En février 2024, le PDG de Klarna a annoncé fièrement que son Agent d'IA — développé avec OpenAI — avait fait le travail de 700 agents humains durant son premier mois. Il a traité 2,3 millions de conversations, réduit le temps de résolution de 11 minutes à moins de 2, et allait faire économiser à la fintech suédoise 40 millions de dollars en 2024. La presse tech était euphorique. Le PDG a déclaré publiquement que « l'IA peut déjà faire tous les métiers que nous, humains, faisons ». 18 mois plus tard, Klarna réembauche des humains.
Pas par regret moral. À cause d'un problème de qualité mesurable que le tableau de bord initial ne montrait pas.
Ce post n'est pas une chronique d'opinion. C'est l'analyse opérationnelle de ce qui s'est passé chez Klarna, des schémas de la même erreur que nous voyons se répéter dans les opérations latino-américaines, et de l'architecture concrète qui fonctionne en pratique pour éviter le même destin. Si cela mérite un post complet — et pas seulement un paragraphe — c'est parce que le cas Klarna est le premier exemple public et documenté d'une entreprise qui a misé « tout sur l'IA » dans le service client, mesuré les résultats honnêtement et fait machine arrière. Toute l'industrie observe la fin de cette histoire pour décider de son prochain mouvement.
Acte 1 : la promesse de février 2024
Le 27 février 2024, Klarna et OpenAI ont publié un communiqué conjoint. Les chiffres du premier mois de l'Agent d'IA en production étaient difficiles à ignorer :
- 2,3 millions de conversations traitées en 30 jours
- Deux tiers de toutes les requêtes du service client
- Temps de résolution moyen : moins de 2 minutes, contre 11 minutes auparavant
- 25 % de requêtes répétées en moins, indiquant une résolution au premier contact
- 23 marchés, 35+ langues dès le premier jour
- Impact projeté : 40 millions USD d'amélioration des bénéfices pour 2024

Brad Lightcap, alors COO d'OpenAI, a scellé l'annonce avec une déclaration : « Klarna est à l'avant-garde parmi nos partenaires en matière d'adoption et d'application pratique de l'IA ». Sebastian Siemiatkowski, PDG de Klarna, est allé encore plus loin : « L'IA peut déjà faire tous les métiers que nous, humains, faisons. »
Il faut comprendre pourquoi la promesse était crédible à ce moment-là. Les chiffres initiaux étaient réels. Le bot fonctionnait. La satisfaction moyenne était comparable à celle des agents humains. Klarna ne mentait pas — l'entreprise présentait les données qu'elle avait avec l'interprétation la plus optimiste possible.
L'erreur n'était pas dans la présentation. Elle était dans le choix de la donnée à regarder.
Acte 2 : la dégradation silencieuse
Ce que le tableau de bord de Klarna montrait, c'était la moyenne. Ce qu'il cachait, c'était la distribution.
Quand une entreprise de services financiers gère 2,3 millions de conversations par mois, la majorité de ces requêtes sont routinières : « combien je dois ? », « quand est la prochaine échéance ? », « comment changer ma carte ? ». Pour ces questions, un Agent d'IA bien construit répond mieux qu'un humain. Il est plus rapide, plus cohérent, ne se fatigue pas, ne se trompe pas par distraction. Klarna n'avait pas tort sur ce diagnostic.
Le problème a commencé à apparaître dans ce qui était statistiquement invisible — les 5-10 % de cas complexes. Les remboursements contestés. Les frais incorrects. Les plans de paiement en difficulté. Les cas de fraude. Les situations où le client arrive frustré, avec peu de marge émotionnelle, et où un détail mal traité peut dégénérer en plainte réglementaire.
Trois schémas ont été documentés dans les mois suivants :
Hallucinations sur les politiques de frais et de remboursement. L'Agent d'IA de Klarna répondait avec assurance sur des termes qui n'avaient pas été correctement chargés, ou qui avaient changé entre versions. Dans une entreprise d'e-commerce, une réponse incorrecte sur un coupon est un désagrément. Dans une fintech, une réponse incorrecte sur un frais ou une date d'échéance est un problème de conformité.
