
De chercher à demander : le changement qui est déjà en cours
Il y a une donnée qu'il convient de garder à l'esprit avant toute discussion sur le GEO : la recherche traditionnelle ne meurt pas, elle perd des parts. Google continue de traiter des milliards de requêtes par jour. Mais le gâteau de la découverte se redistribue, et la part que prennent les moteurs d'IA générative est passée de quelque chose de marginal en 2023 à un canal structurel en 2026.
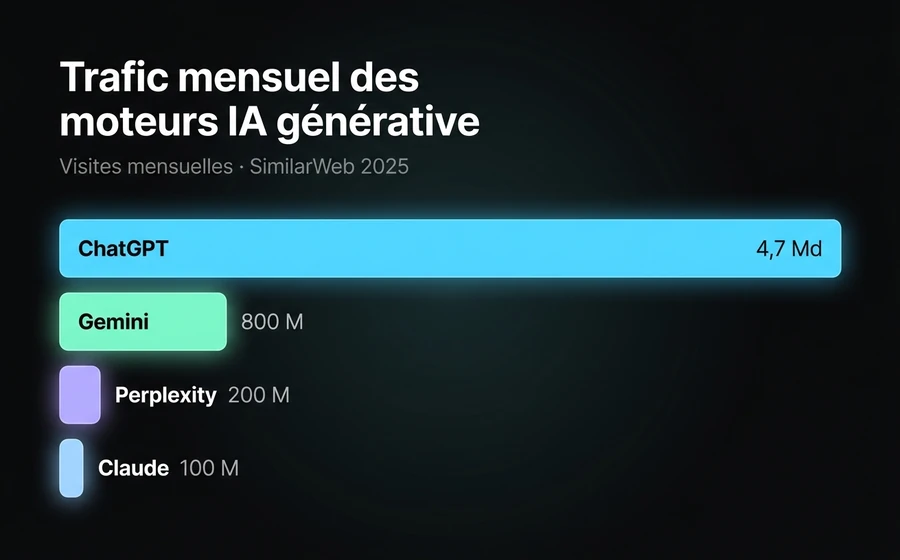
Les données publiques le confirment sous plusieurs angles. SimilarWeb a enregistré en mai 2025 que ChatGPT recevait 4,7 milliards de visites mensuelles mondiales, avec une croissance annuelle de 137 %. Perplexity, plus de niche mais croissant à 200 % en glissement annuel, a dépassé les 200 millions de visites. Google a ajouté AI Overviews (les réponses générées qui apparaissent au-dessus du SERP traditionnel) dans plus de 60 % des requêtes informationnelles, selon les mesures d'Authoritas et SE Ranking de mars 2026. Et les moteurs de recherche natifs d'IA — l'OAI-SearchBot d'OpenAI, le Claude-SearchBot d'Anthropic, le ChatGPT Search lancé fin 2024 (la différence entre ces moteurs est couverte dans le comparatif NLP vs GPT vs hybride) — sont désormais un canal de trafic indépendant que tout site avec une présence LATAM devrait mesurer séparément.
Le changement est important car les deux logiques sont distinctes. Dans une recherche traditionnelle, vous produisez le document et l'utilisateur décide d'entrer ou non. La distance entre vous et la décision de l'utilisateur est un clic. Dans une requête à un LLM, vous produisez le document, le modèle le traite, et livre à l'utilisateur une synthèse. La distance entre vous et la décision est une citation — s'il vous a mentionné, vous avez gagné de l'attention ; sinon, vous n'existez pas. Et contrairement au SEO classique, où deux résultats peuvent coexister en première page, dans une réponse de ChatGPT seuls trois ou quatre noms entrent. L'espace est brutalement plus limité.
Cela explique pourquoi les entreprises qui ont compris tôt le changement investissent dans le GEO avec le même sérieux qu'elles ont investi dans le SEO en 2010 : ce n'est pas optionnel, c'est la prochaine couche de visibilité. La différence est que le terrain technique est encore en formation. Les règles ne sont pas écrites avec le détail des directives de Google. Il existe des standards émergents (le llms.txt proposé par Jeremy Howard en septembre 2024), des signaux dont nous savons qu'ils comptent (structure sémantique, autorité thématique, freshness) et de nombreuses hypothèses raisonnables qui se valident avec des données.
La question opérationnelle est la même que toujours : comment augmentez-vous la probabilité que votre marque apparaisse quand quelqu'un pose une question ? La différence est que la réponse a changé.
Comment un LLM vous cite : le pipeline technique
Pour comprendre pourquoi certaines choses fonctionnent en GEO et d'autres non, il convient de regarder comment un modèle de langage produit une réponse lorsque quelqu'un l'interroge sur votre marque ou votre vertical. Il y a trois couches qui opèrent en simultané, et chacune a des mécaniques distinctes.
