fonctionne plus de 2× plus rapidement avec le même pricing. OpenAI a recommandé dans le release de l'appeler "le nouveau default" pour les applications de production. La seule raison de rester sur GPT-5 mini est qu'un agent en production se comporte bien et que vous ne souhaitez pas modifier son tuning.
Quelle est la différence de latence entre mini et nano ?
OpenAI n'a pas publié de latences exactes pour la famille 5.4, mais le comportement observé est cohérent
avec la génération précédente : nano répond avec un temps au premier token (TTFT) proche de 900 ms et mini dans la
plage de 1,2-1,8 s avec reasoning=medium. La différence est perceptible dans les chats en direct où
l'utilisateur s'attend à voir "en train d'écrire…" sans longues pauses.
Peut-on utiliser GPT-5.4 nano pour un chatbot WhatsApp ?
Vous pouvez, mais ce n'est pas le meilleur choix sauf pour des tâches très spécifiques comme la classification d'intents ou l'extraction de données au début du flux. Pour la conversation complète, mini est préférable : nano obtient 33 points de moins que mini dans OSWorld-Verified (tâches agentiques) et a tendance à échouer lorsqu'il doit raisonner sur un contexte conversationnel long.
Le contexte d'un million de tokens du flagship est-il utile en pratique ?
Il est utile pour des cas spécifiques : analyse de dossiers, traitement de logs complets, audit documentaire. Mais le prix double après 272 000 tokens, ce n'est donc pas une invitation à envoyer des prompts géants par défaut. La plupart des cas sont mieux résolus avec le chunking + retrieval (RAG) sur mini qu'en envoyant tout le contexte brut au flagship.
Comment calculer le coût réel de mon agent IA ?
Prenez le volume mensuel de conversations, multipliez par la moyenne de tokens par conversation
(généralement 1 000-3 000 au total entre input et output) et appliquez le pricing du modèle que vous comptez utiliser.
Ajoutez 10-30 % de marge pour les tokens de raisonnement invisibles (si vous utilisez reasoning_effort
medium ou high). Si vous mettez en cache le system prompt, l'input effectif diminue entre 60 % et 80 %.
Quand le knowledge cutoff est-il mis à jour ?
GPT-5.4 a un cutoff au 31 août 2025. Si votre agent a besoin d'informations ultérieures (changements réglementaires, nouveaux produits, prix actualisés), vous avez deux options : activer web search comme tool (tous les modèles le supportent) ou connecter une base de connaissances propre via RAG. La seconde est moins chère, plus rapide et plus contrôlable.
Le function calling fonctionne-t-il de la même manière dans les trois variantes ?
Oui, les trois supportent le function calling et les structured outputs avec la même fidélité. La différence
apparaît lorsqu'il y a de nombreux tools simultanément : le flagship dispose d'un tool_search qui optimise
le choix, mini bénéficie de la majeure partie de l'optimisation, et nano peut se dégrader avec plus de 10 tools
disponibles.
Choisir le bon modèle n'est pas une décision technique isolée : cela définit le coût opérationnel, la latence perçue et le plafond des capacités de votre produit. Avec GPT-5.4, la réponse par défaut n'est plus "le moins cher qui fonctionne" ni "le flagship par précaution". C'est mini avec reasoning medium, en escaladant chirurgicalement là où vous mesurez qu'il échoue.
Si vous souhaitez voir les 33 templates du catalogue fonctionner sur WhatsApp, webchat et d'autres canaux, demandez une démo d'AsisteGPT.