Chute du CSAT sur les cas complexes. La moyenne restait stable parce que les cas routiniers étaient si nombreux qu'ils cachaient la dégradation. Mais en segmentant par complexité, les cas qui étaient escaladés à un humain après être passés par le bot montraient des niveaux de satisfaction nettement pires que ceux qui allaient directement à un humain. La raison : le client répétait toute l'information, sentait que le bot lui avait fait perdre du temps, et arrivait au humain déjà énervé.
Augmentation du Customer Effort Score. La métrique qui mesure l'effort que le client doit fournir pour résoudre son problème a commencé à grimper mois après mois. Au début, c'était attribuable au changement. Quand la courbe ne s'est pas aplatie, il est devenu clair que c'était un schéma structurel, pas transitoire.
Le Better Business Bureau a accumulé plus de 900 plaintes formelles contre Klarna en trois ans, principalement sur des sujets de remboursement et de facturation — précisément le quadrant où une réponse confiante mais incorrecte fait plus de dégâts que le silence.
Mi-2025, l'équipe interne de Klarna a recommencé à embaucher des agents humains. Sans annonce publique. Sans contre-marche visible. Juste une correction de cap silencieuse.
Acte 3 : le revirement
Le silence a pris fin en mai 2025. Siemiatkowski a parlé à Bloomberg et a dit, dans une phrase devenue le point d'inflexion d'une époque entière de l'industrie : « Nous sommes allés trop loin. »
Les mots exacts du PDG dans cet entretien et ceux qui ont suivi dressent une carte de l'erreur :
« Nous nous sommes trop concentrés sur le coût. Le résultat a été une qualité moindre. »
« Du point de vue de la marque, du point de vue de l'entreprise, je pense qu'il est crucial d'être clair avec votre client : il y aura toujours un humain si vous le voulez. »
Le nouveau modèle annoncé par Klarna n'est pas un retour au centre d'appels traditionnel. Il est hybride. L'entreprise a décrit le format comme « style Uber » : agents humains à distance avec horaires flexibles, principalement étudiants et parents avec disponibilité partielle, équipés d'outils d'IA qui les assistent à chaque conversation. L'IA continue de gérer le gros du volume routinier. Les humains prennent le complexe, l'émotionnel, et ce qui requiert du jugement.
Il faut noter la différence avec le récit « l'IA ne marche pas ». Klarna n'a pas dit cela. Klarna a dit « l'IA marche, mais pas pour tout, et le coût de découvrir où elle ne marche pas s'est avéré plus élevé que ce que nous avons économisé ». Cette distinction est ce qui définit quelles entreprises survivront au cycle et lesquelles feront la même annonce en 2027.
Pourquoi c'est arrivé : les 3 erreurs structurelles
Le cas Klarna n'est pas un échec technique. La technologie a fonctionné. Ce qui a échoué, c'est la logique d'évaluation. Trois erreurs reviennent quand on analyse ce qui s'est passé.
Erreur 1 : confondre déflexion et résolution
Le taux de déflexion mesure quel pourcentage de requêtes n'arrive pas à un humain. Le taux de résolution mesure quel pourcentage de problèmes du client sont effectivement résolus. Ce n'est pas la même chose.
Un Agent d'IA peut avoir 85 % de déflexion et 60 % de résolution. Cela signifie que sur 100 requêtes, 85 n'ont pas été escaladées à un humain — mais seulement 60 ont été résolues. Les 25 autres se sont fermées sans résolution : le client a abandonné, a utilisé un canal alternatif, ou est simplement parti.
Le tableau de bord de Klarna montrait la déflexion. La réalité du client était la résolution. Quand les deux chiffres divergent, le premier trompe le second.