Couche 1 : données d'entraînement (knowledge cutoff). Chaque modèle a un corpus d'entraînement avec une date de coupure. GPT-5 a été entraîné avec des données jusqu'à début 2025. Claude Opus 4 jusqu'à mars 2025. Gemini 2.5 jusqu'au début 2025. Cela signifie que la connaissance « stable » du modèle sur votre marque dépend de ce que votre marque avait publié et de la façon dont elle était citée jusqu'à cette date. Si votre site existait déjà et avait de l'autorité, le modèle a déjà des représentations internes sur vous. Si vous venez de lancer il y a deux mois, non.
Cette couche est la plus difficile à modifier à court terme : vous ne contrôlez pas quand le prochain modèle s'entraîne. Ce que vous contrôlez, c'est quel corpus il trouve quand il s'entraîne : si votre contenu est exhaustif, citable, bien structuré et référencé par des tiers, il entrera dans le training set avec un poids plus important (nous le couvrons en détail dans les 3 couches de connaissance d'un Agent IA). C'est du SEO classique porté à un autre plan.
Couche 2 : retrieval en temps réel (RAG et search grounding). C'est ici que se trouve le levier court du GEO. La plupart des moteurs modernes ne répondent pas uniquement depuis leurs poids : ils effectuent une recherche en direct lorsqu'ils reçoivent votre question. ChatGPT avec recherche activée (via ChatGPT Search et le bot OAI-SearchBot), Perplexity (qui est RAG-first par conception), Claude avec recherche web activée (Claude-SearchBot), Google Gemini avec search grounding intégré. Tous consultent le web pendant qu'ils génèrent la réponse.
Cette recherche utilise des signaux différents de Google. Perplexity, par exemple, priorise les sources qu'elle considère « autoritatives » — un mix de domaines établis, de qualité de contenu, et de match avec la requête. ChatGPT Search, selon les déclarations publiques d'OpenAI, pondère la présence éditoriale, la fréquence d'actualisation et la structure. Ce que presque tous partagent, c'est la préférence pour un contenu qui peut être ingéré proprement : HTML sémantique, données structurées, headers clairs, et des fichiers comme llms.txt qui leur indiquent où trouver le contenu pertinent sans avoir à crawler cent pages.
Couche 3 : synthèse avec ou sans citation. Une fois que le modèle a du matériel (de son entraînement + du retrieval), il produit la réponse. Et ici, il y a une décision que le modèle prend à la volée : mentionne-t-il la source ou non ?
Perplexity cite toujours. Cela fait partie de son produit. ChatGPT Search cite la plupart du temps. Claude cite quand le modèle considère que l'information vient d'une source identifiable. Gemini cite sélectivement. Et dans les réponses « off-search » (lorsque le modèle n'a pas besoin de chercher parce qu'il sait déjà), les citations sont rares ou inexistantes.
L'implication opérationnelle est énorme : votre objectif n'est pas seulement d'apparaître dans la réponse, c'est d'apparaître cité avec votre URL. Une mention sans lien, c'est quelque chose. Une mention avec lien vers votre site, c'est du trafic, de la conversion et de l'autorité accumulée. Les pratiques GEO modernes optimisent pour la seconde.

GEO vs SEO classique : ce qui change
Si vous pensez le GEO comme « du SEO sous stéroïdes », vous allez optimiser pour le mauvais moteur. Il existe des différences structurelles qui changent la tactique.
| Dimension | SEO classique | GEO |
|---|---|---|
| Unité de succès | Position dans le SERP | Citation dans la réponse générée |
| Densité de concurrence | Top 10 visible, top 3 avec CTR élevé | 3 à 5 marques mentionnées au maximum |
| Signal d'intent de l'utilisateur | Mot-clé (parfois ambigu) | Question naturelle complète |
| Autorité | Backlinks, domaine, expertise | Citations croisées + structure sémantique + présence préalable dans le training set |
| Freshness | Crawl rate + sitemap | Cutoff du modèle + retrieval en direct |
| Long-tail | Longue traîne de mots-clés | Longue traîne de questions (bien plus diverse) |
| Métrique directe | Ranking, clics, impressions (GSC) | Citations (il n'existe pas d'équivalent unifié, il faut le mesurer manuellement ou avec des outils externes) |
| Volatilité | Mouvements liés aux algorithm updates | Changements liés aux nouvelles versions du modèle + changement de retrieval logic |
| Path de trafic | SERP → votre site | Question → réponse synthétisée → citation → votre site (plus de friction) |
Les deux disciplines partagent une base : contenu de qualité, site rapide, structure claire, autorité thématique. La différence, c'est ce que vous ajoutez par-dessus.
Pour le SEO classique, les leviers sont les mots-clés, les backlinks, la vitesse et la satisfaction de l'utilisateur mesurée par le dwell time. Pour le GEO, le levier est la citabilité : à quel point il est facile pour un modèle de comprendre ce que vous faites, de trouver la bonne information sur vous, et de décider de vous mentionner en réponse à une question spécifique. Une page d'accueil jolie mais opaque peut bien ranker sur Google et être invisible dans ChatGPT. Une page dense, structurée, avec des définitions claires et des données peut ranker médiocrement sur Google et être citée par Perplexity chaque semaine.
Il y a un détail que beaucoup de guides GEO sous-estiment : le SEO classique ne se remplace pas. Conserver le trafic indexé est le socle. Le GEO se construit par-dessus. Les deux optimisations se renforcent : le contenu qui ranke bien sur Google est celui qui entre dans le training set des modèles à la prochaine itération. Annuler le SEO pour « passer au GEO » est une erreur de débutant. Le bon réflexe est de bien faire le SEO ET d'ajouter la couche GEO.
Le stack technique GEO 2026
C'est la partie dense du guide. Cinq couches techniques que n'importe quel site peut implémenter en une semaine de travail. Nous allons utiliser asisteclick.com comme référence parce que c'est ce que nous avons en production et publiquement inspectable.
4.1 llms.txt : le standard Howard
Jeremy Howard (cofondateur d'Answer.AI, fast.ai) a proposé en septembre 2024 un standard simple que beaucoup de sites adoptent déjà : un fichier llms.txt à la racine du domaine qui donne au LLM une carte structurée du site. Ce n'est pas un crawler config. C'est du contenu éditorial pensé pour être lu par un modèle.
La structure est en markdown et comporte trois blocs :
# Nom du site
> Résumé exécutif en une ou deux phrases qui expliquent ce que fait le site.
Bloc de contexte optionnel : qui, où, échelle, proposition de valeur.
## Section 1
- [Titre de la page](url) : Brève description.
- [Autre page](url) : Brève description.
## Section 2
...Le secret, c'est que la première ligne blockquote (>) est l'« elevator pitch » qu'un LLM peut citer littéralement si la question est « qu'est-ce que X ? ». Le résumé que vous écrivez là, formulé avec vos mots, est exactement ce qu'un modèle utilisera quand un utilisateur vous cherchera. Si votre blockquote est générique, votre citation sera générique.
Notre llms.txt (publié sur asisteclick.com/llms.txt, 22 Ko, accessible publiquement) s'ouvre ainsi :
AsisteClick est une plateforme SaaS de service client omnicanal avec agents IA. Elle unifie WhatsApp, Facebook, Instagram, Telegram, email et webchat avec des bots GPT/NLP, un CRM natif et des envois en masse.
Une phrase. Catégorie (SaaS de service client). Différenciateur (omnicanal avec IA). Stack (canaux). Modules clés (bots, CRM, envois en masse). Si un modèle a besoin de répondre « qu'est-ce qu'AsisteClick » en trente mots, c'est la réponse. Sans cette phrase explicite, le modèle improvise — et l'improvisation d'un LLM sur votre marque est exactement ce que vous voulez éviter.
Ensuite viennent les sections : produits, canaux, solutions par industrie, intégrations, blog. Chaque lien a une description d'une ligne. Non on ne réplique pas le contenu de chaque page : on donne le contexte suffisant pour que le modèle sache quand la recommander. Si quelqu'un demande « quel chatbot pour les agences immobilières me recommandez-vous ? », le modèle voit la ligne « WhatsApp pour l'immobilier : répond, qualifie et programme les visites » et fait le match.
4.2 llms-full.txt : contenu complet curé
Si llms.txt est la carte, llms-full.txt est le contenu. C'est un fichier plus lourd (dans notre cas 1 Mo) qui concatène les pages pertinentes du site en markdown brut, sans navigation, sans scripts, sans bloat. C'est ce que vous voulez qu'un LLM ingère s'il décide d'approfondir.
Pourquoi deux fichiers ? Parce que les modèles ont des fenêtres de contexte. Le llms.txt de 22 Ko tient dans n'importe quelle fenêtre. Le llms-full.txt de 1 Mo tient dans GPT-5 (qui a un contexte étendu) mais pas dans des modèles plus petits. En offrant les deux, vous laissez le client choisir selon sa capacité.