Erreur 2 : ignorer le paradoxe de Polanyi
Il y a 30 jours, nous avons publié une analyse sur le paradoxe de l'automatisation, inspirée de l'idée du philosophe Michael Polanyi : « nous savons plus que nous ne pouvons dire ». Il existe un savoir humain qui ne peut être articulé en règles — lire la frustration d'un client avant qu'elle ne soit énoncée, sentir quand la bonne réponse est la mauvaise réponse, ajuster le ton en temps réel.
L'IA générative a capturé une partie de ce savoir tacite en apprenant de millions de conversations. Mais elle a capturé la couche superficielle — les schémas de réponse. La couche profonde — le jugement contextuel — reste humaine. Klarna a automatisé la couche superficielle en croyant qu'elle avait tout automatisé. La différence est apparue dans les cas limites, qui sont précisément ceux qui comptent le plus dans une fintech.
Erreur 3 : sous-estimer le coût des réponses confiantes mais erronées en conformité
Il y a des industries où une réponse incorrecte a un coût faible. Si l'Agent d'IA d'un service de livraison répond mal sur les heures d'ouverture, le client se fâche et l'affaire se ferme. Il y a d'autres industries où la même réponse incorrecte peut générer une amende réglementaire, une plainte formelle ou un cas juridique.
Recouvrement en fintech, assurance, santé, crédit à la consommation : tous sont des quadrants où la vitesse et la confiance avec lesquelles le bot répond mal sont proportionnellement nuisibles. En Amérique latine, cela est amplifié par la réglementation de protection du consommateur — un message mal rédigé peut être utilisé comme preuve dans une réclamation.
Klarna se trouve exactement dans ce quadrant. Buy now, pay later. Frais. Dates d'échéance. Litiges. L'entreprise a choisi le secteur le plus risqué pour mener l'expérience la plus radicale.
Ce que nous voyons en Amérique latine
En tant qu'opérateurs d'une plateforme de service client avec des centaines de comptes actifs en Amérique latine, nous voyons le schéma Klarna se répéter en miniature chaque mois. C'est suffisamment cohérent pour le décrire comme un anti-schéma.
La séquence typique est la suivante. Une entreprise décide d'automatiser le support. Au premier trimestre, le taux de déflexion passe de 60 % à 85 %. L'équipe célèbre. Au deuxième trimestre, quelqu'un remarque que le CSAT a baissé de 1,5 point mais reste dans la variance statistique. Au troisième trimestre, les plaintes sur les réseaux sociaux augmentent. Au quatrième trimestre, l'équipe d'opérations rapporte que le taux de re-contacts — clients revenant pour le même problème — a augmenté de 18 points. À ce stade, le coût de la dégradation de la marque a déjà dépassé ce qui a été économisé en effectif.
Ce qui s'est passé chez Klarna à l'échelle mondiale, dans une entreprise latino-américaine de 100 mille clients arrive à l'échelle locale. La forme de la courbe est la même.
Trois particularités régionales valent la peine d'être soulignées :
Plus grande attente d'« humain quand j'en ai besoin ». En Amérique latine, la culture du service client a une friction plus faible avec l'escalade vers un humain. Le client argentin ou mexicain qui voit le bouton « parler à une personne » l'utilise plus vite que l'européen. Cela a une implication opérationnelle : si votre Agent d'IA cache le handoff, vous le pénalisez plus fort que sur d'autres marchés.
Verticales de conformité plus exposées. L'Argentine et le Brésil ont une réglementation active de protection du consommateur. Une conversation WhatsApp avec une réponse incorrecte sur un frais ou un recouvrement peut être présentée comme preuve formelle. La barre de qualité dans la réponse n'est pas « satisfaire le client ». C'est « ne pas exposer l'entreprise à une amende ».
Adoption accélérée de WhatsApp comme canal principal. 80 % des premières interactions commerciales en Amérique latine se font par messagerie. L'erreur de Klarna sur le chat web est amplifiée sur WhatsApp parce que la conversation reste sur le téléphone du client comme preuve, capturable, partageable et reproductible sur les réseaux sociaux si cela tourne mal.
Les 3 leçons opérationnelles
Si Klarna nous a laissé quelque chose, ce sont trois règles actionnables. Nous les appliquons en production et les recommandons à toute entreprise qui évalue aujourd'hui le remplacement total par l'IA.