La règle opérationnelle pour llms-full.txt : incluez les pages que vous voulez qu'un modèle apprenne en profondeur — produits centraux, études de cas avec métriques, comparatifs, FAQ exhaustives, articles pillar de votre blog. Excluez : pages légales, index, navigation, contenu obsolète. Markdown brut sans tableaux exotiques. Chaque section avec son URL canonique à côté pour que le modèle puisse créer le lien.
4.3 robots.txt pour les AI crawlers : la politique explicite
Le robots.txt a toujours été le territoire du SEO. En 2026 c'est aussi celui du GEO, mais avec une nuance : il y a désormais plus de 20 nouveaux user-agents correspondant aux bots d'IA, et chacun remplit une fonction différente. Vous avez besoin d'une politique explicite, pas d'une omission.
Les principaux bots à considérer :
| Bot | Entreprise | Fonction |
|---|---|---|
GPTBot |
OpenAI | Crawl pour training |
ChatGPT-User |
OpenAI | Fetch on-demand lorsqu'un utilisateur mentionne votre URL dans ChatGPT |
OAI-SearchBot |
OpenAI | Crawl pour ChatGPT Search |
ClaudeBot |
Anthropic | Crawl pour training |
Claude-Web |
Anthropic | Fetch on-demand |
Claude-User |
Anthropic | Fetch on-demand initié par l'utilisateur |
Claude-SearchBot |
Anthropic | Crawl pour recherche |
PerplexityBot |
Perplexity | Crawl + retrieval |
Perplexity-User |
Perplexity | Fetch on-demand |
Google-Extended |
Opt-in séparé pour le training de Gemini (n'affecte pas l'indexation de Google Search) | |
Bytespider |
ByteDance / TikTok | Crawl pour Doubao |
Meta-ExternalAgent |
Meta | Crawl pour LLaMA |
Amazonbot |
Amazon | Crawl pour Alexa / Q |
Applebot-Extended |
Apple | Opt-in séparé pour le training |
La décision stratégique : autorisez-vous tout, bloquez-vous tout, ou appliquez-vous une politique mixte ? Les trois sont valables selon le cas.
- Allow all (la nôtre) : maximiser la probabilité d'apparaître dans n'importe quel LLM. Sens si votre modèle d'affaires bénéficie de la visibilité, vous n'avez pas besoin de protéger du contenu premium et votre publication publique est déjà l'offre.
- Block training, allow retrieval : bloquer
GPTBot,ClaudeBot,Google-Extended(tous ceux qui entraînent), mais autoriserChatGPT-User,Claude-User,OAI-SearchBot,PerplexityBot. Sens si vous voulez être cité en temps réel mais pas faire partie du prochain modèle « for free ». C'est la politique de nombreux grands médias (New York Times, Wall Street Journal). - Block all : bloquer tous les bots IA. Sens uniquement si votre contenu est propriétaire, votre modèle est en paywall strict et vous ne voulez aucune fuite.
Notre politique complète dans asisteclick.com/robots.txt est ALLOW ALL explicite pour les crawlers IA. Nous l'avons choisie parce qu'AsisteClick vend à un marché LATAM où la visibilité dans les LLM est la prochaine frontière de la découverte, et bloquer les bots reviendrait à bloquer une part de marché en formation.
4.4 Schema.org : le signal structuré que les LLM lisent vraiment
Les données structurées avec JSON-LD existent depuis des années pour le SEO. Mais les LLM les lisent avec plus d'enthousiasme que Google dans certains cas, parce qu'elles leur permettent de parser le contenu sans ambiguïté. Trois types qui comptent particulièrement pour le GEO :
Articledans les articles : inclut auteur, date de publication, date de modification, description, headline. Un LLM qui évalue si votre article sur « WhatsApp Business API » est citable regarde ledateModifiedpour savoir si l'information est toujours d'actualité.Organizationsur la home et le footer : inclut nom, logo, description, adresse, contacts, réseaux sociaux, fondateurs. C'est la « carte de visite » pour les entités — les LLM construisent des représentations d'entités à partir de ces données.FAQPagelà où vous avez une FAQ visible : chaque question-réponse devient parseable. C'est de l'or pur pour le GEO : quand quelqu'un demande à un LLM « comment fonctionne X ? », le modèle peut reprendre la réponse de votre FAQ presque littéralement.
Une décision technique importante : utiliser JSON-LD dans <script type="application/ld+json"> et non du microdata dans le HTML. JSON-LD est ce que les LLM lisent facilement. Microdata est davantage en désuétude.
4.5 Autres signaux : open graph, sitemap, sémantique du HTML
Trois signaux mineurs mais qui s'additionnent :
- Open Graph complet avec
og:title,og:description,og:image,og:type: bien que pensé à l'origine pour les réseaux sociaux, les LLM l'utilisent comme description concise quand ils ne trouvent rien de mieux. - Sitemap XML avec
lastmodréel : les crawlers d'IA priorisent les pages fraîches. Si votre sitemap dit que tout a été modifié aujourd'hui, ils ne vous croient pas. S'il indique des dates réelles, ils vous crawlent à la bonne fréquence. - HTML sémantique:
<article>,<section>,<header>,<main>,<aside>. Cela sonne basique mais beaucoup de sites utilisent<div>pour tout. Les LLM traitent mieux une structure sémantique qu'une<div>-soup.
Audit de citabilité : checklist en 10 points
Dix critères actionnables pour auto-évaluer si votre site est GEO-ready. Chacun ajoute ou retire une probabilité d'être cité. Auditez un par un avec votre domaine en tête.
- Avez-vous
/llms.txtpublié et accessible publiquement ? Si la réponse est non, c'est la première étape. - La première phrase de votre home répond-elle à « que fait X » en moins de 30 mots ? Si vous avez besoin de 200 mots, le LLM ne vous citera pas ici.
- Votre
robots.txta-t-il des règles explicites pour les AI crawlers ? Pas de règles implicites. Explicites. Les bots lisent ce qui est écrit. - Votre blog a-t-il du JSON-LD
Articledans chaque article ? Si non, les modèles doivent inférer auteur et date. Inférence = perte de confiance. - Vos FAQ sont-elles marquées avec
FAQPageschema ? Si votre FAQ est du texte brut sans schema, les LLM la traitent, mais ils perdent la structure question-réponse qui est idéale pour la citer. - Votre contenu pillar fait-il plus de 3 000 mots avec des headers H2/H3 logiques et des données concrètes ? Les LLM ne citent pas les articles génériques de 500 mots. Ils citent l'exhaustivité.
- Mentionnez-vous des chiffres propres, des cas avec nom et des métriques vérifiables ? « Nous avons augmenté les ventes de X % » sans contexte n'est pas cité. « Le client Y est passé de 1 % à 3 % de conversion en 6 mois avec AsisteClick » est cité.
- Votre site charge-t-il sans JS lourd ? Certains modèles font du retrieval avec des moteurs qui exécutent du JS, d'autres non. Si votre contenu est derrière un render JS, le contenu invisible au
curlest invisible au LLM dans de nombreux cas. - Votre marque est-elle mentionnée sur des sites autoritatifs de votre vertical (médias, partenaires, agrégateurs) ? Les citations croisées sont la monnaie d'autorité pour les LLM, tout comme les backlinks le sont pour Google.
- Avez-vous un protocole d'actualisation de contenu ? Les articles avec
dateModifieddatant de deux ans perdent du poids. Rafraîchir les pillar tous les 6-12 mois fait partie du travail.
Si vous cochez 8 ou plus, vous êtes au premier rang des marques GEO-ready de votre vertical en LATAM. Si vous cochez 4-7, il y a un travail clair devant vous. Si vous cochez moins de 4, l'upside d'investir dans le GEO maintenant est énorme : chaque pas compte.

Comment mesurer si ça fonctionne
Soyons honnêtes : la mesure GEO en 2026 est encore en formation. Il n'existe pas de Search Console pour les LLM. Ce qui existe, ce sont trois types de signaux qui, combinés, vous donnent un panorama utile.
Signal 1 : referrals dans GA4. Configurez GA4 pour détecter les referrals depuis chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Quand un utilisateur clique sur une citation qu'un LLM a mise dans sa réponse, ce trafic arrive sur votre site avec ces referrers. C'est la métrique la plus directe de citations avec conversion.
Dans GA4, créez un canal personnalisé « AI Referrals » avec ces domaines. Si vous partez de zéro, le volume sera bas (les LLM citent encore peu avec des clics). Mais la tendance compte plus que le chiffre absolu. S'il passe de 5 sessions/mois à 50/mois en six mois, vous êtes sur la bonne voie. S'il reste à zéro, il y a un problème de citabilité.
Signal 2 : Google Search Console pour les requêtes naturelles. Aussi contre-intuitif que cela puisse paraître, GSC reste utile pour le GEO. Pourquoi ? Parce que les requêtes qui y apparaissent — « qu'est-ce que X », « comment fonctionne Y », « différences entre A et B » — sont exactement les requêtes que les gens posent à un LLM. Si votre site apparaît pour ces requêtes sur Google, il y a une forte probabilité qu'il apparaisse aussi dans les LLM. GSC est votre proxy d'« intent conversationnel couvert ».