Leçon 1 : le handoff est la métrique qui définit si votre Agent d'IA fonctionne
Pas la déflexion. Pas la vitesse. Le handoff.
Un bon système hybride se reconnaît parce que : (a) quand le bot escalade vers un humain, il le fait avec la conversation entière transférée — le client ne répète pas l'information ; (b) le SLA après handoff est réaliste, pas « bientôt » ; (c) l'agent humain voit le contexte, les suggestions du bot, et décide en quelques secondes.
Si votre plateforme actuelle ne vous permet pas de mesurer le handoff timing, le handoff completion rate et le resolution rate post-handoff, vous mesurez le tableau de bord de Klarna en février 2024.
Leçon 2 : hybride > IA pure, dans toute verticale avec conformité ou émotion
Ce n'est pas un choix philosophique. C'est un choix de risque. Une IA pure est efficace quand le coût de l'erreur est faible. Dès que le coût de l'erreur monte — amendes réglementaires, dommage à la marque, abandon du client — le modèle hybride domine.
Dans l'architecture que nous recommandons, un module NLP gère les flux prévisibles (consultation de solde, prise de rendez-vous, FAQ). Un module GPT avec base de connaissances propre gère les requêtes ouvertes qui requièrent une compréhension contextuelle. Un Copilot assiste l'agent humain quand la conversation s'escalade. Et une boîte de réception unifiée avec routing garantit que le handoff est instantané et avec contexte préservé.
Leçon 3 : les verticales de conformité requièrent des guardrails spécifiques, pas plus d'entraînement
Quand une réponse incorrecte peut générer une amende, le problème ne se résout pas avec « plus de données d'entraînement ». Il se résout avec des guardrails : réponses pré-approuvées pour les sujets de frais, refund, litige ; escalade automatique vers un humain quand des mots-clés de réclamation légale apparaissent ; logging total de la conversation avec timestamping pour audit.
L'architecture en trois couches de connaissance — prompt caché, base de connaissances, interactions spécifiques — est précisément le cadre qui permet de définir ces guardrails sans que le bot perde de fluidité dans le non-sensible.
À quoi ressemble un système hybride bien construit
Pour que la leçon soit actionnable, il convient d'ancrer l'architecture. Un système hybride bien construit a trois composantes et un protocole.
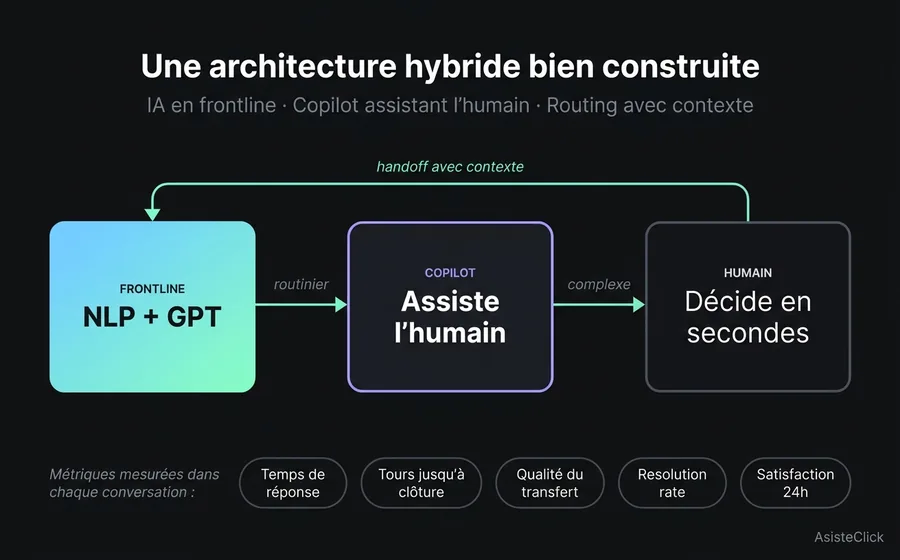
Composante 1 : le frontline automatisé. Le gros du volume entre ici. Requêtes routinières, FAQ, processus transactionnels connus. Un module NLP couvre le prévisible avec précision et vitesse. Un module GPT avec base de connaissances propre couvre l'ouvert mais limité au domaine de l'entreprise. L'important : ce niveau ne gère jamais ce qui présente un risque de conformité sans escalade explicite.
Composante 2 : le Copilot de l'agent humain. Quand la conversation s'escalade, l'humain qui la reçoit n'entre pas à l'aveugle. Il voit la transcription complète, un résumé automatique du contexte, des suggestions de réponse basées sur des cas similaires antérieurs, et les données du client chargées depuis le CRM. La vitesse de l'humain hybride se rapproche de celle du bot, mais avec jugement intégré.
Composante 3 : la boîte de réception unifiée avec routing. Le client ne sait pas — et ne s'en soucie pas — si la réponse vient du bot, du Copilot ou de l'humain pur. Pour lui, c'est une conversation continue. Derrière, le système route chaque tour vers la bonne ressource : bot pour les questions connues, humain pour les cas sensibles, Copilot pour l'humain assisté.
Le protocole : mesure end-to-end. Chaque conversation se mesure en cinq points. (1) temps à la première réponse, (2) nombre de tours jusqu'à résolution ou handoff, (3) s'il y a eu handoff, qualité du transfert (le client a-t-il répété l'info ?), (4) resolution rate à la clôture, (5) satisfaction à 24 heures post-clôture. Si l'un de ces cinq se dégrade et que les autres restent stables, vous savez déjà où est le problème.
Ce n'est pas une architecture conceptuelle. C'est ce qui tourne aujourd'hui dans des comptes latino-américains avec des volumes mensuels allant de 5 mille à 500 mille conversations.
Cela signifie-t-il que l'IA ne sert pas ?
Non. Et il faut le dire clairement parce que la couverture tech oscille de l'enthousiasme de 2024 au pessimisme symétrique de 2026, et les deux extrêmes sont incorrects.
L'IA générative dans le service client fonctionne. Elle résout des volumes auparavant inimaginables. Elle réduit les temps de réponse de minutes à secondes. Elle permet d'offrir une attention 24/7 sans coût opérationnel prohibitif. Elle capture le savoir tacite et le distribue à l'équipe.
Ce qui ne fonctionne pas, c'est le modèle de remplacement total. Et pas parce que l'IA est mauvaise, mais parce que le service client n'est pas seulement du traitement d'information — c'est aussi de la gestion de la confiance, de l'émotion et du risque. Quand une entreprise tente d'automatiser ce second niveau sans garder d'humains, ce qui est économisé en coûts opérationnels est perdu en valeur de marque et en exposition réglementaire.
Klarna n'a pas échoué en utilisant l'IA. Elle a échoué en l'utilisant à la place de humains au lieu de aux côtés de humains. La différence entre les deux prépositions — « à la place de » vs « aux côtés de » — est la différence entre le communiqué de février 2024 et l'entretien à Bloomberg en mai 2025.
Les entreprises qui mèneront les prochaines années sont celles qui ont appris de l'expérience d'autrui avant de devoir payer la leur.
Questions fréquentes
Cela signifie-t-il que Klarna abandonne l'IA ?
Non. Klarna maintient son Agent d'IA en production en gérant le gros du volume routinier. Ce qui a changé, c'est qu'elle a réembauché des humains pour les cas où l'IA a montré ses limites — litiges, remboursements complexes, situations de difficulté financière. Le nouveau modèle est hybride : l'IA fait ce qu'elle fait le mieux, l'humain intervient quand le coût de l'erreur monte.
Cela arriverait-il dans une entreprise latino-américaine ?
Oui, et nous le voyons en fait arriver tous les mois à plus petite échelle. Quand une entreprise latino-américaine décide de remplacer le service humain par un Agent d'IA pur, le schéma est le même : la déflexion monte, le CSAT moyen se maintient, mais le pourcentage de re-contacts et la satisfaction sur les cas complexes se dégradent silencieusement. La différence est qu'en Amérique latine le cycle est plus rapide en raison de la culture d'attention plus humaine et de la réglementation de protection du consommateur plus active.