Filtrez dans GSC les requêtes qui commencent par « qu'est-ce que », « comment », « quel », « pourquoi », « quand ». Ce sont vos requêtes conversationnelles. Le volume et le ranking là-dessus vous indiquent votre position concurrentielle sur l'intent conversationnel, qui se transfère partiellement au GEO.
Signal 3 : tests manuels systématiques. Une fois par mois, faites le protocole suivant :
- Liste de 10-20 questions qu'un client potentiel poserait à un LLM sur votre catégorie (pas sur votre marque : sur la catégorie).
- Posez-les à ChatGPT (avec recherche activée), Perplexity, Claude, Gemini.
- Notez : vous mentionnent-ils ? Comment ? Avec lien ou sans lien ? Avant, pendant ou après les concurrents ? La description qu'ils donnent de vous est-elle celle que vous voulez ?
- Comparez mois par mois.
C'est un travail manuel, mais jusqu'à ce que les outils de monitoring automatisé mûrissent, c'est la méthode la plus fiable. Il existe des outils commerciaux émergents — Otterly, BrandRanker, Profound, HubSpot AI Search Grader, AthenaHQ — qui automatisent une partie de cela. Cela vaut la peine de les évaluer si votre vertical est concurrentiel. La plupart commencent avec des plans gratuits ou à faible coût pour tracker quelques marques/requêtes.
Signal 4 (avancé) : logs du serveur. Les crawlers d'IA laissent leur user-agent dans vos logs. Filtrez par GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot. La fréquence à laquelle ils vous visitent est un indicateur avancé : s'ils visitent peu, ils vous découvrent peu. S'ils visitent beaucoup, il y a un intérêt du modèle pour votre contenu. C'est un proxy bruyant mais utile.
Cas AsisteClick : ce que nous avons fait
Notre implémentation GEO a commencé en mars 2026, dans le contexte plus large de la migration du site asisteclick.com depuis WordPress vers Astro (un changement qui a sa propre histoire, mais qui a ouvert l'opportunité de traiter le GEO comme partie du design technique dès le début plutôt qu'en bolt-on après coup).
Le stack actuel, tout public et vérifiable :
asisteclick.com/llms.txt— 22 939 octets. Résumé exécutif + 10 produits + 7 canaux + pricing + 11 verticaux + 5 intégrations + 32 articles du blog + 7 études de cas. Markdown brut, généré automatiquement depuis les métadonnées du site.asisteclick.com/llms-full.txt— 1 003 695 octets (~1 Mo). Contenu complet des landings clés et des articles pillar du blog, concaténés en markdown sans bloat. Pour les modèles avec grande fenêtre de contexte qui veulent approfondir.asisteclick.com/robots.txt— politique ALLOW ALL explicite pour plus de 20 user agents d'IA. Commentaire inline qui documente la décision et garde la logique auditable.- JSON-LD
Article+FAQPage+BreadcrumbListdans les 30+ articles du blog, généré au build time depuis le meta de chaque article. - JSON-LD
Organizationsur la home avec des infos structurées de l'entreprise. - Sitemap XML avec
lastmodréel et hreflang multi-langue (es/en/fr/pt).
Derrière le stack, il y a un skill propre (/ai-seo) qui automatise la régénération du llms.txt y llms-full.txt chaque fois qu'un nouvel article est publié ou qu'une landing est modifiée. C'est important parce que la maintenabilité est l'endroit où le GEO échoue habituellement : les llms.txt qui sont obsolètes trois mois après publication sont la règle, pas l'exception.
Des résultats ? Voici la partie honnête : nous avons peu de mois de tracking, donc les chiffres sont préliminaires. Nous voyons une croissance des referrals depuis chat.openai.com y perplexity.ai dans GA4 (de zéro à quelques sessions par semaine), une augmentation des requêtes conversationnelles dans GSC (impressions pour « qu'est-ce qu'un Agent IA », « comment choisir un chatbot whatsapp », etc.), et des améliorations anecdotiques dans les tests manuels : ChatGPT a commencé à nous mentionner quand on lui demande des « plateformes WhatsApp Business pour PME en LATAM », ce qu'il ne faisait pas en janvier. Ce n'est pas une preuve à l'échelle. C'est une preuve de méthode. La conclusion solide, nous pourrons la donner fin 2026 avec deux trimestres supplémentaires de data.
La méthode est reproductible indépendamment de nos chiffres. L'investissement en heures : une semaine d'un dev pour implémenter le stack de base, plus une routine mensuelle d'audit (4 heures) et la maintenance du llms.txt (1 heure par nouvelle publication).
Anti-patterns : ce qui ne fonctionne pas en GEO
L'autre côté de la checklist : erreurs qui se commettent fréquemment et qui réduisent activement votre probabilité d'être cité.
1. Keyword stuffing adapté. Certains sites construisent leur llms.txt avec des listes de mots-clés et de variantes (« chatbot WhatsApp, chat bot whatsapp, chatbot wapp, bot WhatsApp... »). Les LLM détectent le pattern et dévaluent. Le standard Howard est du markdown avec des descriptions naturelles, pas des listes de mots-clés. Si votre llms.txt ressemble à un dump d'Ahrefs, vous le faites mal.
2. Contenu IA-sur-IA sans angle. Le sujet GEO va exploser cette année. Vous allez voir une avalanche d'articles génériques sur « comment apparaître dans ChatGPT » écrits par IA sans vérification, répétant les quatre mêmes conseils. Ces articles ne sont pas citables parce qu'ils n'apportent pas d'information nouvelle. Si vous écrivez sur le GEO, faites-le avec un angle propre (cas, donnée, vertical spécifique).
3. Paywall sur le contenu pillar. Si votre meilleur contenu est derrière un login ou un paywall, les crawlers d'IA ne le lisent pas. Il y a un débat légitime sur la quantité à libérer gratuitement, mais stratégiquement, le pillar content que vous voulez que ChatGPT cite doit être public.
4. Rendering JavaScript-heavy. Si votre site rend le contenu principal avec du JS et qu'un crawler basique ne le voit pas, ça dépend du bot de le traiter ou non. GPTBot y ClaudeBot n'exécutent pas le JS dans tous les cas. Le server-side rendering ou la static generation est plus sûr.
5. Hidden content pour les LLM (« cloaking »). Certains testent de servir un contenu différent aux humains vs aux LLM (texte supplémentaire invisible pour les humains mais parseable par les crawlers). C'est la version 2026 du black-hat SEO et cela va finir pénalisé comme le cloaking des années 2010. Ne le faites pas.
6. Listicles génériques sans substance. « 10 meilleures plateformes de X », « 7 outils pour Y » sans critères clairs et sans différenciateurs. Les LLM les lisent mais ne les citent pas : il existe une infinité de listes comme celles-là. Ce qui est cité, c'est l'analyse avec critères et données.
7. Information périmée sans marquage de date. Articles de 2022 sans dateModified à jour, parlant de prix et de features qui ont changé. Les modèles modernes vérifient dateModified. S'il n'y en a pas, ils assument le worst case.
8. Ton robotique généré. Curieusement, le contenu généré par IA sans édition humaine a moins de chances d'être cité par l'IA. Les modèles détectent le pattern et dévaluent. Le paradoxe est réel : pour que l'IA vous cite, vous devez sonner humain.
Cinq pas actionnables cette semaine
Si vous voulez démarrer sans attendre, voici l'ordre minimum viable :
Jour 1 — Publiez votre /llms.txt. Une heure de travail. Prenez votre home, décomposez-la en blocs (produits, services, ressources), écrivez une ligne de blockquote qui dit ce que fait votre entreprise, listez les URL principales avec une description d'une ligne. Téléversez-le à la racine du domaine. Si vous avez WordPress, vous pouvez le générer avec un plugin (LlmsTxt, AI SEO ou similaire) ou le téléverser manuellement.
Jour 2 — Mettez à jour votre robots.txt. Trente minutes. Décidez votre politique (ALLOW ALL, block training, mixte) et écrivez les règles explicites pour les 15+ user-agents listés plus haut. Testez-le avec curl https://tudominio.com/robots.txt pour confirmer qu'il est servi.
Jour 3 — Auditez votre Schema.org. Une heure. Utilisez le Schema Validator de Google pour voir quel JSON-LD vous avez dans votre home, dans un article du blog et dans une landing produit. S'il manque Organization, Article o FAQPage, ajoutez-le. Si votre site est WordPress, il y a des plugins (RankMath, Yoast, SchemaPro) qui l'automatisent.
Jour 4 — Configurez GA4 pour les AI Referrals. Trente minutes. Dans GA4, créez une vue « AI Referrals » avec les domaines d'origine chat.openai.com, chatgpt.com, perplexity.ai, claude.ai, gemini.google.com. Commencez à tracker dès aujourd'hui pour avoir une baseline.
Jour 5 — Test manuel systématique. Une heure. Écrivez 10 questions qu'un client potentiel poserait à un LLM sur votre catégorie. Posez-les dans ChatGPT, Perplexity, Claude. Notez qui vous mentionne, comment, dans quel ordre. Sauvegardez les screenshots. Répétez dans 30 jours pour mesurer le progrès.
Avec ces cinq pas en une semaine, vous êtes dans le premier quartile des marques qui font du GEO avec sérieux en LATAM en 2026. Ce qui suit (maintenir le llms.txt, rafraîchir le contenu pillar, monitorer les referrals, itérer le stack) est de l'opérationnel continu. Mais la base se construit en cinq jours.