Combien d'humain est « suffisant » dans un modèle hybride ?
Cela dépend de la verticale, mais la règle opérationnelle est qu'entre 15 % et 30 % des conversations devraient être escaladées à un humain dans toute entreprise avec une composante de conformité, financière ou émotionnelle. Si votre taux de déflexion dépasse 85 % en recouvrement, support assurance ou support santé, il y a une forte probabilité que vous cachiez des handoffs ratés au lieu de les éviter.
Quelle métrique remplace le taux de déflexion comme indicateur de succès ?
Le taux de résolution pondéré par la satisfaction à 24 heures. C'est-à-dire, quel pourcentage de conversations ont fermé le problème du client ET à 24 heures le client rapporte une satisfaction positive. Cette métrique est plus difficile à mesurer mais reflète la valeur réelle du service. La déflexion est une métrique opérationnelle qui ne fonctionne que si elle est corrélée avec la résolution — et dans de nombreux cas, elle ne l'est pas.
Cela change-t-il avec GPT-5 ou avec des modèles open source comme Llama 4 ?
Des modèles plus capables résolvent plus de cas correctement, mais ne résolvent pas la leçon structurelle. Même si GPT-5 réduisait le taux d'hallucination à 1 %, le client qui tombe dans ce 1 % a toujours la pire expérience de votre marque. La question opérationnelle n'est pas « à quel point l'IA est-elle bonne en moyenne », mais « que se passe-t-il avec le client quand l'IA échoue ». Cette question est architecturale, pas du modèle.
Comment éviter l'erreur de Klarna dès le début ?
Trois règles actionnables. D'abord, mesurez le resolution rate et la qualité du handoff dès le premier jour, pas seulement la déflexion. Ensuite, segmentez le CSAT par complexité du cas — la moyenne agrégée cache les problèmes jusqu'à ce qu'ils soient déjà visibles à l'extérieur. Enfin, gardez des humains dans le circuit dès le début dans tout cas avec une composante réglementaire ou émotionnelle. Le remplacement total fonctionne dans les cas routiniers. L'hybride fonctionne pour tout le reste.
Conclusion
Le cas Klarna sera étudié dans les écoles de commerce pendant des années. Pas pour la décision d'implémenter l'IA — c'était correct et cela reste correct — mais pour la décision de remplacer des humains en croyant que la moyenne du tableau de bord équivalait à l'expérience client. La moyenne est rarement la réalité d'un client individuel, et dans le service client, le client individuel est l'unité de l'entreprise.
La bonne nouvelle, c'est que l'erreur est documentée. Le PDG a admis les mots exacts. La courbe de dégradation a été mesurée. La correction de cap est publique. Les entreprises qui viennent maintenant peuvent apprendre sans payer le ticket d'entrée.
Si votre entreprise évalue aujourd'hui le remplacement total par l'IA, la décision la plus stratégique que vous pouvez prendre ce trimestre est de lire le cas Klarna en détail, de segmenter vos métriques par complexité et d'ajuster votre architecture avant d'exécuter. La différence entre mener le changement et répéter l'expérience est exactement le temps que vous prenez pour faire cette analyse.
Continuez votre lecture
- Le paradoxe de l'automatisation : pourquoi plus d'IA exige plus d'humanité — le cadre philosophique qui a prédit ce revirement
- Les 3 couches de connaissance d'un Agent d'IA — comment définir des guardrails sans perdre de fluidité
- Chatbot de recouvrement par WhatsApp en fintech — le quadrant de plus grand risque en Amérique latine
- Copilot pour agents : comment l'IA suggère des réponses sans remplacer l'humain — le modèle que Klarna implémente maintenant
- Récupérer les paniers abandonnés via WhatsApp avec l'IA — l'architecture hybride appliquée à un cas opérationnel concret en e-commerce