Si votre équipe est marketing mais pas tech, et que vous avez besoin d'un partenaire qui se charge du stack technique et de l'opérationnel de contenu conversationnel optimisé pour les LLM (pas seulement du SEO), chez AsisteClick nous offrons une implémentation clé en main de cette couche GEO pour les clients existants et nouveaux. La différence avec un freelance SEO générique : notre équipe a construit le stack pour notre propre site et le maintient comme un produit en production.
Questions fréquentes
Qu'est-ce que la Generative Engine Optimization (GEO) ?
Le GEO est l'ensemble des pratiques techniques et éditoriales qui augmentent la probabilité que votre marque, produit ou contenu soit mentionné par les moteurs de recherche générative comme ChatGPT, Perplexity, Claude ou Gemini lorsqu'un utilisateur fait une requête liée. Cela ne remplace pas le SEO classique : cela le complète, en optimisant pour une unité de succès différente (citation dans une réponse synthétisée au lieu de position dans le SERP).
Le GEO est-il la même chose que l'AEO (Answer Engine Optimization) ?
Ce sont des termes proches avec des nuances. L'AEO est apparu avant et faisait davantage référence à l'apparition dans les « answer boxes » et featured snippets de Google. Le GEO est plus large : il inclut les moteurs génératifs (LLM) qui produisent des réponses synthétisées avec ou sans recherche en temps réel. En pratique, beaucoup de contenu se chevauche. AIO (« AI Optimization ») est un troisième terme en usage. À des fins pratiques, GEO est le plus utilisé en 2026 et couvre tout le spectre.
Combien de temps faut-il pour voir un résultat GEO ?
Les effets de retrieval (citation dans les réponses que le modèle cherche en direct, comme Perplexity ou ChatGPT Search) se voient en quelques semaines : si vous publiez llms.txt, mettez à jour robots.txt et améliorez la structure, les crawlers d'IA découvrent le changement en 1-4 semaines. Les effets de training (que votre marque soit mieux représentée dans le prochain modèle) se voient en mois, car ils dépendent de quand la prochaine version du LLM est entraînée. Délai raisonnable pour mesurer le GEO avec sérieux : 6 mois minimum.
Dois-je désindexer de Google si je publie llms.txt ?
Non. llms.txt n'affecte pas votre indexation sur Google. Ce sont des systèmes indépendants. Google ignore llms.txt (ce n'est pas un standard qu'il utilise), et les crawlers d'IA lisent llms.txt en plus de votre site normal. Faire du GEO n'implique pas de sacrifier le SEO ; au contraire, ils sont synergiques.
Comment savoir si ChatGPT ou Perplexity citent déjà ma marque ?
Trois méthodes : (1) test manuel — posez des questions sur votre catégorie dans chaque moteur et notez s'ils vous mentionnent ; (2) referrals dans GA4 depuis des domaines comme chat.openai.com y perplexity.ai ; (3) outils de monitoring commercial (Otterly, BrandRanker, Profound) qui trackent automatiquement les mentions de marque dans les LLM. Le test manuel est gratuit et suffisant pour démarrer. Les outils sont utiles quand votre vertical est concurrentiel et que vous avez besoin d'un suivi continu.
Bloquer les bots de training me bénéficie ou me nuit ?
Cela dépend de votre modèle d'affaires. Si votre contenu est propriétaire et monétisé (médias, paywall, base de données), bloquer le training peut avoir du sens pour ne pas « offrir » le corpus au prochain modèle. Si votre contenu est marketing et que vous voulez une visibilité maximale, il convient de tout autoriser. Une politique mixte courante : autoriser les retrieval bots (qui peuvent vous citer en temps réel avec lien) et bloquer les training bots (qui ingèrent votre contenu pour entraîner le prochain modèle). Chaque entreprise décide selon ses priorités.
Existe-t-il une plateforme qui combine service client et présence dans les LLM ?
Aujourd'hui ce sont des couches séparées : le GEO se gère depuis votre site (llms.txt, schema, contenu), et le service client avec IA se gère depuis une plateforme comme AsisteClick qui intègre WhatsApp, web, Instagram et CRM avec des Agents IA propres. Ce que vous partagez entre les deux, c'est la base de connaissances : le contenu que ChatGPT cite pour répondre pour vous en général, et le contenu que votre propre Agent IA utilise pour répondre aux clients sur WhatsApp, idéalement, viennent du même corpus curé. Construire cette base une seule fois et l'utiliser sur les deux canaux est la prochaine frontière d'efficacité pour les équipes marketing et customer experience.